SparkSQL相关语句总结
1.in 不支持子查询 eg. select * from src where key in(select key from test);
支持查询个数 eg. select * from src where key in(1,2,3,4,5);
in 40000个 耗时25.766秒
in 80000个 耗时78.827秒
2.union all/union
不支持顶层的union all eg. select key from src UNION ALL select key from test;
支持select * from (select key from src union all select key from test)aa;
不支持 union
支持select distinct key from (select key from src union all select key from test)aa;
3.intersect 不支持
4.minus 不支持
5.except 不支持
6.inner join/join/left outer join/right outer join/full outer join/left semi join 都支持
left outer join/right outer join/full outer join 中间必须有outer
join是最简单的关联操作,两边关联只取交集;
left outer join是以左表驱动,右表不存在的key均赋值为null;
right outer join是以右表驱动,左表不存在的key均赋值为null;
full outer join全表关联,将两表完整的进行笛卡尔积操作,左右表均可赋值为null;
left semi join最主要的使用场景就是解决exist in;
Hive不支持where子句中的子查询,SQL常用的exist in子句在Hive中是不支持的
不支持子查询 eg. select * from src aa where aa.key in(select bb.key from test bb);
可用以下两种方式替换:
select * from src aa left outer join test bb on aa.key=bb.key where bb.key <> null;
select * from src aa left semi join test bb on aa.key=bb.key;
大多数情况下 JOIN ON 和 left semi on 是对等的
A,B两表连接,如果B表存在重复数据
当使用JOIN ON的时候,A,B表会关联出两条记录,应为ON上的条件符合;
而是用LEFT SEMI JOIN 当A表中的记录,在B表上产生符合条件之后就返回,不会再继续查找B表记录了,
所以如果B表有重复,也不会产生重复的多条记录。
left outer join 支持子查询 eg. select aa.* from src aa left outer join (select * from test111)bb on aa.key=bb.a;
7. hive四中数据导入方式
1)从本地文件系统中导入数据到Hive表
create table wyp(id int,name string) ROW FORMAT delimited fields terminated by '\t' STORED AS TEXTFILE;
load data local inpath 'wyp.txt' into table wyp;
2)从HDFS上导入数据到Hive表
[wyp@master /home/q/hadoop-2.2.0]$ bin/hadoop fs -cat /home/wyp/add.txt
hive> load data inpath '/home/wyp/add.txt' into table wyp;
3)从别的表中查询出相应的数据并导入到Hive表中
hive> create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
注:test表里面用age作为了分区字段,分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。
比如wyp表有dt和city两个分区,则对应dt=20131218city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,
所有属于这个分区的数据都存放在这个目录中。
hive> insert into table test
> partition (age='25')
> select id, name, tel
> from wyp;
也可以在select语句里面通过使用分区值来动态指明分区:
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table test
> partition (age)
> select id, name,
> tel, age
> from wyp;
Hive也支持insert overwrite方式来插入数据
hive> insert overwrite table test
> PARTITION (age)
> select id, name, tel, age
> from wyp;
Hive还支持多表插入
hive> from wyp
> insert into table test
> partition(age)
> select id, name, tel, age
> insert into table test3
> select id, name
> where age>25;
4)在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
hive> create table test4
> as
> select id, name, tel
> from wyp;
8.查看建表语句
hive> show create table test3;
9.表重命名
