火山引擎 ByteHouse:TB 级数据下,如何实现高效、稳定的数据导入
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近期,火山引擎开发者社区、火山引擎数智平台(VeDI)联合举办以《数智化转型背景下的火山引擎大数据技术揭秘》为主题的线下 Meeup。活动主要从数据分析、数据治理、研发提效等角度,带领数据领域从业者全面了解数智化转型背景下的火山引擎数据飞轮模式在数据资产建设上的技术与实践。其中,火山引擎 ByteHouse 产品专家受邀到现场,发表主题为《基于 ByteHouse 引擎的增强型数据导入技术实践》的分享。
数据导入是衡量 OLAP 引擎性能及易用性的重要标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。作为一款 OLAP 引擎,火山引擎云原生数据仓库 ByteHouse 源于开源 ClickHouse,在字节跳动多年打磨下,提供更丰富的能力和更强性能,能为用户带来极速分析体验,支撑实时数据分析和海量离线数据分析,具备便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性。
随着 ByteHouse 内外部用户规模不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 ByteHouse 的数据导入能力带来了更大的挑战。
从字节跳动内部来看,ByteHouse 主要以 Kafka 为实时导入的主要数据源。对于大部分内部用户而言,其数据体量偏大,用户更看重数据导入的性能、服务的稳定性以及导入能力的可扩展性。在数据延时性方面,用户的需求一般为秒级左右。
据火山引擎 ByteHouse 产品专家的介绍,基于以上场景和需求,ByteHouse 首先基于 ClickHouse 引擎进行升级,其次又针对数据导入能力进行一系列定制性优化,主要包括两个方面,第一为 MaterializedMySQL 增强;第二个是 HaKafka 引擎。

在引擎优化方面,在 TB 级数据量级下,ClickHouse 容易出现集群故障,还存在读性能较低、耗损内存的问题。针对这些痛点,ByteHouse 自研的 HaMergeTree 和 HaUniqueMergeTree 可以降低负载,确保集群在单节点故障下能平稳运行服务,还能平衡读写性能,保障读取时性能一致。
在数据导入能力的定制化优化方面,社区版 MaterializedMySQL 不支持分布式表等功能,也存在无法定位问题、无法同步状态等运维问题。一方面,通过构建分布式模式的 MaterializedMySQL 库,用户可将每个表都对应同步至 ByteHouse 的一个分布式表,让数据不重复存储,充分利用分布式集群的计算能力,又降低了对源端的同步压力。另一方面,ByteHouse 也提供可视化运维的功能,支持同步状态和任务管理,一旦出现系统运维故障,用户会收到异常警告。
而 HaKafka 引擎则是 ByteHouse 推出的一种特殊的表引擎,主要基于 ClickHouse 社区的 Kafka engine 进行了优化。用户可以通过一个 Kafka 消费表、分布式存储表、物化视图表,三元组实现数据消费、数据转换、数据写入功能。
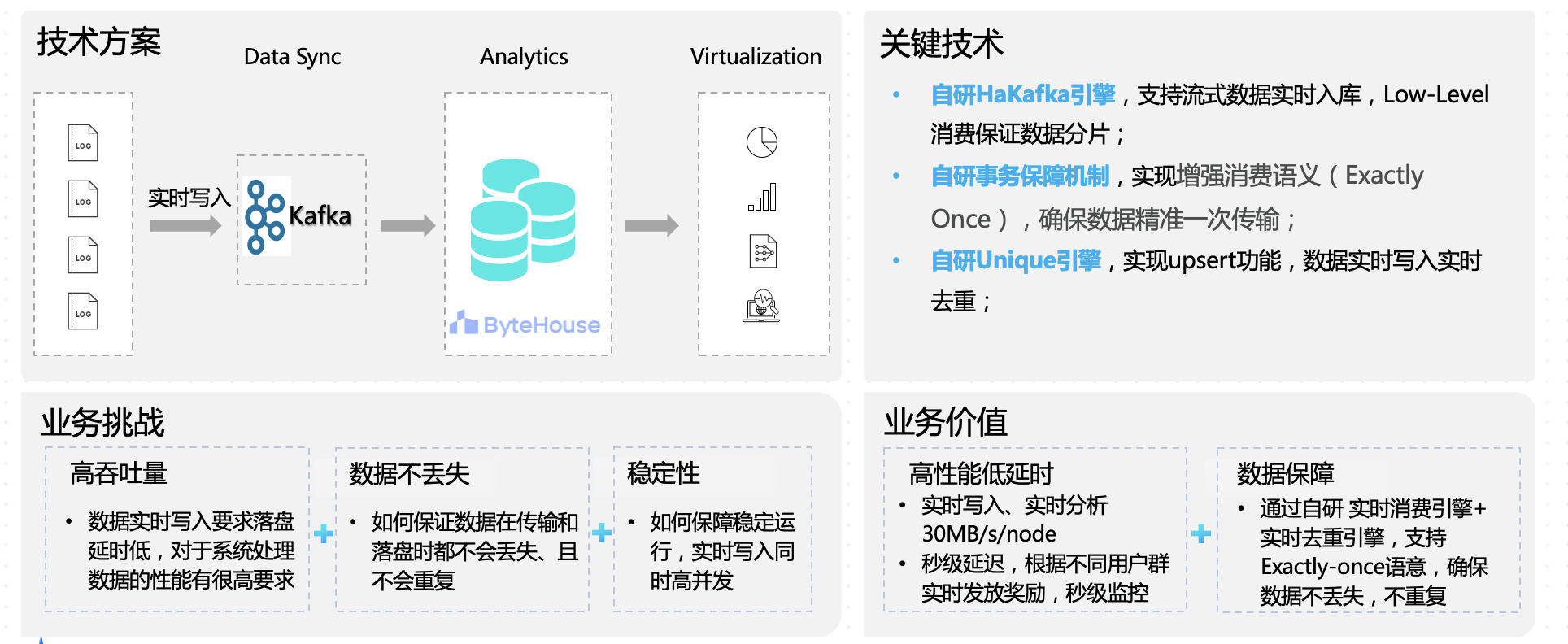
目前,以上能力已经在短视频、营销实时数据监控、游戏广告数据分析等领域落地。以营销实时数据监控为例,活动的主办方需要对营销活动效果进行实时监控,以便通过实时奖励发放来动态调整奖励流量分配,提升 ROI 收益。这类场景要求数据实时写入,对系统性能具备高要求 。另外,为保障奖励不会发放错误,也需要保证数据在传输和落盘时都不丢失、不重复,且稳定运行。
ByteHouse 基于自研 HaKafka 引擎,能支持流式数据实时入库, 用自研事务保障机制,确保数据精准一次传输,最后通过自研 Unique 引擎实现数据实时写入实时去重。在效果上实现实时写入、实时分析 30MB/s/node,业务可以根据不同用户群实时发放奖励,做到秒级延迟、秒级监控。
点击跳转 云原生数据仓库ByteHouse 了解更多
火山引擎 ByteHouse:TB 级数据下,如何实现高效、稳定的数据导入的更多相关文章
- 高性能、快响应!火山引擎 ByteHouse 物化视图功能及入门介绍
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 物化视图是指将视图的计算结果存储在数据库中的一种技术.当用户执行查询时,数据库会直接从已经预计算好的结果中获取数据 ...
