一文讲述数仓组件SysCache
摘要:SysCache是ThreadLocal结构,每个线程都具有各自的SysCache,其中存储的缓存信息由执行的业务决定。
本文分享自华为云社区《GaussDB(DWS)CBB组件之SysCache原理介绍》,作者:疯狂朔朔。
SysCache是什么?我们为什么需要SysCache?
在说明这个问题之前,我们需要简单说明一下GaussDB(DWS)的基本工作原理。
在我们链接数据库后,数据库将在后台为我们分配一根单独的线程,该线程负责执行我们发送的请求,假设我们按顺序发送以下语句:
- create table abc (a int, b int, c int);
- insert into abc values (1, 2, 3);
- insert into abc values (2, 3, 4);
- insert into abc values (3, 4, 5);
在创建表abc后,连续向abc中插入了3条数据,每条插入语句均需要访问abc的元数据,包括但不仅限于:
- pg_authid:读取用户相关信息,
- pg_resource_pool:读取资源池相关信息,
- pg_class:读取表相关元数据,
- pgxc_group:读取nodegroup相关信息,
- pg_namespace:读取schema相关信息,
- pg_type:读取字段类型,
- pg_attribute:读取表列属性信息。
可见,虽然简单执行了一条insert语句,其中涉及到的解析、校验逻辑是异常复杂的,会关联大量系统表相关查询操作。为了加快系统表查询速率,GaussDB(DWS)中针对系统表查询操作构建了SysCache缓存,以加速系统表查询速率。在上述例子中,语句b)在执行时,会访问相关系统表元数据,并通过SysCache进行缓存,之后在语句c)和语句d)执行时,直接从SysCache获取相应的缓存信息,以加速执行效率。
- NOTE:实际上,GaussDB(DWS)中SysCache与PG的SysCache原理一致,不同之处在于,GaussDB(DWS)做了线程化改造,将PG多进程模型改为多线程模型。
- NOTE:一句话解释SysCache,SysCache是GaussDB(DWS)内核系统表Tuple高速缓存。
SysCache存储结构
SysCache是ThreadLocal结构,每个线程都具有各自的SysCache,其中存储的缓存信息由执行的业务决定。下图展示了SysCache的大体结构:
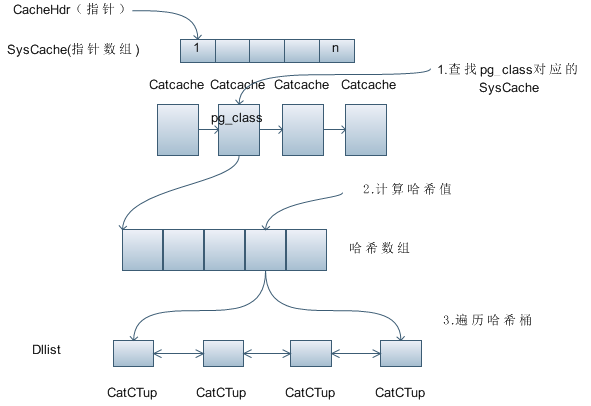
图1 SysCache结构
SysCache在内存中以指针数组的形式进行存储,数组中每个元素均为一个CatCache结构体,CatCache中存储了系统表中的元数据信息。在CatCache中可能存在大量被缓存的数据,为加速查找,CatCache中设计了哈希数组,哈希数组包含多个哈希桶,每个哈希桶中记录了元数据链表信息,最终元数据是以双向链表的形式存于哈希桶中的。
