python调用caffe实现预测
对于已经训练完成的caffemodel,对于单个的图片预测,用python接口来调用是一件非常方便的事情,下面就来讲述如何用python调用已经训练完成的caffemodel,以及prototxt,网上关于这一方面的教程已经是比较多的了,但是我想针对我做的过程发现的一些问题做一个总结
,先给出几个用python调用caffemodel的链接,链接1,链接2,链接3,主要是参考链接1的内容,整体代码如下,
#coding=utf-8
import sys
import numpy as np
import cv2
from glob import glob
from tqdm import tqdm
caffe_root = '/usr/local/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
import multiprocessing model_file = '/home/ying/data2/shiyongjie/mpc/res50/acc/resnet_50_deploy.prototxt' # deploy文件
pretrained = '/home/ying/data2/shiyongjie/mpc/res50/acc/model_iter_280000.caffemodel' # 训练的caffemodel
image_file = '/home/ying/data2/shiyongjie/mpc/coal_data/0/output/0_ffff4083-a13a-4e62-9870-59cd70709f7c.JPEG'
mean_file = '/home/ying/data2/shiyongjie/mpc/coal_data/mean_train.npy'
net = caffe.Net(model_file, pretrained, caffe.TEST) #加载model和network #图片预处理设置
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式(1,3,28,28)
transformer.set_transpose('data', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) #减去均值,前面训练模型时没有减均值,这儿就不用
transformer.set_raw_scale('data', 255) # 缩放到【0,255】之间
transformer.set_channel_swap('data', (2,1,0)) #交换通道,将图片由RGB变为BGR print('#$%^&#@*!')
image_file_list = glob('/home/ying/data2/shiyongjie/mpc/coal_data/0/output/*JPEG') # 列出目录下的所有jpeg图片
image_file_list.sort()
image_file_list = image_file_list[:len(image_file_list)/2] # 速度预测非常慢,将list拆分
# pool = multiprocessing.Pool(processes = 4)
results = []
