SQLite 剖析
由于sqlite对多进程操作支持效果不太理想,在项目中,为了避免频繁读写 文件数据库带来的性能损耗,我们可以采用操作sqlite内存数据库,并将内存数据库定时同步到文件数据库中的方法。
实现思路如下:
1、创建文件数据库;
2、创建内存数据库(文件数据库、内存数据库的内部表结构需要一致);
3、在内存数据库中attach文件数据库,这样可以保证文件数据库中的内容在内存数据库中可见;
4、对于insert、select操作,在内存数据库中完成,对于delete、update操作,需要同时访问内存、文件数据库;
5、定时将内存数据库中的内容flush到文件数据库。
一、内存数据库:
在SQLite中,数据库通常是存储在磁盘文件中的。然而在有些情况下,我们可以让数据库始终驻留在内存中。最常用的一种方式是在调用sqlite3_open()的时候,数据库文件名参数传递":memory:",如:
rc = sqlite3_open(":memory:", &db);
在调用完以上函数后,不会有任何磁盘文件被生成,取而代之的是,一个新的数据库在纯内存中被成功创建了。由于没有持久化,该数据库在当前数据库连接被关闭后就会立刻消失。需要注意的是,尽管多个数据库连接都可以通过上面的方法创建内存数据库,然而它们却是不同的数据库,相互之间没有任何关系。事实上,我们也可以通过Attach命令将内存数据库像其他普通数据库一样,附加到当前的连接中,如:
ATTACH DATABASE ':memory:' AS aux1;
二、临时数据库:
在调用sqlite3_open()函数或执行ATTACH命令时,如果数据库文件参数传的是空字符串,那么一个新的临时文件将被创建作为临时数据库的底层文件,如:
rc = sqlite3_open("", &db);
或
ATTACH DATABASE '' AS aux2;
和内存数据库非常相似,两个数据库连接创建的临时数据库也是各自独立的,在连接关闭后,临时数据库将自动消失,其底层文件也将被自动删除。
尽管磁盘文件被创建用于存储临时数据库中的数据信息,但是实际上临时数据库也会和内存数据库一样通常驻留在内存中,唯一不同的是,当临时数据库中数据量过大时,SQLite为了保证有更多的内存可用于其它操作,因此会将临时数据库中的部分数据写到磁盘文件中,而内存数据库则始终会将数据存放在内存中。
sqlite分两种源码结构,一种是比较常见的sqlite3.c 一个文件十几万行代码。另一种是,将各个模块分离出的源码结构。
一、主要分为三部分:
虚拟机(Virtual Machine)
Back-end(后端)
compiler(编译器)
1、虚拟机(Virtual Machine)
2、B-tree和Pager
B-Tree使得VDBE可以在O(logN)下查询,插入和删除数据,以及O(1)下双向遍历结果集。B-Tree不会直接读写磁盘,它仅仅维护着页面(pager)之间的关系。当B-Tree需要页面或者修改页面时,它就会调用Pager。当修改页面时,pager保证原始页面首先写入日志文件,当它完成写操作时,pager根据事务状态决定如何做。B-tree不直接读写文件,而是通过page cache这个缓冲模块读写文件,对于性能是有重要意义的(这和操作系统读写文件类似,在Linux中,操作系统的上层模块并不直接调用设备驱动读写设备,而是通过一个高速缓冲模块调用设备驱动读写文件,并将结果存到高速缓冲区)。
3、编译器(Compiler)
3.1、分词器(Tokenizer)
Tokenizer.c
3.2、分析器(Parser)
SQLite的语法分析器是用Lemon(一个开源的LALR(1)语法分析器的生成器)生成的,生成的文件为parser.c。
3.3、代码生成器(Code Generator)
代码生成器是SQLite中最庞大,最复杂的部分。它与Parser关系紧密,根据语法分析树生成VDBE程序执行SQL语句的功能。
由诸多文件构成:select.c,update.c,insert.c,delete.c,trigger.c,where.c等文件。
这些文件生成相应的VDBE程序指令,比如SELECT语句就由select.c生成。
3.4、查询优化
代码生成器不仅负责生成代码,也负责进行查询优化。
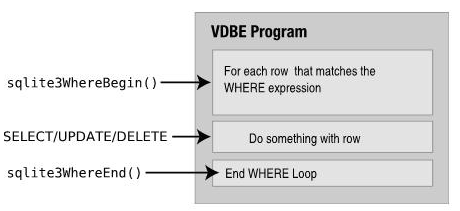
主要的实现位于where.c中,生成的WHERE语句块通常被其它模块共享,比如select.c,update.c以及delete.c。
这些模块调用sqlite3WhereBegin()开始WHERE语句块的指令生成,然后加入它们自己的VDBE代码返回,最后调用sqlite3WhereEnd()结束指令生成。
B树:https://www.cnblogs.com/dongguacai/p/7239599.html
相同数量的key在B树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。这样到达一定数量后,性能的差异就显现出来了。
插入或者删除元素都会导致节点发生裂变反应,有时候会非常麻烦,但正因为如此才让B树能够始终保持多路平衡,这也是B树自身的一个优势:自平衡;
B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现。
sqlite中的锁
就数据库而言,处理的并发实际上分为读并发,写并发,读写并发,我们广义上说的并发实际上指的是读写并发,要了解这些,我们还需要先了解一下sqlite中的锁.