以一个例子进行说明:假设执行以下语句:
select * from public.abc;
系统在执行该语句时,在SysCache中会经历以下三步:
- 查找pg_class对应的CatCache:该语句的输入参数有三个,从pg_class查询Schema名为public,表名为abc的元数据信息。因此,执行该语句时,会直接查询pg_class对应的CatCache。
- 计算哈希值:通过输入参数public和abc计算其对应的哈希值,定位哈希桶的位置。
- 遍历哈希桶:遍历哈希桶中元数据信息,若匹配到public.abc的元数据,则直接返回该数据,若未匹配到,则需要进一步扫描pg_class,以读取元数据信息。
- NOTE:一句话解释SysCache存储结构:SysCache存储结构本质上是多个哈希桶,每个哈希桶中元数据是以双向链表的形式进行存储。
SysCache对外接口
SysCache对外接口主要包括两个:
查询SysCache和释放SysCache,这两个方法需要配对使用,在SysCache返回查询结果后,需要再次调用释放SysCache接口,以释放SysCache相关数据。
下图展示了查询SysCache的主要步骤:
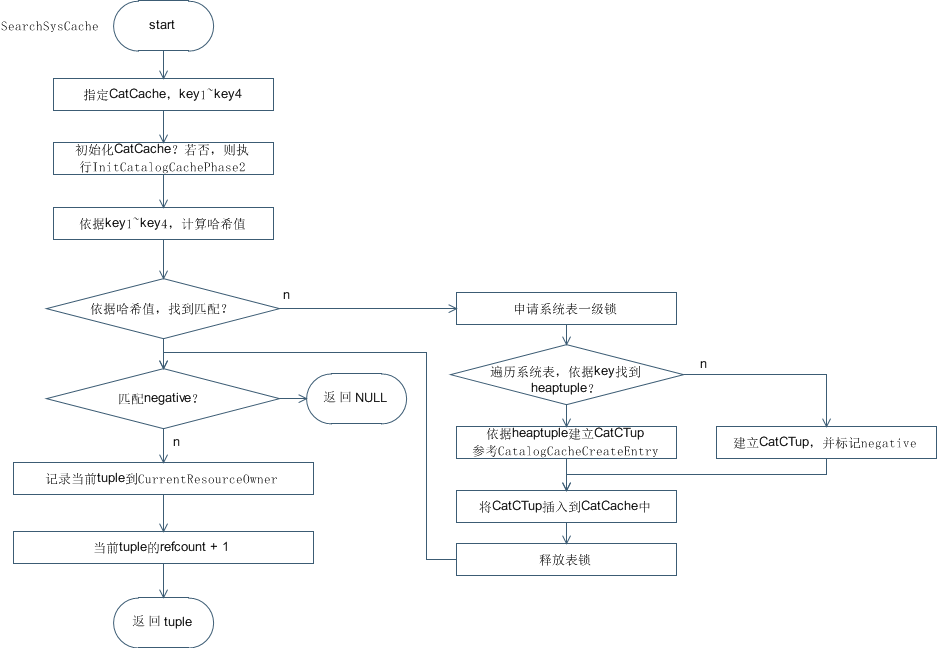
图2 查询SysCache流程图
在查询SysCache前,需要确保CatCache初始化,之后,需要依据查询的key信息计算哈希值,以定位哈希桶位置。对于SysCache而言,数据的key最多为4个,在上述例子中,key1=public,key2=abc,key3和key4将以0进行补全。
计算哈希值之后,将扫描对应哈希桶中的双向链表,逐个进行匹配,若未匹配到,将进一步扫描该系统表的数据页。若数据页中也没有该数据,则说明不存在该数据,需要建立一个假的CatCTup,并标记为negative,以提升查询miss效率,若数据页中包含该数据,则将该条数据进行封装,建立CatCTup,并插入到对应的哈希桶中。
在匹配到CatCTup后,需要将当前CatCTup的引用数量refcount加一,并进行返回,refcount的作用是计数引用,以防止被错误释放。
对于释放SysCache,其主要步骤是将引用数量refcount减一,并释放refcount为0的资源。
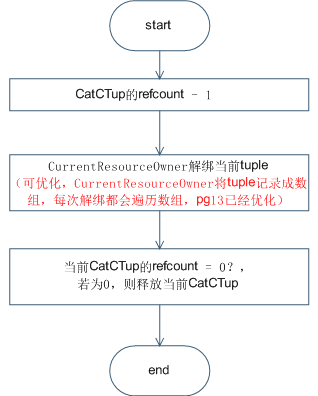
图3 释放SysCache流程图
- NOTE:在查询SysCache和释放SysCache的过程中,会将当前匹配的tuple与CurrentResourceOwner进行绑定,该操作的主要目的是在线程退出或者事务提交时进行资源泄漏的校验。
- NOTE:SysCache支持模糊查询,接口为SearchCatCacheList,有兴趣的小伙伴可自行百度,本问只以最简单的情况进行介绍。