for image_file in tqdm(image_file_list): # tqdm显示进度条
im = caffe.io.load_image(image_file)
net.blobs['data'].data[...] = transformer.preprocess('data', im) #执行上面设置的图片预处理操作,并将图片载入到blob中
out = net.forward()
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
results.append(top_k[0]) # 将预测的结果保存到results中
# print(top_k[0])
# for i in np.arange(top_k.size):
# print top_k[i]
acc0 = float(results.count(0))/float(len(image_file_list)) # 计算预测四类结果的概率
acc1 = float(results.count(1))/float(len(image_file_list))
acc2 = float(results.count(2))/float(len(image_file_list))
acc3 = float(results.count(3))/float(len(image_file_list))
print(acc0, acc1, acc2, acc3)
这里其实有很多细节的问题,先给自己挖个坑,主要有,deploy文件与一般的train_val.prototxt文件有些许不同,看上面第三个链接,他们加载prototxt的是lenet.prototxt,去caffe/example/mnist/lenet.prototxt查看这个文件,如下

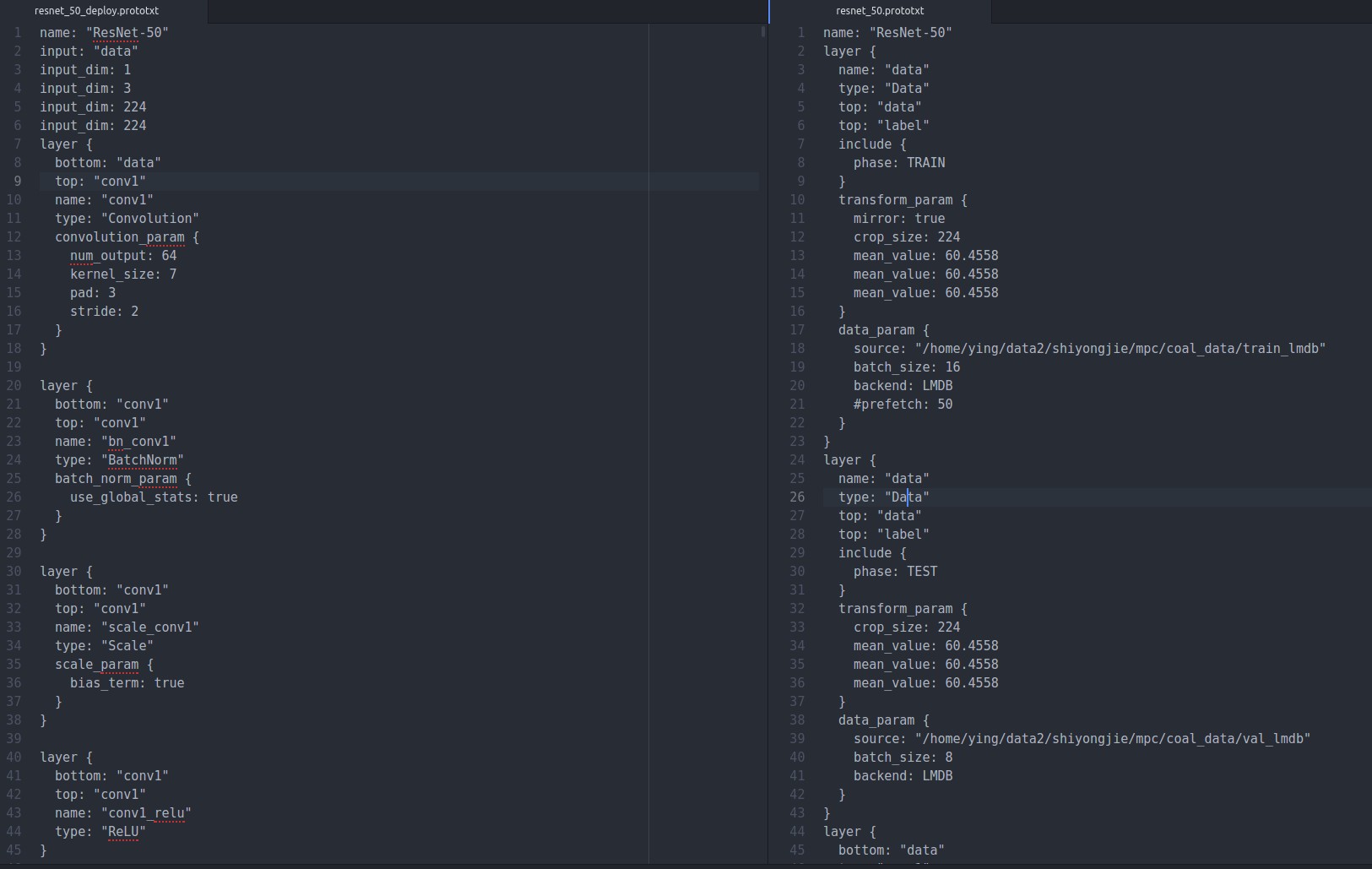
实际上左边是deploy的,右边是train_val的,可以看出左右的区别就是地一层,右边train和test都是data层,左边是input层,其余全都一样,所以deploy也是很有讲究的,mnist是在训练的时候就没有减去均值,测试的时候加载均值文件在python内部写,见上述代码
实际上,我测试用的deploy与mnist又有些许不同,如下
同时修改最后一行
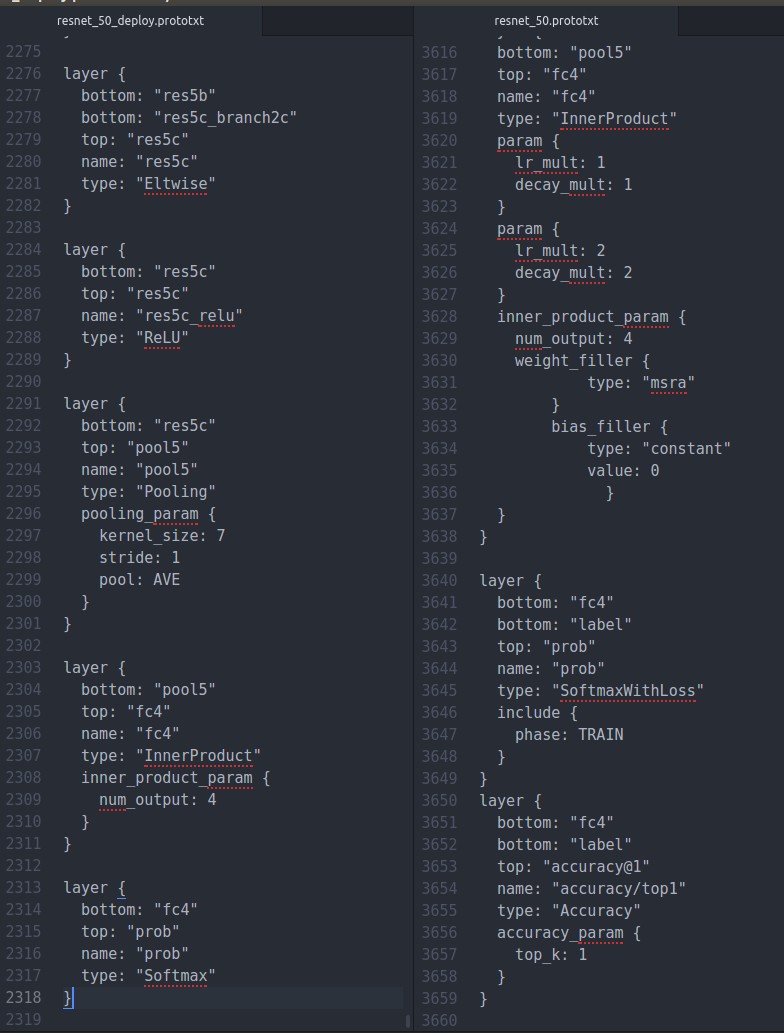
我用的resnet基本上lr以及权重初始化的参数都已经取消了,最后一个name用prob,测试的时候输出的是预测为每一类的概率,在python最后的输出net.blobs['prob']也能够看出,感觉是个字典,给自己挖个坑
可以看出,deploy文件与train_val文件是有很大的不同的,这种不同可能与平台无关,在python是这样,在c++也可能是这样
但是用python调用速度非常慢,这样说吧,5w张图片要6个小时,速度相当慢,我一个同学,用c++调用同样的caffemodel200张图片,0.4s,5w张图片100s就搞定
python调用caffe实现预测的更多相关文章
- python调用caffe环境配置
背景是这样的,项目需要,必须将训练的模型通过C++进行调用,所以必须使用caffe或者mxnet,而caffe是用C++实现,所以有时候简单的加载一张图片然后再进行预测十分不方便 用caffe写pro ...
