Spark算子之aggregateByKey详解
一、基本介绍
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
二、源码
三、代码
from pyspark import SparkConf,SparkContext
from __builtin__ import str
conf = SparkConf().setMaster("local").setAppName("AggregateByKey")
sc = SparkContext(conf = conf) rdd = sc.parallelize([(,),(,),(,),(,),(,),(,)],) def f(index,items):
print "partitionId:%d" %index
for val in items:
print val
return items rdd.mapPartitionsWithIndex(f, False).count() def seqFunc(a,b):
print "seqFunc:%s,%s" %(a,b)
return max(a,b) #取最大值
def combFunc(a,b):
print "combFunc:%s,%s" %(a ,b)
return a + b #累加起来
'''
aggregateByKey这个算子内部肯定有分组
'''
aggregateRDD = rdd.aggregateByKey(, seqFunc, combFunc)
rest = aggregateRDD.collectAsMap()
for k,v in rest.items():
print k,v sc.stop()
四、详细逻辑
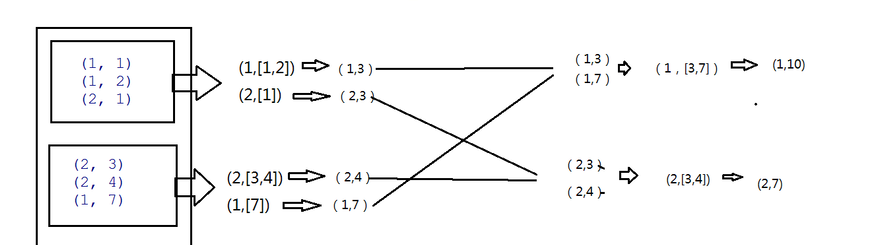
PS:seqFunc函数 combine篇。
3是每个分组的最大值,所以把3传进来,在combine函数中也就是seqFunc中第一次调用 3代表a,b即1,max(a,b)即3 第二次再调用则max(3.1)中的最大值3即输入值,2即b值 所以结果则为(1,3)
底下类似。combine函数调用的次数与分组内的数据个数一致。
combFunc函数 reduce聚合
在reduce端大聚合,拉完数据后也是先分组,然后再调用combFunc函数
五、结果

Spark算子之aggregateByKey详解的更多相关文章
- Spark算子篇 --Spark算子之aggregateByKey详解
一.基本介绍 rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值 3代表每次分完组之后的每个组的初始值. seqFunc代表combine的聚合逻 ...
- Spark算子篇 --Spark算子之combineByKey详解
一.概念 rdd.combineByKey(lambda x:"%d_" %x, lambda a,b:"%s@%s" %(a,b), lambda a,b:& ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- Spark中的分区方法详解
转自:https://blog.csdn.net/dmy1115143060/article/details/82620715 一.Spark数据分区方式简要 在Spark中,RDD(Resilien ...
- Spark技术内幕: Shuffle详解(一)
通过上面一系列文章,我们知道在集群启动时,在Standalone模式下,Worker会向Master注册,使得Master可以感知进而管理整个集群:Master通过借助ZK,可以简单的实现HA:而应用 ...
- Spark操作—aggregate、aggregateByKey详解
https://blog.csdn.net/u013514928/article/details/56680825 1. aggregate函数 将每个分区里面的元素进行聚合,然后用combine函数 ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
随机推荐
- play mp3 in c#
using System; using System.Runtime.InteropServices; using System.Text; using System.IO; using System ...
- day_10 py 字典
#!/usr/bin/env/python#-*-coding:utf-8-*-'''字典: (就是增加个索引名字,然后归类了一下) infor = {键:值,键:值} 列表存储相同的信息随着列表里面 ...
- ubuntu部署安装 MySQL 5.7
安装 MySQL 5.7安装 MySQL 运行命令: apt-get -y install mysql-server mysql-client 你会被要求提供MySQL的root用户密码 : New ...
- dts中memreserve和reserved-memory的区别 (转)
https://blog.csdn.net/kickxxx/article/details/54631535
- PAT甲级1055 The World's Richest【排序】
题目:https://pintia.cn/problem-sets/994805342720868352/problems/994805421066272768 题意: 给定n个人的名字,年龄和身价. ...
- 搭桥|codevs1002|最小生成树|Prim|并查集|Elena
1002 搭桥 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题目描述 Description 有一矩形区域的城市中建筑了若干建筑物,如果某两个单元格有一个点 ...
- php实现简单消息发送+极光推送系统
前几天刚写完的一个东西,写的比较简单,没有使用其他插件,原生php+计划任务实现 极光推送的代码 /* $receiver="registration_id" : [ " ...
- 使用 Markdown 写技术博客,踩过的 6个坑
目录 Markdown 特性 Markdown 简介 常用语法 为什么流行 设计哲学 工具支持 版本演进 标准化之路 踩过了坑 平台帮助文档 语法差异 显示效果 我的最佳实践 摘要:本文记录我在使用 ...
- I do think I can breakdown the problem into parts that make sense
RESTful Web APIs_2013 An API released today will be named after the company that hosts it. We talk a ...
- Linux之sed、awk
Linux 之AWK 命令 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在对数据分析并生成报告时,显得尤为强大. 简单来说awk就是把文件逐行的读入,以空格默认分隔 ...