SysCache失效机制
在解释SysCache失效之前,需要先解释一下SysCache为什么需要失效。我们说过,SysCache为ThreadLocal结构,假设线程1在SysCache中缓存了表abc的元数据,而线程2删除了表abc,那么线程1中abc的元数据需要进行失效处理,GaussDB(DWS)中SysCache失效机制主要通过失效消息队列实现。
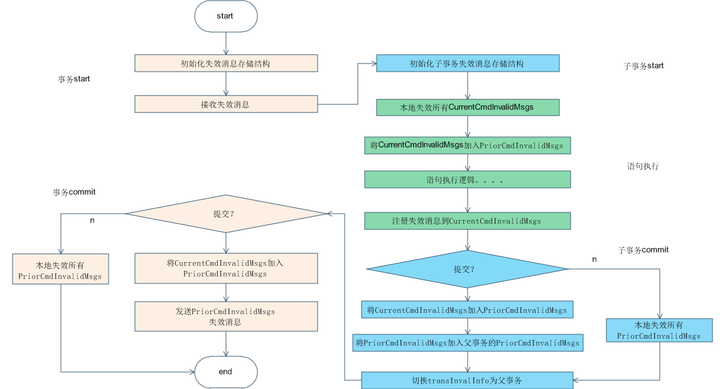
图4 SysCache失效机制
我们以一个简单例子进行说明,上图为语句执行过程中,SysCache失效消息发送流程图。
在事务开始时,本线程将主动接收并处理失效消息队列中的消息。在开启子事务时,会初始化失效消息存储结构,主要包括两部分结构,CurrnetCmdInvalidMsgs(当前失效消息),主要存储当前执行语句产生的失效消息,PriorCmdInvalidMsgs(历史失效消息),主要用于存储从事务开启到当前时间点,产生的失效消息,其中CurrnetCmdInvalidMsgs和PriorCmdInvalidMsgs均为ThreadLocal结构。
在每个语句执行前,会将前一个语句的失效消息从CurrnetCmdInvalidMsgs移动到PriorCmdInvalidMsgs。之后在语句执行完毕以后,将失效消息加入到CurrnetCmdInvalidMsgs。
在子事务提交时,分为两种情况,若事务rollback,则需要失效本地所有的PriorCmdInvalidMsgs。若事务提交,则需要将子事务的PriorCmdInvalidMsgs和CurrnetCmdInvalidMsgs加入到父事务的PriorCmdInvalidMsgs中,并将当前事务信息切换为父事务环境。
在父事务提交时,同样分为两种情况,若事务rollback,则需要失效本地所有的PriorCmdInvalidMsgs。若事务提交,则需要向失效消息队列提交该线程产生的全部失效消息。
- NOTE:一句话解释SysCache失效机制,内核在事务提交成功时会主动将本线程产生的失效消息提交到失效消息队列,供其他线程同步。
- NOTE:此处并未详细解释失效消息队列相关内容,大家可将失效消息队列当作黑盒,失效消息队列对外提供失效消息提交和读取接口,用于失效消息同步,后续文章会详细介绍失效消息队列相关内容。
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料~
一文讲述数仓组件SysCache的更多相关文章
- 数仓建设 | ODS、DWD、DWM等理论实战(好文收藏)
本文目录: 一.数据流向 二.应用示例 三.何为数仓DW 四.为何要分层 五.数据分层 六.数据集市 七.问题总结 导读 数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需 ...
