python+selenium一:对浏览器的操作
# 1.打开Firefox浏览器
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.baidu.com")

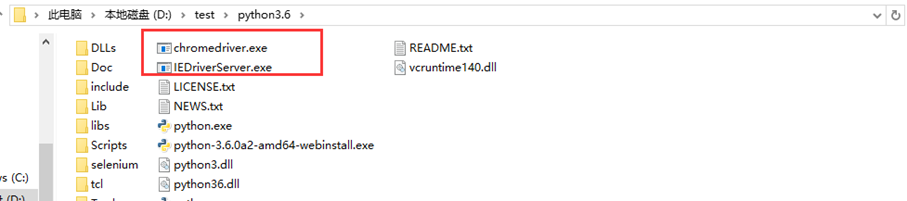
# 2.打开Ie或Chrome浏览器-->先将驱动文件放到python根目录
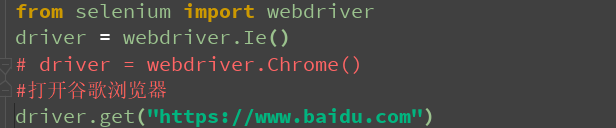
from selenium import webdriver
driver = webdriver.Ie()
# driver = webdriver.Chrome()
#打开谷歌浏览器
driver.get("https://www.baidu.com")
注意:
1.Firefox浏览器47.0版本会报错,安装46.0以下版本(勿升级)
2.取消Ie浏览器保护模式
# 常规操作
from selenium import webdriver
import time
# 打开浏览器
# 浏览器驱动放到python.exe目录下可免去将驱动地址加到环境变量步骤
driver = webdriver.Firefox()
# sllep 休眠
time.sleep(3) # 等待3秒
driver.get('https://www.baidu.com')
time.sleep(3)
driver.get('https://hao.360.cn/?src=lm&ls=n72374cee90')
time.sleep(3)
driver.back() # 返回上一页(右箭头)
driver.forward() # 去下一页(左箭头)
driver.refresh() # 刷新当前网页
driver.close() # 关闭当前窗口
# .submit() 模拟键盘的回车建
driver.find_element_by_link_text('新闻').submit()
driver.quit() # 退出浏览器,清空临时文件
加载火狐配置:
# coding=utf-8
from selenium import webdriver
# 配置文件地址
profile_directory = r'C:\Users\xx电脑用户名\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
# 加载配置配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)

加载谷歌配置
#coding=utf-8
from selenium import webdriver
option = webdriver.ChromeOptions()
# 设置成用户自己的数据目录【这里只要到User Data,不是User Data\Default】
option.add_argument('--user-data-dir=C:\\Users\\xxx电脑用户名\\AppData\\Local\\Google\\Chrome\\User Data')
driver = webdriver.Chrome(chrome_options=option)

python+selenium一:对浏览器的操作的更多相关文章
- Python+selenium自动化测试之浏览器基础操作
**前言** 本文主要讲解webdriber框架,Selenium 就像真实用户所做的一样,Selenium 测试可以在 Windows.Linux 和 Macintosh上的 Internet ...
- Python+Selenium自动化-设置浏览器大小、刷新页面、前进和后退
Python+Selenium自动化-设置浏览器大小.刷新页面.前进和后退 1.设置浏览器大小 maximize_window():设置浏览器大小为全屏 set_window_size(500,5 ...
- Python selenium + Firefox启动浏览器
Python selenium 的运用 from selenium import webdriver # from selenium.webdriver.firefox.firefox_profile ...
- 【Python+selenium Wendriver API】之操作警告和弹出框
参考文章: <Python+Selenium笔记(九):操作警告和弹出框>
- python selenium模块调用浏览器的时候出错
python selenium模块使用出错,这个怎么改 因为不同版本更新不同步问题,浏览器都要另外下一个驱动.
- 用Python+selenium打开IE浏览器和Chrome浏览器的问题
这几天在学Python+selenium自动化,对三大浏览器Firefox,Chrome和IE都做了尝试,也都分别下载了对应的webdriver,如:geckodriver.chromedriver. ...
- 使用python selenium webdriver模拟浏览器
selenium是进行web自动化测试的一个工具,支持C,C++,Python,Java等语言,他能够实现模拟手工操作浏览器,进行自动化,通过webdriver驱动浏览器操作,我使用的是chrome浏 ...
- 转:python webdriver API 之浏览器的操作
1.1.浏览器最大化在统一的浏览器大小下运行用例,可以比较容易的跟一些基于图像比对的工具进行结合,提升测试的灵活性及普遍适用性.比如可以跟 sikuli 结合,使用 sikuli 操作 flash.# ...
- Python+Selenium学习--控制浏览器控制条
场景 有时候web 页面上的元素并非直接可见的,就算把浏览器最大化,我们依然需要拖动滚动条才能看到想要操作的元素,这个时候就要控制页面滚动条的拖动,但滚动条并非页面上的元素,可以借助JavaScrip ...
- 基于Python, Selenium, Phantomjs无头浏览器访问页面
引言: 在自动化测试以及爬虫领域,无头浏览器的应用场景非常广泛,本文将梳理其中的若干概念和思路,并基于代码示例其中的若干使用技巧. 1. 无头浏览器 通常大家在在打开网页的工具就是浏览器,通过界面上输 ...
随机推荐
- IDEA如何自动提示并补全syso和main呢?
myeclipse使用若干年了,syso和main也被打过无数遍,切换到IDEA开发工具中,一按,天啦,竟然没有自动补全,顿时觉得IDEA弱爆了,经过摸索之后,IDEA终结没有令人失望.可以通过配置L ...
- selenium_采集药品数据2_采集所有表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- CISCO知识扫盲
cisco知识扫盲 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.vlan简介 1.什么是VLAN 简称虚拟局域网.至于英语怎么写自行百度吧. VLAN的优势: 1>.广 ...
- Linux命令之cd
cd命令 用处:跳转目录 用法:输入cd加上你想跳转的目录,这里分几种情况 示例: 一.进入当前目录的子目录 我现在的目录是 /home/jim,如图 这个目录下面有好多文件夹是吧,现在我想进入到其中 ...
- cas单点登陆。就这一篇就够了!!!!!
前言: cas是什么我就不累赘说了.就简单说下大致的流程.首先,cas是一个独立的项目.就是一个war包,部署在tomcat上面启动就ok.然后我们要实现单点登陆,无疑是访问系统1,如果没有登录,就跳 ...
- java.io.Serializable 序列化问题【原】
java.io.Serializable 序列化问题 Person.java package a.b.c; public class Person implements java.io.Seriali ...
- Hibernate添加日志--log4j
需要导入 slf4j-log4j12-1.6.2.jar slf4j-api-1.6.2.jar log4j-1.2.16.jar 三个jar文件 编写properties文件,建议将日志输出级别设置 ...
- C++:error 1189(转)
在VS 2013中编译程序时出现错误: 错误提示1: error C1189: #error : Building MFC application with /MD[d] (CRT dll versi ...
- apache - http
apahce 添加模块编译 httpd # so模块用来提供DSO支持的apache核心模块 # 如果编译中包含任何DSO模块,则mod_so会被自动包含进核心. # 如果希望核心能够装载DSO, ...
- 【文件】使用jacob将word转换成pdf格式
使用jacob将word转换成pdf格式 1.需要安装word2007或以上版本,若安装07版本学确保该版本已安装2downbank0204MicrosoftSaveasPDF_ XPS,否则安装 ...