李宏毅2022机器学习HW4 Speaker Identification上(Dataset &Self-Attention)
Homework4
Dataset介绍及处理
Dataset introduction
训练数据集metadata.json包括speakers和n_mels,前者表示每个speaker所包含的多条语音信息(每条信息有一个路径feature_path和改条信息的长度mel_len或理解为frame数即可),后者表示滤波器数量,简单理解为特征数即可,由此可知每个.pt语言文件可以表示为大小为mel_len \(\times\) n_mels的矩阵,其中所有文件已规定n_mels为40,不同的是语言信息的长度即mel_len。
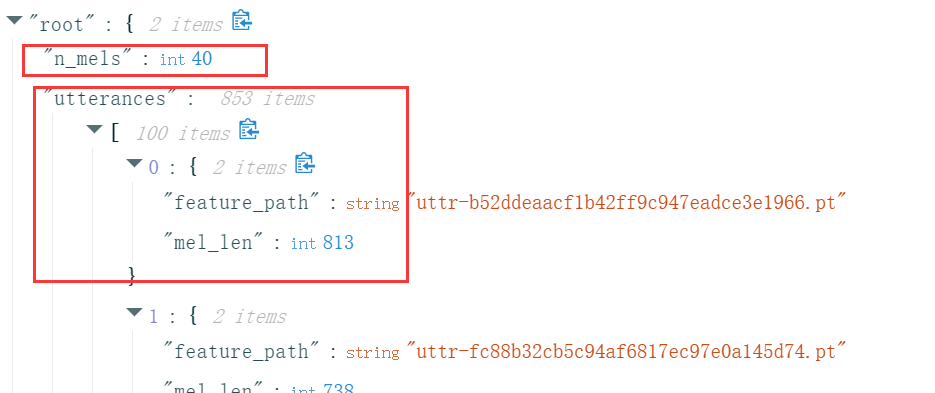
测试数据集testdata.json包括n_mels和utterances,其中n_mels和意义前面一样且固定为40,utterance表示一条语音信息,不同的是这里我们不知道这则信息是谁说出来的,任务就是检测这些信息分别是谁说的。
映射文件mapping.json包括两项speaker2id和id2speaker,前者将600个speaker的编号隐射为0-599,后者则是相反的操作。

Dataset procession
正如上面说,尽管“古圣先贤”已经帮我们做好了绝大多数的数据处理操作,但是如果想要批量训练数据那么就需要对每个语音序列的mel_len进行固定,比如在sample code里面固定为128个frame
class myDataset(Dataset):
def __init__(self, data_dir, segment_len=128):
它的具体实现方式如下
def __getitem__(self, index):
feat_path, speaker = self.data[index]
# Load preprocessed mel-spectrogram.
mel = torch.load(os.path.join(self.data_dir, feat_path))
# Segmemt mel-spectrogram into "segment_len" frames.
if len(mel) > self.segment_len:
# Randomly get the starting point of the segment.
start = random.randint(0, len(mel) - self.segment_len)
# Get a segment with "segment_len" frames.
mel = torch.FloatTensor(mel[start:start+self.segment_len])
else:
mel = torch.FloatTensor(mel)
# Turn the speaker id into long for computing loss later.
speaker = torch.FloatTensor([speaker]).long()
return mel, speaker
即从每个语音序列总的frame中抽取连续的128个frame,但是这并不能够保证所有的语音需要都为128个frame,可能某语音序列的frame数原本就小于128,因此还需要另外一道保险即padding。
def collate_batch(batch):
# Process features within a batch.
"""Collate a batch of data."""
mel, speaker = zip(*batch)
# Because we train the model batch by batch, we need to pad the features in the same batch to make their lengths the same.
mel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad log 10^(-20) which is very small value.
# mel: (batch size, length, 40)
return mel, torch.FloatTensor(speaker).long()
def get_dataloader(data_dir, batch_size, n_workers):
"""Generate dataloader"""
dataset = myDataset(data_dir)
speaker_num = dataset.get_speaker_number()
# Split dataset into training dataset and validation dataset
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
trainset, validset = random_split(dataset, lengths)
train_loader = DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=n_workers,
pin_memory=True,
collate_fn=collate_batch,
)
valid_loader = DataLoader(
validset,
batch_size=batch_size,
num_workers=n_workers,
drop_last=True,
pin_memory=True,
collate_fn=collate_batch,
)
return train_loader, valid_loader, speaker_num
在data_loader读取一个batch时,如果仍旧有不同大小的frame,那么就可以通过指定collate_fn=collate_batch对数据进行填充,确保每个batch的frame相同进而进行批量(并行?)计算。
当然你也可以不预先设置frame数为128,仅使用collate_batch,那么就会使这个batch内所有语音序列的frame数自动对齐到最长的frame,但往往会爆显存。
Self-Attention简单介绍
在不考虑Multi-Head Attention以及add &norm的情况下
\(X'=\)Self-Attention\((X, W^q, W^k, W^v, W^l)\) = \(\frac{XW^q(XW^k)^T}{\sqrt{d_k}}XW^vW^l\)
其中\(X, W^q, W^k, W^v, W^l\)维度分别为\(n\times d_{model}, d_{model}\times d_k, d_{model}\times d_k, d_{model}\times d_v, d_v\times d_{model}\),并称\(Q=X\times W^q, K = X\times W^k, V = X\times W^v\)
可知,变化后的\(X'\)与原来\(X\)的维度相同,这一变化过程简称为编码,那么问题来了\(X'\)与\(X\)究竟有何不同?