sqlite中一共有五种锁分别是
未加锁(UNLOCKED)
文件没有持有任何锁,即当前数据库不存在任何读或写的操作。其它的进程可以在该数据库上执行任意的读写操作。此状态为缺省状态。
共享锁(SHARED)
在此状态下,该数据库可以被读取但是不能被写入。在同一时刻可以有任意数量的进程在同一个数据库上持有共享锁,因此读操作是并发的。换句话说,只要有一个或多个共享锁处于活动状态,就不再允许有数据库文件写入的操作存在。
保留锁(RESERVED)
假如某个进程在将来的某一时刻打算在当前的数据库中执行写操作,然而此时只是从数据库中读取数据,那么我们就可以简单的理解为数据库文件此时已经拥有了保留锁。当保留锁处于活动状态时,该数据库只能有一个或多个共享锁存在,即同一数据库的同一时刻只能存在一个保留锁和多个共享锁. 需要说明的是update操作 实际上是一个读操作加一个写操作
未决锁(PENDING)
PENDING锁的意思是说,某个进程正打算在该数据库上执行写操作,然而此时该数据库中却存在很多共享锁(读操作),那么该写操作就必须处于等待状态,即等待所有共享锁消失为止,与此同时,新的读操作将不再被允许,以防止写锁饥饿的现象发生。在此等待期间,该数据库文件的锁状态为PENDING,在等到所有共享锁消失以后,PENDING锁状态的数据库文件将在获取排他锁之后进入EXCLUSIVE状态。
排它锁(EXCLUSIVE)
在执行写操作之前,该进程必须先获取该数据库的排他锁。然而一旦拥有了排他锁,任何其它锁类型都不能与之共存。因此,为了最大化并发效率,SQLite将会最小化排他锁被持有的时间总量。
读操作锁变化
了解了sqlite的锁之后 我们再来看针对读写操作,sqlite内部的锁变化

读操作的目的是获取共享锁shared从而来访问数据 那么 在获得共享锁(SHARED)之前
首先检查是否有排它锁(EXCLUSIVE) 如果有 则说明sqlite正在进行写入操作 为保障数据一致 所以无法获取共享锁(SHARED)
如果没有 再检查是否有未决锁(PENDING)如果有 表示当前有准备进行的写操作并阻止共享锁(SHARED)的获取
如果检测不到上述两个锁 将获得共享锁(SHARED) 读取数据 然后释放共享锁
写操作锁变化
对于写操作,写操作的目的是为了获得 排它锁(EXCLUSIVE) 独占数据库从而一致性,其内部锁变化如下

首先 检查数据库是否有保留锁(RESERVED)与排它锁(EXCLUSIVE) 如果有 则说明在此次写操作之前还准备有或者正在进行一次写操作
此时如法获取排它锁(EXCLUSIVE) 如果没有 则获取未决锁(PENDING) 当未决锁(PENDING)获得时,将无法再获取到共享锁(SHARED),也就是说sqlite此时已经不再处理读请求
在持有未决锁(PENDING)期间 将会不断询问内部是否还有共享锁(SHARED)
当等待所有共享锁(SHARED)消失 当所有共享锁(SHARED)消失时 此时锁状态将由未决锁(PENDING)切换至排它锁(EXCLUSIVE)
并写入数据 当排它锁(EXCLUSIVE)激活时 阻止任何类型的其它锁获取 直至写入完毕并释放排它锁(EXCLUSIVE)
总结
最后我们来总结一下
1.当有写操作时,其他读操作会被驳回
2.当有写操作时,其他写操作会被驳回
3.当开启事务时,在提交事务之前,其他写操作会被驳回
4.当开启事务时,在提交事务之前,其他事务请求会被驳回
5.当有读操作时,其他写操作会被驳回
6.读操作之间能够并发执行--------------------- 本文来自 https://blog.csdn.net/zhangsheng_1992/article/details/52598396?utm_source=copy
SQLite 剖析的更多相关文章
- SQLite剖析之存储模型
前言 SQLite作为嵌入式数据库,通常针对的应用的数据量相对于DBMS的数据量小.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这 ...
- SQLite剖析之设计与概念
1.API 由两部分组成: 核心API(core API)和扩展API(extension API). 核心API的函数实现基本的数据库操作:连接数据库.处理SQL.遍历结果集.它也包括一些实用函数, ...
