Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
arXiv
摘要:本文提出了一种 DRL 算法进行单目标跟踪,算是单目标跟踪中比较早的应用强化学习算法的一个工作。
在基于深度学习的方法中,想学习一个较好的 robust spatial and temporal representation for continuous video data 是非常困难的。
尽管最近的 CNN based tracker 也取得了不错的效果,但是,其性能局限于:
1. Learning robust tracking features ;
2. maximizing long-term tracking performance ---->>> without taking coherency and correlation into account.
本文的创新点在于:
1. 提出一种 convolutional recurrent neural network model, 可以学习到单帧图像的空间表示 以及 多帧图像之间的时序上的表示;
得到的特征可以更好的捕获 temporal information,并且可以直接应用到跟踪问题上;
2. 我们的框架是端到端的进行训练的 deep RL algorithm,模型的目标是最大化跟踪性能;
3. 模型完全是 off-line的;
Tracking Framework :
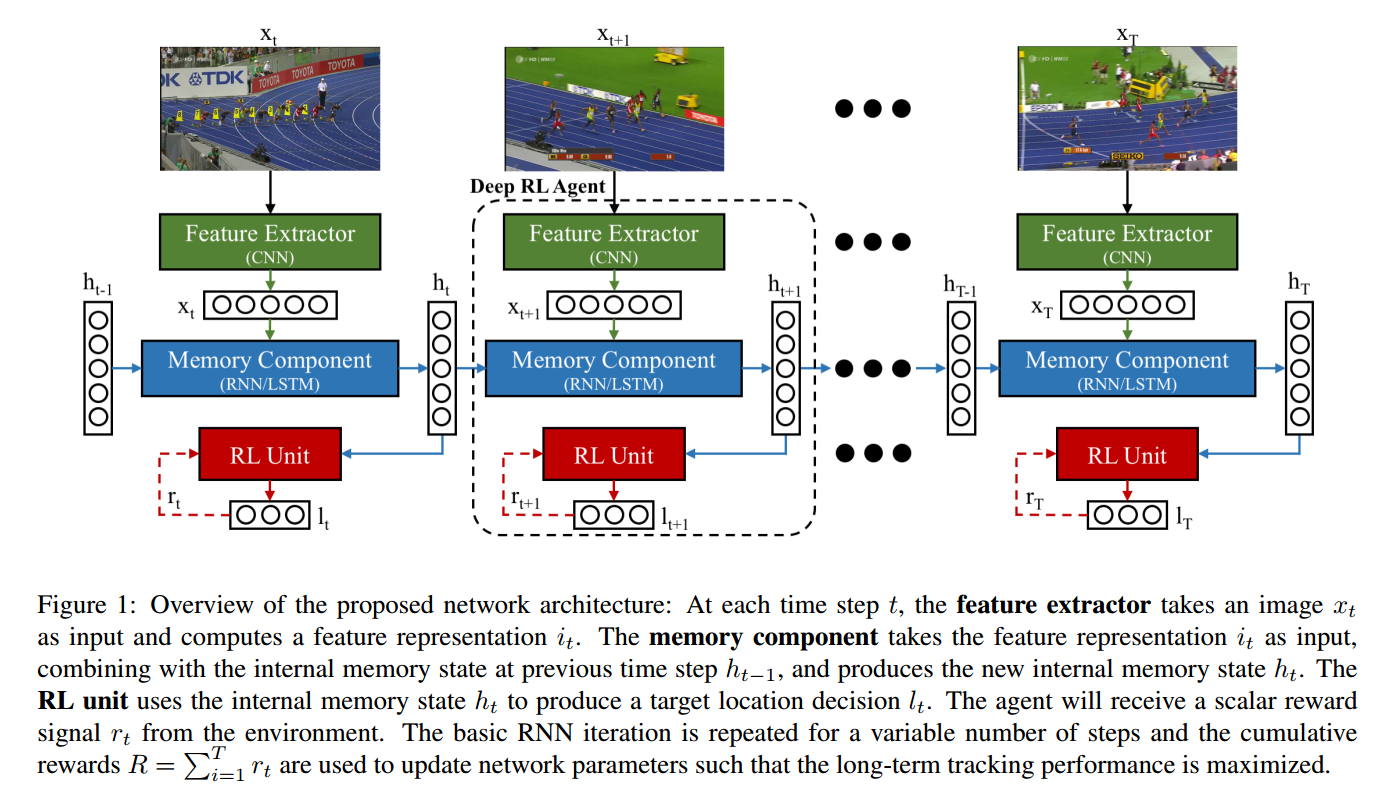
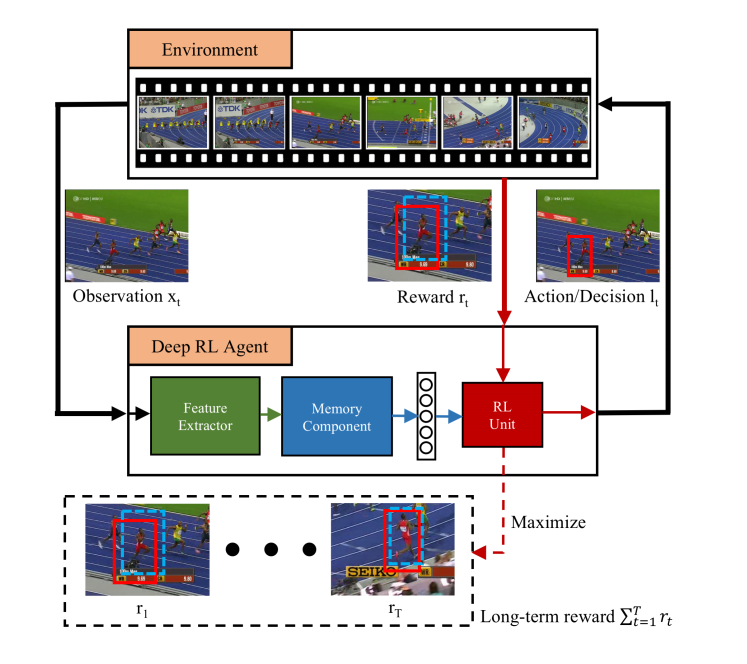
本文提出的 Deep RL 算法框架,由三个部分构成:
1 CNN 特征提取部分;
2 RNN 历史信息构建部分;
3 DEEP RL 模块
前两个部分没什么要说的,就是简单的 CNN, LSTM 结构。
第三个 RL 部分:
说到底,这个文章是在之前 attention model based Tracker ICLR 2016 年的一个文章基础上做的。
RL 部分就是没有变换,直接挪过来的。
状态,是跟踪视频的 frame ;
动作,是 多变量高斯分布得到的 predicted location;
奖励,是 scalar reward signal, 定义为:$r_t = -avg(l_t - g_t) - max(l_t - g_t)$ ,lt 是RL单元的输出,gt 是时刻 t 的 gt ;
avg() 是给定矩阵的 mean value; max() 是计算给定元素的最大值。
训练的目标是最大化奖励信号 R。
学习的目标函数为:
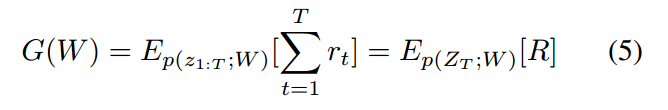
其中,p(z1:T; W) 是可能交互的分布,参数化为 W (the distribution over possible interactions parameterized by W).
上述函数涉及到 an expectation over high-dimensional interactions,以传统的监督方法来解决是非常困难的。
利用 RL 领域中的 REINFORCE algorithm 进行近似求解。

Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记的更多相关文章
- Online Object Tracking: A Benchmark 论文笔记(转)
转自:http://blog.csdn.net/lanbing510/article/details/40411877 有博主翻译了这篇论文:http://blog.csdn.net/roamer_n ...
- Online Object Tracking: A Benchmark 论文笔记
