sklearn dataset 模块学习
sklearn.datasets官网:http://scikit-learn.org/stable/datasets/
sklearn.datasets 模块主要提供一些导入、在线下载及本地生成数据集的方法,可以通过 dir 或 help 命令查看,会发现主要有三种形式:load_<dataset_name>、fetch_<dataset_name> 及 make_<dataset_name> 的方法
sklearn 的数据集有好多个种
- 自带的小数据集(packaged dataset):sklearn.datasets.load_<name>
- 可在线下载的数据集(Downloaded Dataset):sklearn.datasets.fetch_<name>
- 计算机生成的数据集(Generated Dataset):sklearn.datasets.make_<name>
- svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(...)
- 从买了data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(...)
1. dataset.load_<dataset_name>:sklearn包自带的小数据集

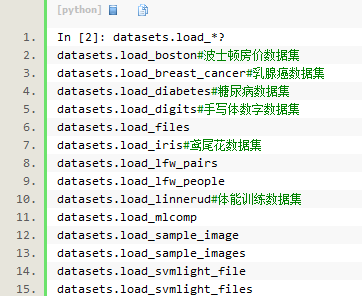
数据集文件在 sklearn 安装目录下 datasets\data 文件下
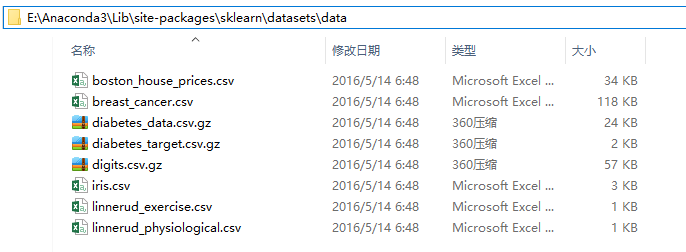
2. datasets.fetch_<dataset_name> :比较大的数据集,主要用于测试解决实际问题,支持在线下载
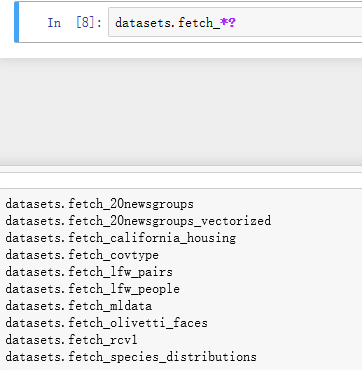
下载下来的数据,默认保存在~/scikit_learn_data文件夹下,可以通过设置环境变量SCIKIT_LEARN_DATA修改路径,datasets.get_data_home()获取下载路径

3. datasets.make_*?:构造数据集
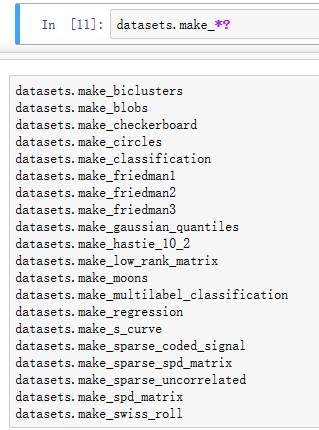
下面以make_regression()函数为例,首先看看函数语法:
make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
参数说明:
- n_samples:样本数
- n_features:特征数(自变量个数)
- n_informative:相关特征(相关自变量个数)即参与了建模型的特征数
- n_targets:因变量个数
- bias:偏差(截距)
- coef:是否输出coef标识
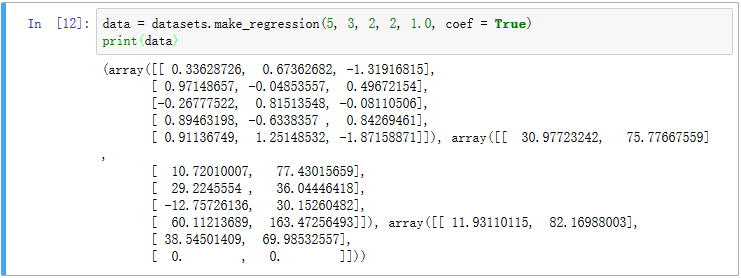
上述输出结果:元组中的三个数组分别对应输入数据X,输出数据y,coef对应数组。
sklearn dataset 模块学习的更多相关文章
- sklearn datasets模块学习
sklearn.datasets模块主要提供了一些导入.在线下载及本地生成数据集的方法,可以通过dir或help命令查看,我们会发现主要有三种形式:load_<dataset_name>. ...