- SQLite剖析之事务处理技术
前言 事务处理是DBMS中最关键的技术,对SQLite也一样,它涉及到并发控制,以及故障恢复等等.在数据库中使用事务可以保证数据的统一和完整性,同时也可以提高效率.假设需要在一张表内一次插入20个人的 ...
- SQLite剖析之编程接口详解
前言 使用过程根据函数大致分为如下几个过程: sqlite3_open() sqlite3_prepare() sqlite3_step() sqlite3_column() sqlite3_fina ...
- SQLite剖析之异步IO模式、共享缓存模式和解锁通知
1.异步I/O模式 通常,当SQLite写一个数据库文件时,会等待,直到写操作完成,然后控制返回到调用程序.相比于CPU操作,写文件系统是非常耗时的,这是一个性能瓶颈.异步I/O后端是SQLit ...
- SQLite剖析之动态内存分配
SQLite通过动态内存分配来获取各种对象(例如数据库连接和SQL预处理语句)所需内存.建立数据库文件的内存Cache.保存查询结果. 1.特性 SQLite内核和它的内存分配子系统提供以下特性 ...
- SQLite剖析之锁和并发控制
在SQLite中,锁和并发控制机制都是由pager.c模块负责处理的,用于实现ACID(Atomic.Consistent.Isolated和Durable)特性.在含有数据修改的事务中,该模块将确保 ...
- SQLite剖析之临时文件、内存数据库
一.7种临时文件 SQLite中,一个数据库由单个磁盘文件构成,简化了SQLite的使用,因为移动或备份数据库只要拷贝单个文件即可.这也使得SQLite适合用作应用程序文件格式.但是,当在单个文 ...
- SQLite剖析之数据类型
许多SQL数据库引擎(除SQLite之外的各种SQL数据库引擎)使用静态.严格的数据类型.对于静态类型,一个值的数据类型由它的容器,即存储这个值的列来决定.SQLite则使用更加通用的动态类型系统.在 ...
- SQLite剖析之C/C++接口
前言 SQLite3是SQLite一个全新的版本,它虽然是在SQLite2的代码基础之上开发的,但是使用了和之前的版本不兼容的数据库格式和API.SQLite3是为了满足以下的需求而开发的:支持UTF ...
随机推荐
- python相对目录的基本用法(一)
一般在代码中涉及到操作文件时,最好使用文件的相对目录,这样在你的程序迁移到别人的电脑时,可以保证不会出现文件读取异常的错误(另外,自动化测试时用例的读取也要用相对目录) 例子1 假如工程文件的目录结构 ...
- 混合线性模型(linear mixed models)
一般线性模型.混合线性模型.广义线性模型 广义线性模型GLM很简单,举个例子,药物的疗效和服用药物的剂量有关.这个相关性可能是多种多样的,可能是简单线性关系(发烧时吃一片药退烧0.1度,两片药退烧0. ...
- android--------自定义控件 之 基本流程篇
在我们平常的Android开发中经常和控件打交道,有时Android提供的控件未必能满足业务的需求,这个时候就需要我们实现自定义一些控件 自定义控件可以设计出很多你想要的功能和模块,在开发中是很重要的 ...
- MyEclipse6.5的SVN插件的安装
在线安装 1. 打开Myeclipse,在菜单栏中选择Help→Software Updates→Find and Install; 2. 选择Search for new features to i ...
- es-aggregations聚合分析
聚合分析的格式: "aggregations" : { "<aggregation_name>" : { "<aggregation ...
- 阻止ajax缓存方法
通过添加meta标签 <meta http-equiv= "pragma" content= "no-cache"/> (pragma: 杂注) & ...
- 2017-2018 ACM-ICPC, NEERC, Northern Subregional ContestG - Grand Test
题意:找三条同起点同终点的不相交的路径 题解:用tarjan的思想,记录两个low表示最小和次小的dfs序,以及最小和次小的位置,如果次小的dfs序比dfn小,那么说明有两条返祖边,那么就是满足条件的 ...
- HDu4794 斐波那契循环节
题意:Arnold变换把矩阵(x,y)变成((x+y)%n,(x+2*y)%n),问最小循环节 题解:仔细算前几项能看出是斐波那契数论modn,然后套个斐波那契循环节板子即可 //#pragma GC ...
- 【PowerDesigner】【8】把Comment复制到name中和把name复制到Comment
原因:这两个字段的值很多时候其实是一样的,重写很麻烦 步骤:打开菜单Tools>Execute Commands>Edit/Run Script.. 或者用快捷键 Ctrl+Shift+X ...
- leetcode-algorithms-23 Merge k Sorted Lists
leetcode-algorithms-23 Merge k Sorted Lists Merge k sorted linked lists and return it as one sorted ...