Paimon的写入流程
基于Paimon 0.5版本
写入流程的构建org.apache.paimon.flink.sink.FlinkSinkBuilder#build
算子的流向
BucketingStreamPartitioner 分区 -> RowDataStoreWriteOperator 写入 -> CommitterOperator 提交
Primary key表写入
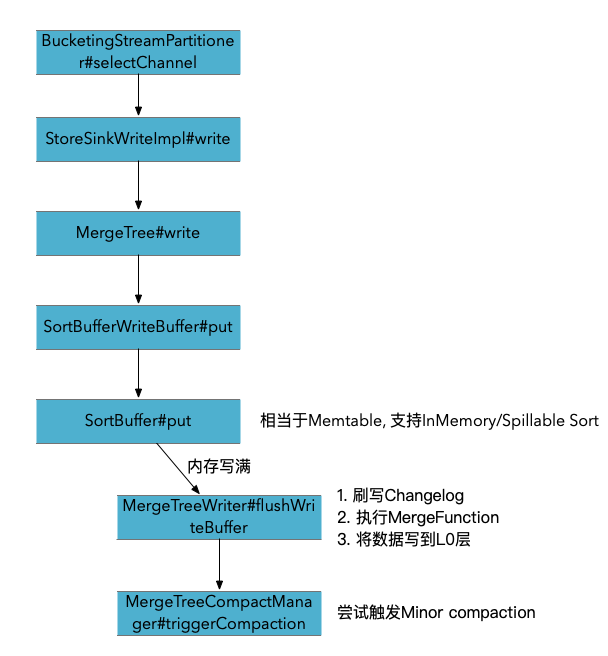
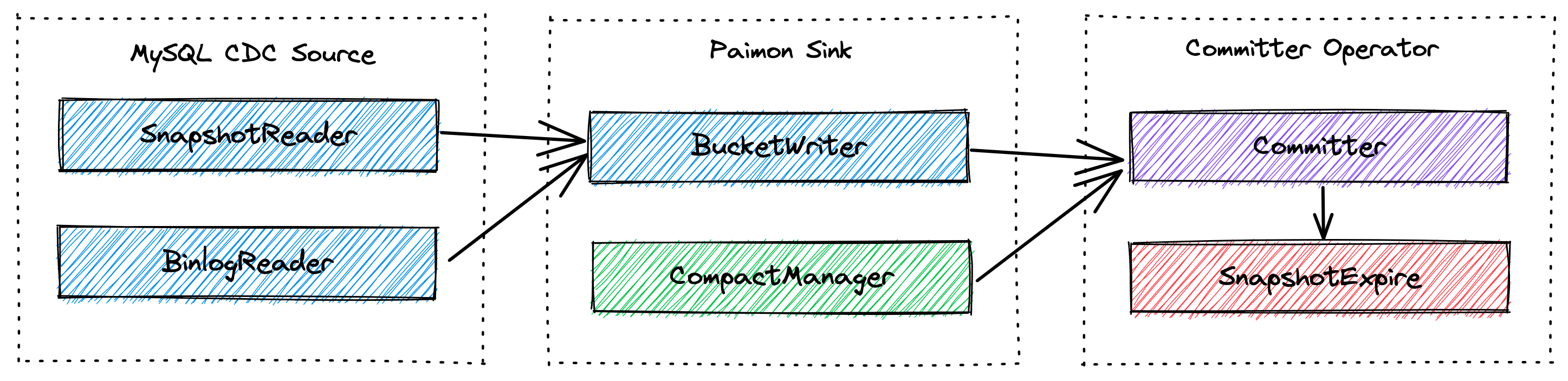
BucketingStreamPartitioner 根据数据的bucket和partition计算数据应该发送的通道
RowDataStoreWriteOperator#processElement
try {
// GlobalFullCompactionSinkWrite
// StoreSinkWriteImpl
record = write.write(new FlinkRowWrapper(element.getValue()));
} catch (Exception e) {
throw new IOException(e);
}
// 同步写到logSystem中. SinkRecord 中包含了partition,bucket,primary key信息
if (logSinkFunction != null) {
// write to log store, need to preserve original pk (which includes partition fields)
SinkRecord logRecord = write.toLogRecord(record);
logSinkFunction.invoke(logRecord, sinkContext);
}
如果配置了logSystem, 其实就相当于数据双写, 导一份到Paimon表, 另一份到消息队列用于其他对时延要求更低的场景. 这也是当前Paimon表没法提供消息队列秒级时延的订阅的折中方案. 实际场景用处应该不大, 支持在表的层面屏蔽了背后的消息队列的表
org.apache.paimon.mergetree.MergeTreeWriter#flushWriteBuffer
内存满后 刷写writeBuffer. 排序后, 遍历buffer. 应用merge函数, 并创建level 0的 file writer, 将数据写入到datafile中. 如果同时配置了Changelog producer是input,那么会将原始的数据写出到Changelog文件中.