Factors that affect the performance of a tracing algorithm 1 Illumination variation 2 Occlusion 3 Ba ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking 2019-07-30 14:55:31 Paper: http ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- 论文阅读之: Hierarchical Object Detection with Deep Reinforcement Learning
Hierarchical Object Detection with Deep Reinforcement Learning NIPS 2016 WorkShop Paper : https://a ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
随机推荐
- 05 enumerate index使用
# enumerate 自动生成一列, 默认0开始,每次自增+1li = ["电脑","鼠标垫","U盘","游艇"]f ...
- Maven的配置指南
Maven的配置指南 配置Maven Maven配置发生在3个级别: 项目 - 大多数静态配置发生在pom.xml中 安装 - 这是Maven安装时发生的一次性的配置过程 用户 - 这是Maven提 ...
- [博客迁移]探索Windows Azure 监控和自动伸缩系列1 - 连接中国区Azure
最近准备基于Microsoft Azure Management Libraries 实现虚拟机的监控.主要的需求就是获取虚拟机内置的性能计数器数据,基于性能计数器实现后续的监控和自动伸缩. 作为这一 ...
- 【Oozie学习之一】Oozie
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 CM5.4 一.简介Oozie由Cloudera公司贡献给A ...
- 【Linux学习六】用户管理
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 一.增加删除用户或组新增用户useradd scott修改用户密码pa ...
- python mmap对象
----使用内存映射的原因 为了随机访问文件的内容,使用mmap将文件映射到内存中是一个高效和优雅的方法.例如,无需打开一个文件并执行大量的seek(),read(),write()调用,只需要简单的 ...
- maven的profile详解
详细内容请见:https://www.cnblogs.com/wxgblogs/p/6696229.html Profile能让你为一个特殊的环境自定义一个特殊的构建:profile使得不同环境间构建 ...
- 在hue中使用hive
一.创建新表 建表语句如下: CREATE TABLE IF NOT EXISTS user_collection_9( user_id string , seller_id string , pro ...
- [转载] Web Service工作原理及实例
一.Web Service基本概念 Web Service也叫XML Web Service WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求, ...
- pytest+request 接口自动化测试
1.安装python3brew update brew install pyenv 然后在 .bash_profile 文件中添加 eval “$(pyenv init -)” pyenv insta ...