Spark入门(1-5)Spark统一了TableView和GraphView
下面我们看一下图计算的简单示例:
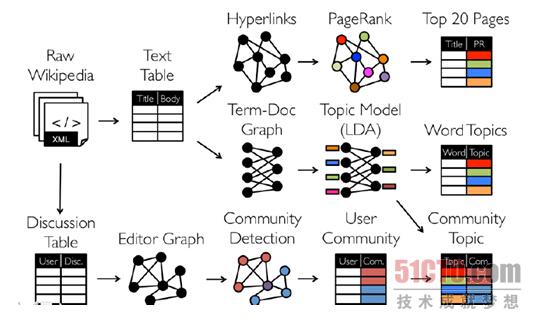
从图我们可以看出, 拿到Wikipedia的文档后,我们可以:
1、Wikipedia的文档 -- > table视图 -- >分析Hyperlinks超链接 -- > PageRank分析,
2、Wikipedia的文档 -- > table视图 -- >分析Term-Doc Graph -- > LDA -- > WordTopics
3、Wikipedia的文档 -- >Editor Graph -- > Community , 这个过程可以称之为Triangle Computation,这是计算三角形的一个算法,基于此,会发现一个社区,
从上面的分析中我们可以发现图计算有很多的做法和算法,同时也发现图和表格可以做互相的转换,不过并非所有的图计算框架都支持图与表格的互相转换。
Spark GraphX的优势在于能够把表格和图进行互相转换,这一点可以带来非常多的优势,
现在很多框架也在渐渐的往这方面发展,例如GraphLib已经实现了可以读取Graph中的Data,也可以读取Table中的Data,也可以读取Text总的data即文本中的内容等,
与此同时Spark GraphX基于Spark也为GraphX增添了额外的很多优势,例如和mllib、Spark SQL协作等。
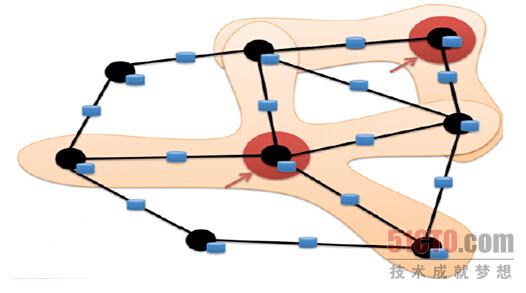
当今图计算领域对图的计算大多数只考虑邻居节点的计算,也就是说一个节点计算的时候只会考虑其邻居节点,对于非邻居节点是不关心的,如下图所示:
目前基于图的并行计算框架已经有很多,比如来自Google的Pregel、来自Apache开源的图计算框架Giraph,以及我们最为著名的GraphLab,当然也包含HAMA,其中Pregel、HAMA、Giraph都是非常类似的,都是基于BSP模型,
BSP模型实现了SuperStep即超步,BSP首先进行本地计算,然后进行全局的通信,然后进行全局的Barrier;
BSP最大的好处是编程简单,而其问题在于一些情况下BSP运算的性能非常差,
因为我们有一个全局Barrier的存在,所以系统速度取决于最慢的计算,也就把木桶原理体现无遗,
另外一方面,很多现实生活中的网络是符合幂律分布的,也就是定点、边等分布式很不均匀,所以在这种情况下BSP的木桶原理导致了性能问题会得到很大的放大,
对这个问题的解决,以GraphLab为例,使用了一种异步的概念而没有全部的Barrier;
最后,不得不提的一点是在Spark Graphx中可以用极为简洁的代码非常方便的使用Pregel的API。
基于图的计算框架的共同特点是抽象出了一批API来简化基于图的编程,这往往比一般的data-parellel系统的性能高出很多倍。
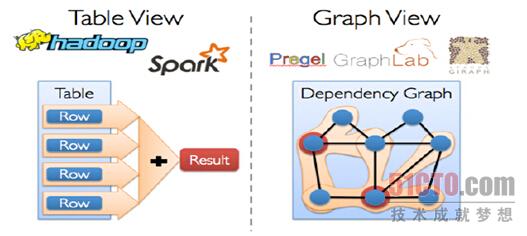
传统的图计算,往往需要不同的系统支持不同的View,
例如在Table View这种视图下可能需要Spark的支持或者Hadoop的支持,
而在Graph View这种视图下可能需要Pregel或者GraphLab的支持,
也就是把图和表分别在不同的系统中进行拉练处理,如下图所示:
上面所描述的图计算处理方式是传统的计算方式,当然现在除了Spark GraphX之外的图计算框架也在考虑这个问题;
不同系统带来的问题是之一是需要学习、部署和管理不同的系统,
例如要同时学习、部署和管理Hadoop、Hive、Spark、Giraph、GraphLab等:

大家都知道“Detail is evil”,如果我们能够用更少的框架解决更多的问题那是更好的。
其实最关键的问题还是效率问题,因为在不同的转换中间每步都要落地的话,数据转换和复制带来的开销也非常大,包括序列化带来的开销,同时中间结果和相应的结构无法重用,特别是一些结构性的东西,
譬如说顶点或者边的结构一直没有变,这种情况下结构内部的Structure是不需要改变的,而如果每次都重新构建的话,就算不变也无法重用,这回导致非常差的性能:
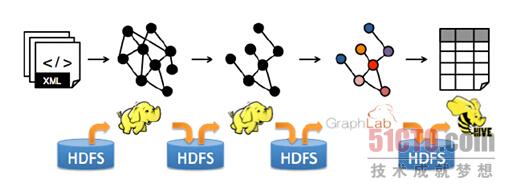
解决方案就是Spark GraphX,GarphX实现了Unified Representation,GraphX统一了Table View和Graph View,基于Spark可以非常轻松的做pipeline的操作:
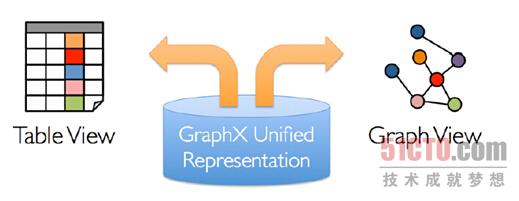
如果和Spark SQL结合,我们可以用SQL语句来进行ETL,然后放入GraphX来处理,是非常方便的。
在Spark GraphX中的Graph其实是Property Graph,也就是说图的每个顶点和边都是有属性的,如下图所示:
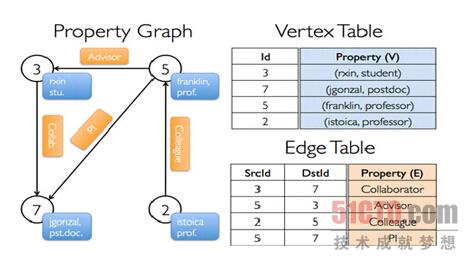