- Python —— sklearn.feature_selection模块
Python —— sklearn.feature_selection模块 sklearn.feature_selection模块的作用是feature selection,而不是feature ex ...
- 使用sklearn进行集成学习——实践
系列 <使用sklearn进行集成学习——理论> <使用sklearn进行集成学习——实践> 目录 1 Random Forest和Gradient Tree Boosting ...
- 使用sklearn进行集成学习——理论
系列 <使用sklearn进行集成学习——理论> <使用sklearn进行集成学习——实践> 目录 1 前言2 集成学习是什么?3 偏差和方差 3.1 模型的偏差和方差是什么? ...
- Day5 - Python基础5 常用模块学习
Python 之路 Day5 - 常用模块学习 本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shel ...
- [转]使用sklearn进行集成学习——理论
转:http://www.cnblogs.com/jasonfreak/p/5657196.html 目录 1 前言2 集成学习是什么?3 偏差和方差 3.1 模型的偏差和方差是什么? 3.2 bag ...
- [转]使用sklearn进行集成学习——实践
转:http://www.cnblogs.com/jasonfreak/p/5720137.html 目录 1 Random Forest和Gradient Tree Boosting参数详解2 如何 ...
- # nodejs模块学习: express 解析
# nodejs模块学习: express 解析 nodejs 发展很快,从 npm 上面的包托管数量就可以看出来.不过从另一方面来看,也是反映了 nodejs 的基础不稳固,需要开发者创造大量的轮子 ...
- 【转】Python模块学习 - fnmatch & glob
[转]Python模块学习 - fnmatch & glob 介绍 fnmatch 和 glob 模块都是用来做字符串匹配文件名的标准库. fnmatch模块 大部分情况下使用字符串匹配查找特 ...
随机推荐
- OCR技术初识
一.什么是OCR OCR英文全称是Optical Character Recognition,中文叫做光学字符识别.它是利用光学技术和计算机技术把印在或写在纸上的文字读取出来,并转换成一种计算机能够接 ...
- mysql执行计划查看工具explain
在优化sql语句时,我们经常会用到explain语句,这里对explain语句做一个详细的总结说明. The EXPLAIN statement provides information about ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Prometheus监控学习笔记之prometheus的federation机制
0x00 概述 有时候对于一个公司,k8s集群或是所谓的caas只是整个技术体系的一部分,往往这个时候监控系统不仅仅要k8s集群以及k8s中部署的应用,而且要监控传统部署的项目.也就是说整个监控系统不 ...
- Linux学习笔记之CentOS7配置***SS
0x00 概述 最近安装K8S,镜像在国内不可达,只能通过科学方法获取. 0x01 安装配置Shadowsocks客户端 1.1 安装Sha.dows.ocks客户端 安装epel扩展源 采用Pyth ...
- python类的组合
类的组合,即在类实例化时,将另一个类的实例作为参数传入,这样可以将两个实例关联起来. 当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好. 例如,描述一个机器人类,这个大类是由很多 ...
- spring boot 1.x完整学习指南(含各种常见问题servlet、web.xml、maven打包,spring mvc差别及解决方法)
spring boot 入门 关于版本的选择,spring boot 2.0开始依赖于 Spring Framework 5.1.0,而spring 5.x和之前的版本差距比较大,而且应该来说还没有广 ...
- ldap集成zabbix
zabbix版本:3.0.7 ldap认证配置: zabbix管理员登录-->管理-->认证,选择ldap方式 参照以上格式填写,需注意配置完成后需在zabbix上创建与ldap同名账户才 ...
- css 元素居中
css 4种常见实现元素居中的办法: 1.通过 margin 属性调整 : { position: absolute; top: 50%; left: 50%; margin-left: 盒子的一半: ...
- Centos7.03搭建JDK、Tomcat、MySql环境
本人linux服务器配置是:centos_7_03_64_20G_xdragon_20171025.vhd 公网IP:106.14.14.224 内存:2GB SecureCRT8.0:https:/ ...