// 如果配置了ChangelogProducer.INPUT 那么再刷写WriteBuffer的时候会同时将原始数据写入到changelog里面
final RollingFileWriter<KeyValue, DataFileMeta> changelogWriter =
changelogProducer == ChangelogProducer.INPUT
? writerFactory.createRollingChangelogFileWriter(0)
: null;
final RollingFileWriter<KeyValue, DataFileMeta> dataWriter =
writerFactory.createRollingMergeTreeFileWriter(0);
try {
writeBuffer.forEach(
keyComparator,
mergeFunction,
changelogWriter == null ? null : changelogWriter::write,
dataWriter::write); // 最终使用的Orc/Parquet Writer来将数据写出
} finally {
if (changelogWriter != null) {
changelogWriter.close();
}
dataWriter.close();
}
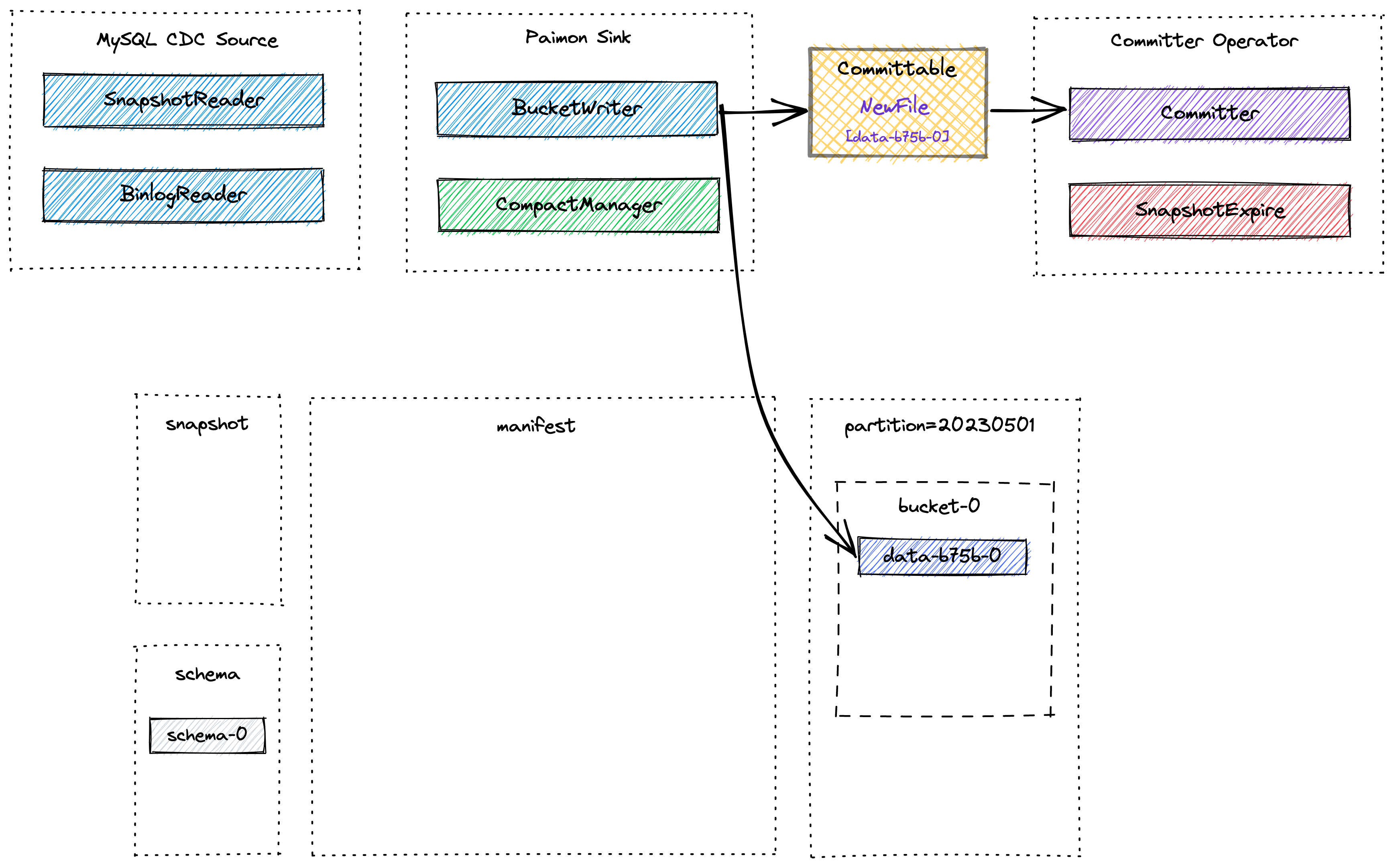
数据合并
在写入的过程中会调用MergeFunction来进行合并, 以DeduplicateMergeFunction为例, 就是不断保留最新的一条数据. merge的顺序是, 同一条key下, 按照key + sequence number的增序传入. 所以就是保留每个key的最新的数据.
