Calcite - StreamingSQL
https://calcite.apache.org/docs/stream.html
Calcite’s SQL is an extension to standard SQL, not another ‘SQL-like’ language. The distinction is important, for several reasons:
- Streaming SQL is easy to learn for anyone who knows regular SQL.
- The semantics are clear, because we aim to produce the same results on a stream as if the same data were in a table.
- You can write queries that combine streams and tables (or the history of a stream, which is basically an in-memory table).
- Lots of existing tools can generate standard SQL.
If you don’t use the STREAM keyword, you are back in regular standard SQL.
只是对于标准sql的扩展,StreamingSQL只是多个Stream关键词
An example schema
Our streaming SQL examples use the following schema:
Orders (rowtime, productId, orderId, units)- a stream and a tableProducts (rowtime, productId, name)- a tableShipments (rowtime, orderId)- a stream
以简单的订单,商品,发货为例子
可以看到这里可以同时处理,流式表和静态表;对于order即是流式表也是静态表,意思是实时数据在流式表中,而历史数据在静态表中
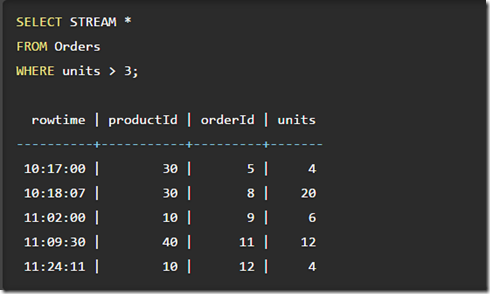
简单的加上STREAM就可以对流式表Orders进行查询,结果是unbounded的;如果不带STREAM就是对静态表进行查询,结果是bounded
Windows支持
- tumbling window (GROUP BY)
- hopping window (multi GROUP BY)
- sliding window (window functions)
- cascading window (window functions)
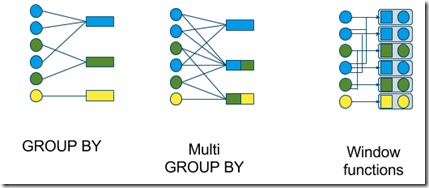
Tumbling windows
在sql中,所谓window就是对于时间的group
比如下面的例子,以小时为时间窗口
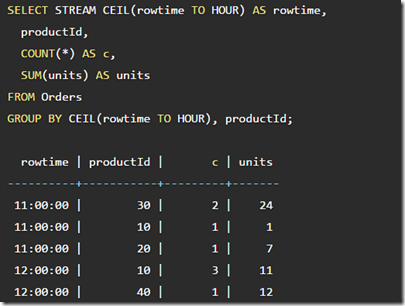
How did Calcite know that the 10:00:00 sub-totals were complete at 11:00:00, so that it could emit them? It knows that rowtime is increasing, and it knows that CEIL(rowtime TO HOUR) is also increasing. So, once it has seen a row at or after 11:00:00, it will never see a row that will contribute to a 10:00:00 total.
A column or expression that is increasing or decreasing is said to bemonotonic.
有个问题是如何知道11点之前的数据都已经到,这个取决于rowtime是单调递增的
所以对于group by时,必须要有一个column是单调递增的,monotonic
If column or expression has values that are slightly out of order, and the stream has a mechanism (such as punctuation or watermarks) to declare that a particular value will never be seen again, then the column or expression is said to be quasi-monotonic.
当然rowtime可能不是严格单调的,所以我们可以用watermark来限定一个时间段,在这个时间范围上是单调的;这样称为quasi-monotonic,拟单调
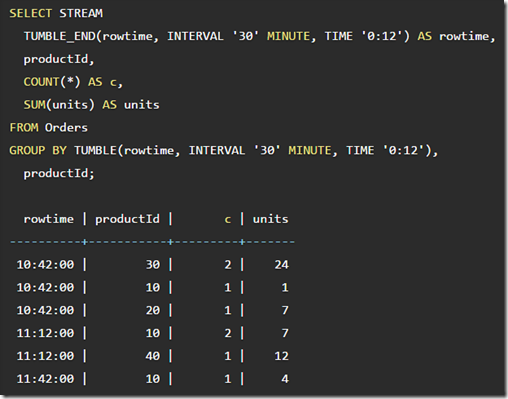
更优雅些,我们可以使用TUMBLE关键字
上面的例子是30分钟的时间窗口,但是非整点,而是有12分钟的偏移,alignment time
Hopping windows
Hopping windows are a generalization of tumbling windows that allow data to be kept in a window for a longer than the emit interval.
