Spark算子之aggregateByKey详解
一、基本介绍
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
二、源码
三、代码
from pyspark import SparkConf,SparkContext
from __builtin__ import str
conf = SparkConf().setMaster("local").setAppName("AggregateByKey")
sc = SparkContext(conf = conf) rdd = sc.parallelize([(,),(,),(,),(,),(,),(,)],) def f(index,items):
print "partitionId:%d" %index
for val in items:
print val
return items rdd.mapPartitionsWithIndex(f, False).count() def seqFunc(a,b):
print "seqFunc:%s,%s" %(a,b)
return max(a,b) #取最大值
def combFunc(a,b):
print "combFunc:%s,%s" %(a ,b)
return a + b #累加起来
'''
aggregateByKey这个算子内部肯定有分组
'''
aggregateRDD = rdd.aggregateByKey(, seqFunc, combFunc)
rest = aggregateRDD.collectAsMap()
for k,v in rest.items():
print k,v sc.stop()
四、详细逻辑
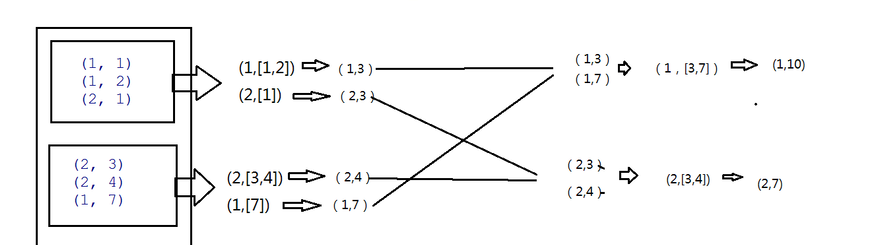
PS:seqFunc函数 combine篇。
3是每个分组的最大值,所以把3传进来,在combine函数中也就是seqFunc中第一次调用 3代表a,b即1,max(a,b)即3 第二次再调用则max(3.1)中的最大值3即输入值,2即b值 所以结果则为(1,3)
底下类似。combine函数调用的次数与分组内的数据个数一致。
combFunc函数 reduce聚合
在reduce端大聚合,拉完数据后也是先分组,然后再调用combFunc函数
五、结果

Spark算子之aggregateByKey详解的更多相关文章
- Spark算子篇 --Spark算子之aggregateByKey详解
一.基本介绍 rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值 3代表每次分完组之后的每个组的初始值. seqFunc代表combine的聚合逻 ...
- Spark算子篇 --Spark算子之combineByKey详解
一.概念 rdd.combineByKey(lambda x:"%d_" %x, lambda a,b:"%s@%s" %(a,b), lambda a,b:& ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- Spark中的分区方法详解
转自:https://blog.csdn.net/dmy1115143060/article/details/82620715 一.Spark数据分区方式简要 在Spark中,RDD(Resilien ...
- Spark技术内幕: Shuffle详解(一)
通过上面一系列文章,我们知道在集群启动时,在Standalone模式下,Worker会向Master注册,使得Master可以感知进而管理整个集群:Master通过借助ZK,可以简单的实现HA:而应用 ...
- Spark操作—aggregate、aggregateByKey详解
https://blog.csdn.net/u013514928/article/details/56680825 1. aggregate函数 将每个分区里面的元素进行聚合,然后用combine函数 ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
随机推荐
- 跟bWAPP学WEB安全(PHP代码)--XSS跨站脚本攻击
背景 这个系列有很多题,但是其实考察的相近,类似的就不在多说,我们来看吧.主要分几个点来讲: 反射型 存储型 JSON XM 头部字段相关 分类介绍 反射型 在请求中构造了XSS的Payload,一般 ...
- vscode 设置 cmder为终端
"terminal.integrated.shell.windows": "cmd.exe", "terminal.integrated.shellA ...
- vbox 的 ova 提取vmdk 与 vdi 以及扩容
原文: http://blog.csdn.net/flm2003/article/details/11980863 1. 从ova提取vmdk: tar xvf oldImage.ova => ...
- 通过Java语言连接mysql数据库
1加载驱动 2创建链接对象 3创建语句传输对象 4接受结果集 5遍历 6关闭资源
- 堆的C语言实现
在C++中,可以通过std::priority_queue来使用堆. 堆的C语言实现: heap.c /** @file heap.c * @brief 堆,默认为小根堆,即堆顶为最小. */ #in ...
- Linux内核编译指定输出目录
# kbuild supports saving output files in a separate directory.# To locate output files in a separate ...
- 洛谷P1216 数字三角形【dp】
题目:https://www.luogu.org/problemnew/show/P1216 题意: 给定一个三角形.从顶走到底,问路径上的数字之和最大是多少. 走的时候可以往左下(实际上纵坐标不变) ...
- System.InvalidOperationException: 此实现不是 Windows 平台 FIPS 验证的加密算法的一部分。
x 昨天还好好地,然后清理一下电脑垃圾,就突然报这个错误了; 网上搜索了一下:找到解决方案了,但是由于底层知识的功力不够,至今未知具体怎么导致的... 解决方案↓ 进注册表 按Win+R运行reged ...
- HTML响应状态码
https://www.restapitutorial.com/httpstatuscodes.html
- 安装多个java后,java版本不对
参考资料: https://www.cnblogs.com/Kidezyq/p/5781131.html 主要原因是javac -version是由JAVA_HOME指定的路径中的java版本来决定的 ...