那么当最后一条数据是DELETE消息时, 其实这条数据也会被保留, 并被写入到数据文件中.
什么时候被真正删除的呢? 首先构建snapshot read的时候, 会通过DropDeleteReader 来读取数据, 所以直接select查询就不会看到了.
而数据在compact阶段, 如果某个数据的compact的target level是最高非空的那层(意味着这个数据后续不会在使用了) 那么就可以安全的drop掉这行数据.
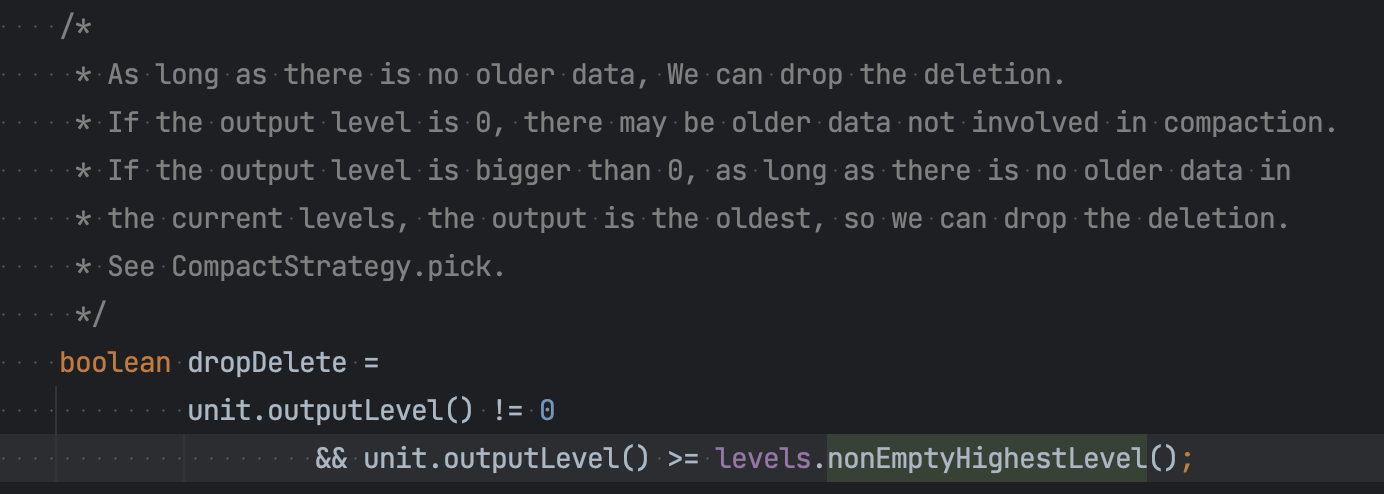
Snapshot 流程
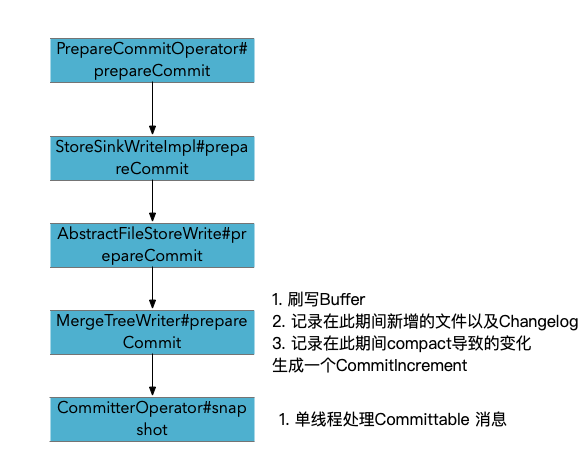
Checkpoint阶段 commit流程


Append-only表写入
Append-only的表是没有Pk的表, 在创建表的时候就已经根据pk和write-mode参数确定了表的类型, 一般来说,没有PK的就是Append-only的表, Append-only的表意味着不处理变更流的数据
org.apache.paimon.operation.AbstractFileStoreWrite#write
org.apache.paimon.operation.AppendOnlyFileStoreWrite#createWriter 创建AppendOnlyWriter
org.apache.paimon.io.RollingFileWriter#write append-only 表直接写文件了, 没有pk表中的write buffer
Paimon的写入流程的更多相关文章
- HBase读取与写入流程
写入流程 读取流程 https://yq.aliyun.com/articles/670748?spm=a2c4e.11153940.blogcont684011.28.427e4648CTtaPL
- HBase - 数据写入流程解析
本文由 网易云发布. 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松 ...