其实就是滑动窗口
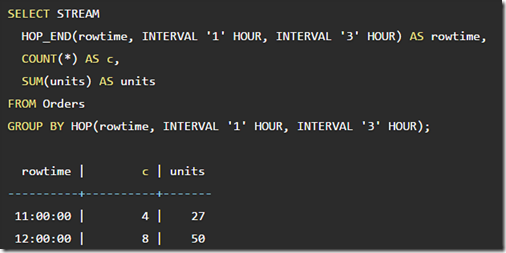
以1小时为滑动,3小时为窗口大小
HAVING
聚合后的过滤
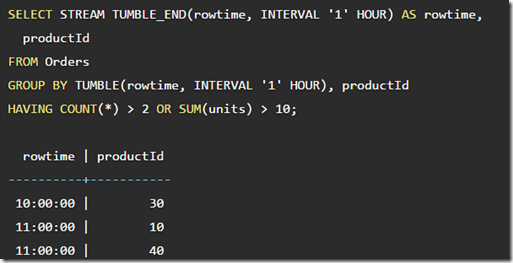
Sliding windows
非groupby方式的sliding windows,
Standard SQL features so-called “analytic functions” that can be used in the SELECT clause.
Unlike GROUP BY, these do not collapse records. For each record that goes in, one record comes out. But the aggregate function is based on a window of many rows.
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour
FROM Orders;
这个和groupby的区别在于,窗口触发的时机
对于groupby,时间整点触发,会将窗口里records计算成一个值
而OVER,是record by record,每来一条record都会触发一次计算,上面的例子是,对每条record都会触发一次前一个小时的sum
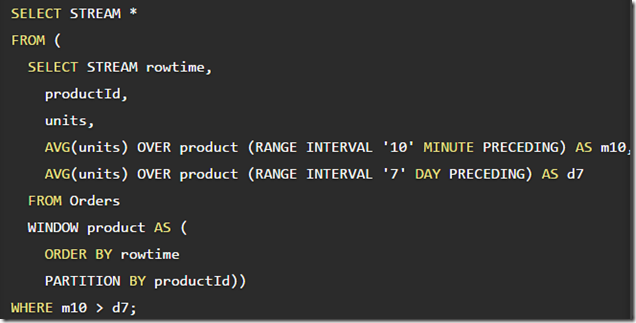
这里更加复杂,
先声明Window product,表示order by rowtime,partition by productId
再基于product,OVER生成7天和10分钟的AVG(units)
子查询
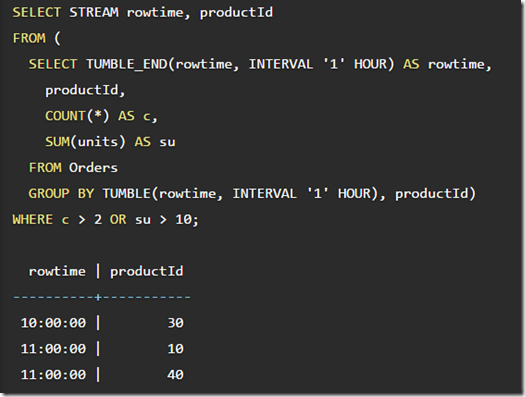
The previous HAVING query can be expressed using a WHERE clause on a sub-query:
having也可以实现成子查询的形式
Since then, SQL has become a mathematically closed language, which means that any operation you can perform on a table can also perform on a query.
The closure property of SQL is extremely powerful. Not only does it render HAVING obsolete (or, at least, reduce it to syntactic sugar), it makes views possible:
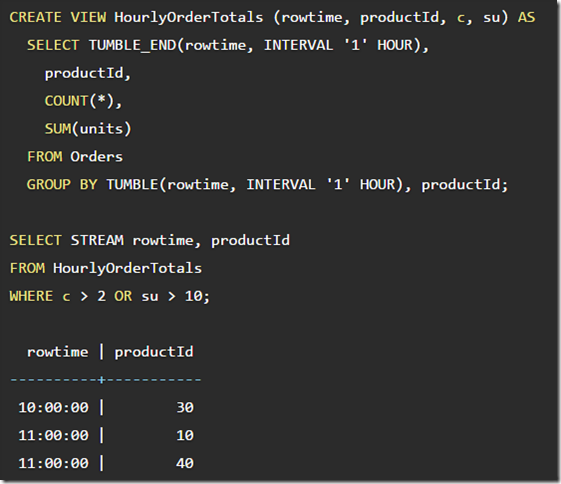
sql具有闭合特性,即任何可以在table上执行的操作,也同样可以在query上执行,因为query的结果也是一个关系表
所以上面通过create view创建子查询
Many people find that nested queries and views are even more useful on streams than they are on relations.