- mysql重复数据下,删除一条重复数据
delete from information where id in (select id from (select max(id) as id,count(*) as ccc from infor ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 亿级用户下的新浪微博平台架构 前端机(提供 API 接口服务),队列机(处理上行业务逻辑,主要是数据写入),存储(mc、mysql、mcq、redis 、HBase等)
https://mp.weixin.qq.com/s/f319mm6QsetwxntvSXpKxg 亿级用户下的新浪微博平台架构 炼数成金前沿推荐 2014-12-04 序言 新浪微博在2014年3月 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 大数据下的数据分析平台架构zz
转自http://www.cnblogs.com/end/archive/2012/02/05/2339152.html 随着互联网.移动互联网和物联网的发展,谁也无法否认,我们已经切实地迎来了一个海 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
随机推荐
- P1182 数列分段 Section II 题解
Problem 考察知识点:二分.贪心. 题目描述 对于给定的一个数组,现要将其分成 \(M\) 段,并要求每段连续,且每段和的最大值最小. 思路 二分答案出每段和最大值的最小值,然后贪心检验是否满足 ...
- Java模块化应用实践之精简JRE(内含开源)
导语 Java9及以后的版本引入了模块化特性,但是直到今天JDK21都发布了,依然没有被大量使用起来,那么这个特性就真的没啥意义了吗? 别忘了,Java本身可是把模块化做到了极致的,所以可以利用这个特 ...
- Util应用框架核心(三) - 服务注册器
本节介绍服务注册器的开发. 如果你不需要扩展Util应用框架,直接跳过. 当你把某些功能封装到自己的类库,并希望启动时自动执行初始化代码进行配置时,定义服务注册器. 服务注册器概述 服务注册器是Uti ...
- 字符串匹配算法:KMP
Knuth–Morris–Pratt(KMP)是由三位数学家克努斯.莫里斯.普拉特同时发现,所有人们用三个人的名字来称呼这种算法,KMP是一种改进的字符串匹配算法,它的核心是利用匹配失败后的信息,尽量 ...
- CF1559D1. Mocha and Diana (Easy Version)
原题链接:1559D1. Mocha and Diana (Easy Version) 题意: 小明和小红各有一个具有\(n\)个结点的森林,现执行操作: 加一条边,使得两人的森林还是森林 小明加一条 ...
- python之继承及其实现方法
目录 继承 语法格式 继承的代码实现 多继承 继承 语法格式 class 子类类名(父类1, 父类2...): pass r如果一个类没有继承任何类,则默认继承object python支持多继承 定 ...
- VM离线安装Centos 8以及配置
一.安装 1.预装准备 1.1. 硬件准备 物理内存:2G以上(这里指系统搭建所需占用空间) 物理外存:20G(这里指系统搭建所需占用空间) 1.2. 环境搭建准备 Window10系统电脑一台.Vm ...
- charles谷歌浏览器抓包方法
charles谷歌浏览器抓包方法 在工作中,我们会在PC电脑上测试页面,查看后端接口,我们会选择浏览器F12的功能来查看后端请求的接口,那我们能不能用charles抓包工具去抓呢?下面简答介绍一下ch ...
- [USACO2007FEB S] The Cow Lexicon S
题目描述 Few know that the cows have their own dictionary with W (1 ≤ W ≤ 600) words, each containing no ...
- Chat2DB接入文心一言AI教程(原创教程,转载请注明)
引言 关于Chat2DB和文心一言是啥我就不赘述了,由于Chat2DB自带的ai有调用次数限制,所以想着接入百度的文心AI,但是由于网上没有找到相关的教程,此教程是本人研究了很久才弄出来的,顺便记录一 ...