例如为3的顶点的名称为rxin,是学生stu.,5这个顶点是franlin,是一个prof.,5到3表明5是3的Advisor,上图中蓝色的表示的是相应顶点的Property,而黄色橙黄色部分表示的边的Property,边和顶点都是有ID的,对于顶点而言有自身的ID,而对于边来说有SourceID和DestinationID,即对于边而言会有两个ID来表达从哪个顶点出发到哪个顶点结束,来表明边的方向,这就是Property Graph的表示方法;如果把Property反映到表上的话,例如我们在Vertex Table中Id为的3的Property就是(rxin, student),而在Edge Table中3到7表明的边的Property是Collaborator的关系,2到5是Colleague的关系;更为重要的是Property Graph和Table之间是可以相互转换的,在GraphX中所有操作的基础是table operator和graph operator,,其继承自Spark中的RDD,都是针对集合进行操作。
Spark入门(1-5)Spark统一了TableView和GraphView的更多相关文章
- Spark入门2(Spark简析)
一.Spark核心概念-RDD RDD是弹性分布式数据集,一个RDD由多个partition构成,一个partition对应一个task.RDD的操作分为两种:Trasformation(把一个RDD ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- Spark入门:第1节 Spark概述:1 - 4
2.spark概述 2.1 什么是spark Apache Spark™ is a unified analytics engine for large-scale data processing. ...
随机推荐
- [转]【安卓笔记】AsyncTask源码剖析
[转][安卓笔记]AsyncTask源码剖析 http://blog.csdn.net/chdjj/article/details/39122547 前言: 初学AsyncTask时,就想研究下它的实 ...
- 筛法求素数Java
输出:一个集合S,表示1~n以内所有的素数 import java.util.Scanner; public class 筛法求素数 { public static void main(String[ ...
- Batch update returned unexpected row count from update [0] 异常处理
在one-to-many时遇到此异常,本以为是配置出错.在使用s标签开启debug模式,并在struts2主配置文件中添加异常映射,再次提交表单后得到以下异常详情. org.springframewo ...
- 并查集(Java实现)
(最好在电脑下浏览本篇博客...手机上看代码不方便) 当时学的时候看的一本印度的数据结构书(好像是..有点忘了..反正跟同学们看的都不一样...)...里面把本文提到的所有情况都提到了,我这里只是重复 ...
- java创建运行以及项目结构
一 创建java project 再src下添加class,选择一个class添加main方法作为程序的入口 二.项目结构: src下添加不同的包,命名方法为com.jikexueyuan.hello ...
- logback读取src/test/resource下的配置文件
import java.io.File; import java.net.URISyntaxException; import java.util.Map; import java.util.Prop ...
- js前端读写文件的方法(json、excel)
1.前端读取文件的实现 关键:利用文件上传对话框预览本地文件.利用FileReader读取文件 前端预览本地文件 <input tabindex="-1" id=" ...
- 安装texlive2017(latex的编译软件)
准备工作是先卸载老版本的texlive,这个只要找到原来安装时的安装目录,然后直接把整个文件夹删掉即可.然后找到最近的Ctan的镜像,下载到对应版本的texlive,例如Mac系统,最好用的就是tex ...
- C#编程语言之委托与事件(二)—— C#事件
前面已经大致讲述了C#委托的一些基础知识点,本文接下来的内容是C#中的事件(Event),在此我提个建议,如果是刚接触C#的委托类型的朋友可以先看到这里,等熟悉了委托的使用之后(大约1-2天)再来了解 ...
- 跨平台原生AR/VR应用研发引擎-NVisionXR开放内测
NVisionXR引擎正式开放内测.现在,对原生AR/VR应用开发有兴趣的企业和开发者均可通过NVisionXR官网(www.nvisionxr.com)申请试用. NVisionXR引擎介绍视频 ...