Streaming queries are pipelines of operators all running continuously, and often those pipelines get quite long. Nested queries and views help to express and manage those pipelines.
嵌套查询对于Streaming非常有用,因为流其实就是一组operators的pipelines;以嵌套查询或view的方式去表示会很方便
And, by the way, a WITH clause can accomplish the same as a sub-query or a view:
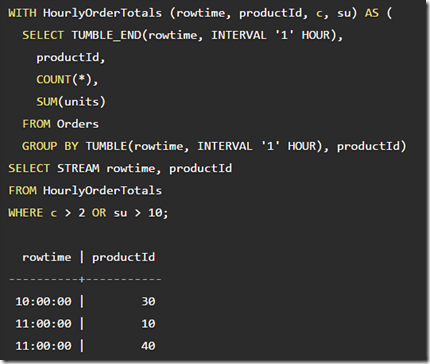
With关键词,用于实现子查询或view
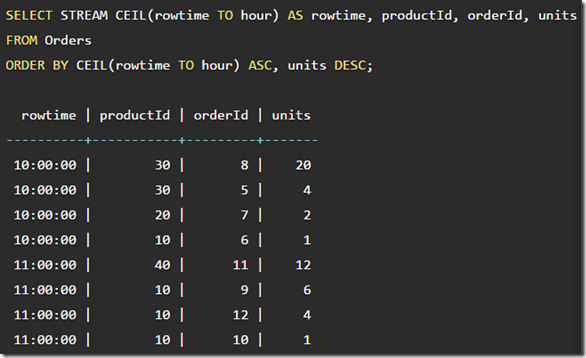
Sorting
Joining streams to tables
A stream-to-table join is straightforward if the contents of the table are not changing.
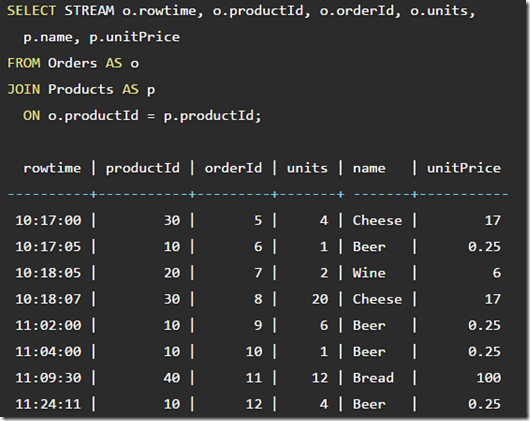
这个很直接,但有个问题是,静态表是会变化的,当数据record流过来时,我们需要和record发生时静态表做join,但如果静态表已经变化了,我们只能取到最新值
要解决这个问题,我们需要为静态表,创建版本表,保存每个时间的版本
One way to implement this is to have a table that keeps every version with a start and end effective date, ProductVersions in the following example:
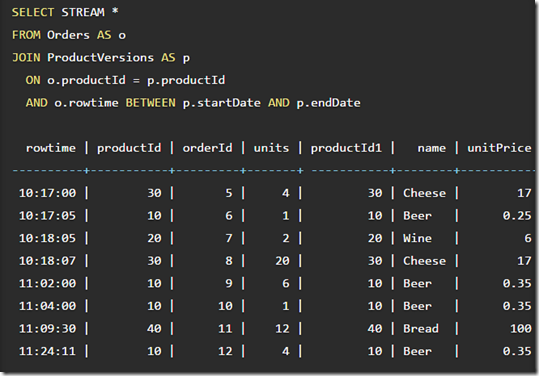
当前会从productVersion里面,根据record rowtime找出包含这个时间的版本
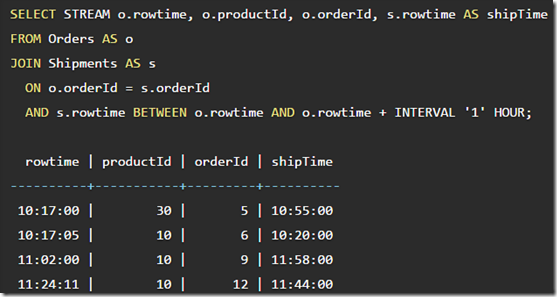
Joining streams to streams
DML
It’s not only queries that make sense against streams; it also makes sense to run DML statements (INSERT, UPDATE, DELETE, and also their rarer cousins UPSERT and REPLACE) against streams.