- torch7 调用caffe model 作为pretrain
torch7 调用caffe model 作为pretrain torch7 caffe preTrain model zoo torch7 通过 loadcaffe 包,可以调用caffe训练得到的 ...
- python调用.so
python调用动态链接库的基本过程 动态链接库在Windows中为.dll文件,在linux中为.so文件.以linux平台为例说明python调用.so文件的使用方法. 本例中默认读者已经掌握动态 ...
- 【转】Python调用C语言动态链接库
转自:https://www.cnblogs.com/fariver/p/6573112.html 动态链接库在Windows中为.dll文件,在linux中为.so文件.以linux平台为例说明py ...
- Python调用Prometheus监控数据并计算
Prometheus是什么 Prometheus是一套开源监控系统和告警为一体,由go语言(golang)开发,是监控+报警+时间序列数 据库的组合.适合监控docker容器.因为kubernetes ...
- 【初学python】使用python调用monkey测试
目前公司主要开发安卓平台的APP,平时测试经常需要使用monkey测试,所以尝试了下用python调用monkey,代码如下: import os apk = {'j': 'com.***.test1 ...
- python调用py中rar的路径问题。
1.python调用py,在py中的os.getcwd()获取的不是py的路径,可以通过os.path.split(os.path.realpath(__file__))[0]来获取py的路径. 2. ...
- python调用其他程序或脚本方法(转)
python运行(调用)其他程序或脚本 在Python中可以方便地使用os模块运行其他的脚本或者程序,这样就可以在脚本中直接使用其他脚本,或者程序提供的功能,而不必再次编写实现该功能的代码.为了更好地 ...
- python调用c\c++
前言 python 这门语言,凭借着其极高的易学易用易读性和丰富的扩展带来的学习友好性和项目友好性,近年来迅速成为了越来越多的人们的首选.然而一旦拿python与传统的编程语言(C/C++)如来比较的 ...
随机推荐
- 七、持久层框架(MyBatis)
一.MyBatis学习 平时我们都用JDBC访问数据库,除了自己需要写SQL,还要操作Connection,Statement,ResultSet这些. 使用MyBatis,只需要自己提供SQL语句, ...
- xinetd黑/白名单配置教程(以telnet为例)
对于诸如telnet等托管于xinetd的服务,当请求到来时由于是通过xinetd进行通知,所以可以直接在xinetd上配置白名单允许和拒绝哪些ip连接服务. 本文主要参考xinetd.conf的ma ...
- git找回本地误删的文件
不小心把本地的文件删除了一个? 想从仓库git pull 下拉? 对不起,这是不行的,虽然不知道为什么,但是我告诉你怎么回复这个文件. 首先,我们先用git status 看看工作区的变化 $ git ...
- eclipse安装scala环境
1.安装eclipse插件,依次点击Help->Eclipse Marketplace 2.输入scala,点击go,进行搜索 3,出现了Scala IDE4.7X,点击右下方的Install进 ...
- Java并发编程(五)JVM指令重排
我是不是学了一门假的java...... 引言:在Java中看似顺序的代码在JVM中,可能会出现编译器或者CPU对这些操作指令进行了重新排序:在特定情况下,指令重排将会给我们的程序带来不确定的结果.. ...
- EventBus简单封装
前言 以前每个页面与每个页面业务逻辑传递让你不知所措,一个又一个接口回调,让你晕头转向,一个又一个参数让你混乱不堪.EventBus一个耦合度低的让你害怕的框架. 什么是EventBus EventB ...
- FFmpeg点播慢的最终方案
转载: 音视频交流群 发的一个总结. 原作者 请查看相关博客作者 http://blog.51cto.com/fengyuzaitu/2061036 场景要求 项目要求点播速度是300到500毫秒 ...
- JS--label语句的使用
使用label语句可以在代码中添加标签,以便将来使用. 一般与for循环一起使用 如: var num = 0; outermost: for(var i=0;i<10;i++){ for(va ...
- 《Java面向对象编程》
<Java面向对象编程> 第11章 对象的生命周期 11.1 创建对象的方式 用new语句创建对象 运用反射手段,调用java.lang.Class 或者 java.lang.Const ...
- jquery 共用函数
ready()方法 $(doxument).ready(fucntion(){ }) $().ready(function(){ }) $(function(){ }) 当文档加载后激活函数: ...