hive> ALTER TABLE events RENAME TO 3koobecaf;
10.表增加列
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
11.添加一列并增加列字段注释
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
12.删除表
hive> DROP TABLE pokes;
13.top n
hive> select * from test order by key limit 10;
14.创建数据库
Create Database baseball;
14.alter table tablename change oldColumn newColumn column_type 修改列的名称和类型
alter table yangsy CHANGE product_no phone_no string
15.导入.sql文件中的sql
insert into table CI_CUSER_20141117154351522 select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_d01_3845.L2_01_01_04 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO left join DW_COCLBL_D01_20140515 dw_coclbl_d01_3845 on dw_coclbl_m02_3848.PRODUCT_NO = dw_coclbl_d01_3845.PRODUCT_NO
insert into CI_CUSER_20141117142123638 ( PRODUCT_NO,ATTR_COL_0000,ATTR_COL_0001) select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_m02_3848.L1_01_03_01 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO
CREATE TABLE ci_cuser_yymmddhhmisstttttt_tmp(product_no string) row format serde 'com.bizo.hive.serde.csv.CSVSerde' ;
LOAD DATA LOCAL INPATH '/home/ocdc/coc/yuli/test123.csv' OVERWRITE INTO TABLE test_yuli2;
创建支持CSV格式的testfile文件
CREATE TABLE test_yuli7 row format serde 'com.bizo.hive.serde.csv.CSVSerde' as select * from CI_CUSER_20150310162729786;
不依赖CSVSerde的jar包创建逗号分隔的表
"create table " +listName+ " ROW FORMAT DELIMITED FIELDS TERMINATED BY ','" +
" as select * from " + listName1;
create table aaaa ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE as select * from
ThriftServer 开启FAIR模式
SparkSQL Thrift Server 开启FAIR调度方式:
1. 修改$SPARK_HOME/conf/spark-defaults.conf,新增
2. spark.scheduler.mode FAIR
3. spark.scheduler.allocation.file /Users/tianyi/github/community/apache-spark/conf/fair-scheduler.xml
4. 修改$SPARK_HOME/conf/fair-scheduler.xml(或新增该文件), 编辑如下格式内容
5. <?xml version="1.0"?>
6. <allocations>
7. <pool name="production">
8. <schedulingMode>FAIR</schedulingMode>
9. <!-- weight表示两个队列在minShare相同的情况下,可以使用资源的比例 -->
10. <weight>1</weight>
11. <!-- minShare表示优先保证的资源数 -->
12. <minShare>2</minShare>
13. </pool>
14. <pool name="test">
15. <schedulingMode>FIFO</schedulingMode>
16. <weight>2</weight>
17. <minShare>3</minShare>
18. </pool>
19. </allocations>
20. 重启Thrift Server
21. 执行SQL前,执行
22. set spark.sql.thriftserver.scheduler.pool=指定的队列名
等操作完了 create table yangsy555 like CI_CUSER_YYMMDDHHMISSTTTTTT 然后insert into yangsy555 select * from yangsy555
创建一个自增序列表,使用row_number() over()为表增加序列号 以供分页查询

Sparksql的解析与Hiveql的解析的执行流程:
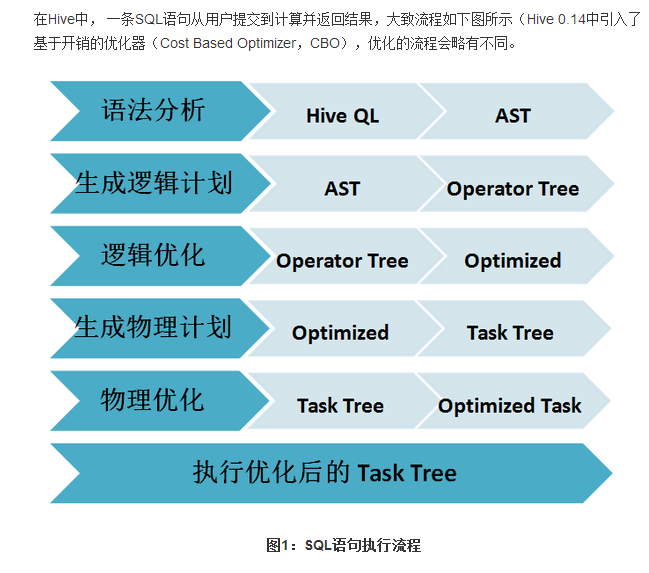
SparkSQL相关语句总结的更多相关文章
- SQL Server 锁表、查询被锁表、解锁相关语句
SQL Server 锁表.查询被锁表.解锁相关语句,供参考. --锁表(其它事务不能读.更新.删除) BEGIN TRAN SELECT * FROM <表名> WITH(TABLOCK ...