DML is useful because it allows you do materialize streams or tables based on streams, and therefore save effort when values are used often.
Calcite - StreamingSQL的更多相关文章
- kylin(二): Calcite
Apache Calcite是面向Hadoop新的查询引擎,它提供了标准的SQL语言.多种查询优化和连接各种数据源的能力,除此之外,Calcite还提供了OLAP和流处理的查询引擎.Calcite之前 ...
- calcite 理论
https://blog.csdn.net/yunlong34574/article/details/46375733 https://cloud.tencent.com/developer/arti ...
- Flink SQL与 SQL Parser ,calcite
http://vinoyang.com/2017/06/12/flink-table-sql-source/ Flink Table&Sql 如何结合Apache Calcite http:/ ...
- calcite介绍
前言 calcite是一个可以将任意数据查询转换成基于sql查询的引擎,引擎特性也有很多,比如支持sql树的解析,udf的扩展,sql执行优化器的扩展等等.目前已经被很多顶级apache项目引用,比如 ...
- Flink table&Sql中使用Calcite
Apache Calcite是什么东东 Apache Calcite面向Hadoop新的sql引擎,它提供了标准的SQL语言.多种查询优化和连接各种数据源的能力.除此之外,Calcite还提供了OLA ...
- Apache顶级项目 Calcite使用介绍
什么是Calcite Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功能,比如SQL解析.SQL校验.SQL查询优化.SQL生成以及数据连接查询等,但是又省略了一些 ...
- Apache Calcite项目简介
文章导读: 什么是Calcite? Calcite的主要功能? 如何快速使用Calcite? 什么是Calcite Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功 ...
- Calcite分析 - RelTrait
RelTrait 表示RelNode的物理属性 由RelTraitDef代表RelTrait的类型 /** * RelTrait represents the manifestation of a r ...
- Calcite分析 - Rule
Calcite源码分析,参考: http://matt33.com/2019/03/07/apache-calcite-process-flow/ https://matt33.com/2019/03 ...
随机推荐
- 在Vue项目中使用vw实现移动端适配
有关于移动端的适配布局一直以来都是众说纷纭,对应的解决方案也是有很多种.在<使用Flexible实现手淘H5页面的终端适配>提出了Flexible的布局方案,随着viewport单位越来越 ...
- 根据元素类型获取tuple中的元素
最近做cinatra遇到这样的需求,根据一个type来获取对应的第一个元素,需要注意的一个问题是,如果没有这个类型的时候,通过编译期断言提醒使用者,实现代码如下: 1.C++14实现 template ...
- golang:slice切片
一直对slice切片这个概念理解的不是太透彻,之前学习python的就没搞清楚,不过平时就用python写个工具啥的,也没把这个当回事去花时间解决. 最近使用go开发又遇到这个问题,于是打算彻底把这个 ...
- 【iCore4 双核心板_ARM】例程十:RTC实时时钟实验——显示时间和日期
实验现象: 核心代码: int main(void) { /* USER CODE BEGIN 1 */ RTC_TimeTypeDef sTime; RTC_DateTypeDef sDate; ; ...
- Go Revel - Jobs(任务调度模块)
revel提供了一个框架用于脱离请求流程的执行异步任务,一般用来执行经常运行的任务.更新缓存数据或发送邮件等. ##启用 该框架作为一个可选的revel模块,默认并不启用.需要更改应用配置来启用它: ...
- Java知多少(95)绘图基础
要在平面上显示文字和绘图,首先要确定一个平面坐标系.Java语言约定,显示屏上一个长方形区域为程序绘图区域,坐标原点(0,0)位于整个区域的左上角.一个坐标点(x,y)对应屏幕窗口中的一个像素,是整数 ...
- Why you should use async tasks in .NET 4.5 and Entity Framework 6
Improve response times and handle more users with parallel processing Building a web application usi ...
- CLOS网络的无阻塞条件
交换单元及网络 模拟信号数字化和时分复用基础 交换单元模型基本交换单元 交换网络 2.1模拟信号数字化和分时复用基础 模拟信号是指在是和幅度数值上连续变化的信号 数字信号是指在时间和幅度取值上离散的编 ...
- Scala学习笔记——简化代码、柯里化、继承、特质
1.简化代码 package com.scala.first import java.io.File import javax.management.Query /** * Created by co ...
- Python 中的map、reduce函数用法
#-*- coding:UTF-8 -*- #map()函数接受两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回 def f(x): retu ...