在变化过程中,我们对\(Q\)和\(K\)做了内积运算,这表示一个查询匹配过程,内积越大则相似度越高,那么匹配所得的权重也就越大(表明越关注这个讯息),之后再和\(V\)运算相当于通过前面的权重及原始\(V\)对新\(X\)的\(V\)做预测,视频给出了很生动的表述。
但是这里我有一疑问,为什么点积运算可以表示关注度?点积可以在一定程度表示两向量的关联性,这一点毫无疑问,但是凭什么关联性越高也意味着关注度(得分)越高呢?
李宏毅2022机器学习HW4 Speaker Identification上(Dataset &Self-Attention)的更多相关文章
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- 机器学习-Tensorflow之Tensor和Dataset学习
好了,咱们今天终于进入了现阶段机器学习领域内最流行的一个框架啦——TensorFlow.对的,这款由谷歌开发的机器学习框架非常的简单易用并且得到了几乎所有主流的认可,谷歌为了推广它的这个框架甚至单独开 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 2: Where does the error come from?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: ML Lecture 1: Regression - Demo
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: 回归案例研究
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-2: Why we need to learn machine learning?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-1: Introduction of Machine Learning
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- z/OS上Dataset 的移动
最近的一个需求,需要把大批量的Dataset移到新的Storage Class,新的Volume中去,刚开始感觉非常头疼.仔细研究后发现这个事情其实很简单.确实符合别人所说,事情的在你真正开始努力之后 ...
- 机器学习之神经网络模型-上(Neural Networks: Representation)
在这篇文章中,我们一起来讨论一种叫作"神经网络"(Neural Network)的机器学习算法,这也是我硕士阶段的研究方向.我们将首先讨论神经网络的表层结构,在之后再具体讨论神经网 ...
随机推荐
- 对象中是否有某一个属性是否存在有三种方法 in hasOwnProperty Object.hasOwn
如何看某个对象中没有某一个属性 如果我们要检测对象是否拥有某一属性,可以用in操作符 var obj= { name: '类老师', age: 18, school: '家具' }; console. ...
- vs code python(Pylance server) crash
The Pylance server crashed 5 times in the last 3 minutes. The server will not be restarted. See the ...
- 系统Hosts文件原理和应用
Hosts的概念 Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联"数据库",当用户在浏览器中输入一个需要 ...
- 基于.NET的机械运动模拟应用开发
1 简介 机械运动在物理学中,把一个物体相对于另一个物体位置的变化称作为机械运动,简称运动.机械运动是指一个物体相对于其他物体的位置发生改变,是自然界中最简单,最基本的运动形态. 自然界中一切物体都在 ...
- 【STL源码剖析】list模拟实现 | 适配器实现反向迭代器【超详细的底层算法解释】
今天博主继续带来STL源码剖析专栏的第三篇博客了! 今天带来list的模拟实现!话不多说,直接进入我们今天的内容! 前言 那么这里博主先安利一下一些干货满满的专栏啦! 手撕数据结构https://bl ...
- P4149 [IOI2011] Race 题解
题目链接:Race 点分治基本题,从这题简单阐述点分治如何思考问题的.点分治常见的解决一类问题,就是树里面的一些路径类问题.比如一些计数是最常见的. 点分治的一个核心计数思想: 如图所见,对于某个点而 ...
- 关于ASP.NET WEB API(OWIN WEBAPI)的几个编码最佳实践总结
近期工作比较忙,确实没太多精力与时间写博文,博文写得少,但并不代表没有研究与总结,也不会停止我继续分享的节奏,最多有可能发博文间隔时间稍长一点.废话不多说,直接上干货,虽不是主流的ASP.NET CO ...
- Python-统计执行时间
方法一:datetime.datetime.now() import datetime import time starttime = datetime.datetime.now() print(st ...
- IIS创建和管理虚拟网站
实验介绍: 本文会详细介绍创建虚拟站点的三种方法 一:IP地址建立站点 1.打开安装了IIS的windows,进入ip配置页面. 添加几个ip,我这里添加的是192.168.1.209,192.168 ...
- JOISC 2020 记录
Day1 T1 Building 4 首先有一个 \(O(n^2)\) 的 DP:记 \(f_{i,j,0/1}\) 表示已经填了前 \(i\) 位,其中有 \(j\) 位选择了 A 序列,当前第 \ ...