- Mariadb MySQL逻辑条件判断相关语句、函数使用举例介绍
MySQL逻辑条件判断相关语句.函数使用举例介绍 By:授客 QQ:1033553122 1. IFNULL函数介绍 IFNULL(expr1, expr2) 说明:假如expr1 不为NULL,则 ...
- AJPFX关于表结构的相关语句
//表结构的相关语句==================================== 建表语句: create table 表名( ...
- sql server锁表、查询被锁表、解锁被锁表的相关语句
MSSQL(SQL Server)在我的印象中很容易锁表,大致原因就是你在一个窗口中执行的DML语句没有提交,然后又打开了一个窗口对相同的表进行CRUD操作,这样就会导致锁表.锁表是一种保持数据一致性 ...
- Spark记录-SparkSQL相关学习
$spark-sql --help 查看帮助命令 $设置任务个数,在这里修改为20个 spark-sql>SET spark.sql.shuffle.partitions=20; $选择数据 ...
- SparkSql常用语句
-连接sparksql: cd /home/mr/spark/bin ./beeline !connect jdbc:hive2://hostname:port --切换数据库 use databas ...
- 执行计划中Using filesort,Using temporary相关语句的优化解决
昨天听开发人员提到,相关的彩票网页当中一个页面刷新的很慢,特别是在提取数据的时候,今天早上一到,便去找开发人员要去相关的也没进行浏览,窥探哪些数据出现了问题,开发人员使用PHP开发,所以我用IE很容易 ...
- oracle 表空间、用户名 相关语句
一.oracle查询表空间文件所在路径 select * from dba_data_files t where t.tablespace_name='FLW' 二.计算出表空间各相关数据 SELE ...
- oracle创建表空间等相关语句
在数据库可视化工具中执行以下语句,可建立Oracle表空间. 主要分为四步 1.创建临时表空间 create temporary tablespace xuanwu_temp tempfile 'D: ...
随机推荐
- UVa 839 天平
原题链接:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem ...
- 黑马程序员——JAVA基础之抽象和接口 , 模版方法设计模式
------- android培训.java培训.期待与您交流! ---------- 抽象定义: 抽象就是从多个事物中将共性的,本质的内容抽取出来. 例如:狼 ...
- java的nio之:java的nio系列教程之Scatter/Gather
一:Java NIO的scatter/gather应用概念 ===>Java NIO开始支持scatter/gather,scatter/gather用于描述从Channel(译者注:Chann ...
- (转)TensorFlow 入门
TensorFlow 入门 本文转自:http://www.jianshu.com/p/6766fbcd43b9 字数3303 阅读904 评论3 喜欢5 CS224d-Day 2: 在 Da ...
- min—width的使用
在网页中,如果一个元素没有设置最小宽度(min-width),这时当浏览器缩小到一定程度时,元素中的布局可能会发生变化.如果想要保持布局不变,可以给该元素(如div)设置最小宽度属性 .box{ ba ...
- easyUI之layout
此组件与easyUI中的其它组件加载的方式相同,载为class方式和js方式,但此组件更多的是用class方式,其它的用js方式更为灵活.它继承panel组件及resize组件. 包括多个<di ...
- maxsdk sample中3dsexp.rc点不开并提示specstrings.h中找不到sal.h解法
在网上下载sal.h文件并拷贝到specstrings.h所在目录(C:\Program Files (x86)\Microsoft SDKs\Windows\v7.0A\Include)即可. sa ...
- python escape sequences
转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \' 单引号 \" 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \ ...
- java动态代理(JDK和cglib)
转:http://www.cnblogs.com/jqyp/archive/2010/08/20/1805041.html JAVA的动态代理 代理模式 代理模式是常用的java设计模式,他的特征是代 ...
- Redis学习手册(服务器管理)
转:http://www.cnblogs.com/stephen-liu74/archive/2012/02/27/2369480.html 一.概述: Redis在设计之初就被定义为长时间不间断运行 ...