- 【大数据-课程】高途-天翼云侯圣文-Day2:离线数仓搭建分解
一.内容介绍 昨日福利:大数据反杀熟 今日:数据看板 离线分析及DW数据仓库 明日:实时计算框架及全流程 一.数仓定义及演进史 1.概念 生活中解答 2.数据仓库的理解 对比商品仓库 3.数仓分层内容 ...
- 文盘Rust -- rust 连接云上数仓 starwift
作者:京东云 贾世闻 最近想看看 rust 如何集成 clickhouse,又犯了好吃懒做的心理(不想自己建环境),刚好京东云发布了兼容ck 的云原生数仓 Starwfit,于是搞了个实例折腾一番. ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- 在HUE中将文本格式的数据导入hive数仓中
今天有一个需求需要将一份文档形式的hft与fdd的城市关系关系的数据导入到hive数仓中,之前没有在hue中进行这项操作(上家都是通过xshell登录堡垒机直接连服务器进行操作的),特此记录一下. - ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- Greenplum数仓监控解决方案(开源版本)
Greenplum监控解决方案 基于Prometheus+Grafana+greenplum_exporter+node_exporter实现 关联图 一.基本概念 1.Prometheus Pr ...
随机推荐
- 万字解析XML配置映射为BeanDefinition的源码
本文分享自华为云社区<Spring高手之路16--解析XML配置映射为BeanDefinition的源码>,作者:砖业洋__. 1. BeanDefinition阶段的分析 Spring框 ...
- Codeforces Round #697 (Div. 3) A~E题解
写在前边 状态及其不佳,很累很困,还好\(unrated\)了 链接:Codeforces Round #697 (Div. 3) A. Odd Divisor 链接:A题链接 题目大意: 判断一个数 ...
- P5318 查阅文献
题意大概意思就是分别用dfs与bfs遍历一个图,特殊要求是从编号小的点开始遍历. 用邻接表存图,至今我也没想明白怎么才可以从编号小的点开始遍历,明白是排序,但是不知道如何排序,题解中的排序方法是:按照 ...
- 平稳扩展:可支持RevenueCat每日12亿次API请求的缓存
平稳扩展:可支持RevenueCat每日12亿次API请求的缓存 目录 平稳扩展:可支持RevenueCat每日12亿次API请求的缓存 低延迟 建立连接池 故障检测 Up and warm 对故障做 ...
- 一次显著的性能提升,从8s到0.7s
前言 最近我在公司优化了一些慢查询SQL,积累了一些SQL调优的实战经验. 我之前写过一些SQL优化相关的文章<聊聊SQL优化的15个小技巧>和<explain | 索引优化的这把绝 ...
- AtCoder_abc328
A - Not Too Hard 题目链接 题目大意 给出\(N\)个数(\(S_1\) \(S_2\)...\(S_n\))和一个\(X\),输出所有小于等于\(X\)的\(S_i\)之和 解题思路 ...
- unsafe类和varhandle类讲解
Java的Unsafe类是一个非常特殊的类,它提供了一组原始.底层的操作,可以跳过Java的限制,直接操作内存和对象.这些操作可能会破坏Java的安全机制,所以Unsafe类被标记为不安全的. Uns ...
- java制作游戏,如何使用libgdx,入门级别教学
第一步,进入libgdx的官网.点击get started 进入这个页面,点击setup a project 进入这个页面直接点击,Generate a project. 点击下载,下载创建工具 它会 ...
- AtomicArray
AtomicInteger ai = new AtomicInteger(1); //1.获取值 System.out.println("ai.get = "+ai.get()); ...
- DI入门案例
1.基于IoC管理bean 2.Service中使用new形式创建的Dao对象是否保留?(不保留) 3.Service中需要的Dao对象如何进入到Service中?(提供方法) 4.Service与D ...