- Kafka写入流程和副本策略
Kafka写入流程: 1.producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader 2. prod ...
- elasticsearch的数据写入流程及优化
Elasticsearch 写入流程及优化 一. 集群分片设置:ES一旦创建好索引后,就无法调整分片的设置,而在ES中,一个分片实际上对应一个lucene 索引,而lucene索引的读写会占用很多的系 ...
- 8.hbase写入流程和读取流程
1 hbase写入流程 hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 M ...
- 深入浅出 Redis client/server交互流程
综述 最近笔者阅读并研究redis源码,在redis客户端与服务器端交互这个内容点上,需要参考网上一些文章,但是遗憾的是发现大部分文章都断断续续的非系统性的,不能给读者此交互流程的整体把握.所以这里我 ...
- “Ceph浅析”系列之五——Ceph的工作原理及流程
本文将对Ceph的工作原理和若干关键工作流程进行扼要介绍.如前所述,由于Ceph的功能实现本质上依托于RADOS,因而,此处的介绍事实上也是针对RADOS进行.对于上层的部分,特别是RADOS GW和 ...
- ccbpm工作流引擎是怎样支持多种流程模式的
前言: 在BPM领域支持流程运转的理论模型有多种.有的21种.28种.32种. 每种模式都代表了这样的模式的理论设计者研究者的人员主张.思想.这些模式尽可能的,全然去覆盖到现实生产.工作.应用上的流程 ...
- ES 18 - (底层原理) Elasticsearch写入索引数据的过程 以及优化写入过程
目录 1 Lucene操作document的流程 1.1 添加document的流程 1.2 删除document的流程 2 优化写入流程 - 实现近实时搜索 2.1 流程的改进思路 2.2 设置re ...
- java工作流引擎Jflow流程事件和流程节点事件设置
流程实例的引入和设置 关键词: 开源工作流引擎 Java工作流开发 .net开源工作流引擎 流程事件 工作流节点事件 应用场景: 在一些复杂的业务逻辑流程中需要在某个节点或者是流程结束后做一些 ...
随机推荐
- #杜教筛,欧拉函数#51nod 1227 平均最小公倍数
题目 设 \(\large A(n)=\frac{1}{n}\sum_{i=1}^n lcm(i,n)\), 求 \(\sum_{i=l}^rA(i)\),\(n\leq 10^9\) 分析 题意可以 ...
- 【FAQ】运动健康服务云侧数据常见问题及解答
目录 Q1:v2接口相比于v1接口传参及返回的数据格式有变化吗?是否可以直接将v1接口改成v2接口? Q2:如何获取采集健康数据的穿戴设备信息? Q3:如何处理非华为手机产生的步数调用采样明细接口查询 ...
- 上新啦!KIT!
上新啦!KIT!近期KIT上新榜单请查收~ 商业推广深度转化事件回传助力用户精细运营,健康数据开放提升运动健康服务体验.手语服务新增非手控部分-- 更多功能请点击 了解更多详情>> 访问华 ...
- linux上操作 压缩包 的命令
# tar.gz 解压缩 # 解压 tar -zxvf a.tar.gz # 压缩 tar -zcvf a.atr.gz a # zip 解压缩 # 压缩 zip -vr a.zip a/* # 解压 ...
- Qt 设置图标的三种方式
Qt 设置软件窗口图标有三种方式: 一.通过资源文件,设置图标 this->setWindowIcon(QIcon(":/logo.ico")); 二.通过 pro 文件,设 ...
- openGauss/MogDB零字节问题处理
openGauss/MogDB 零字节问题处理 问题描述:java 应用端程序调用 GZIP 压缩类对数据进行编码压缩后入库 ,然后从数据库取出进行解压,原来再 mysql 数据库中是正常的,但迁移到 ...
- Kryo反序列化链分析
前言 Kryo是一个快速序列化/反序列化工具,依赖于字节码生成机制(底层使用了ASM库),因此在序列化速度上有一定的优势,但正因如此,其使用也只能限制在基于JVM的语言上. Kryo序列化出的结果,是 ...
- Vue 项目 invalid host header 问题 配置 disableHostCheck:true报错
项目场景:解决 Vue 项目 invalid host header 问题disableHostCheck:true报错 问题描述使用内网穿透时出现 invalid host header找了好多都是 ...
- C++ 类方法解析:内外定义、参数、访问控制与静态方法详解
C++ 类方法 类方法,也称为成员函数,是属于类的函数.它们用于操作或查询类数据,并封装在类定义中.类方法可以分为两种类型: 类内定义方法: 直接在类定义内部声明和定义方法. 类外定义方法: 在类定义 ...
- 力扣541(java)-反转字符串Ⅱ(简单)
题目: 给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符. 如果剩余字符少于 k 个,则将剩余字符全部反转.如果剩余字符小于 2k ...