ORM Basic
ORM即object relational mapping 对象关系映射程序,可以在操作数据库的时候使用自有的语言而不必使用数据库的语言。
在python中,最强大的ORM框架就是SQLAlchemy。基本构成如下:
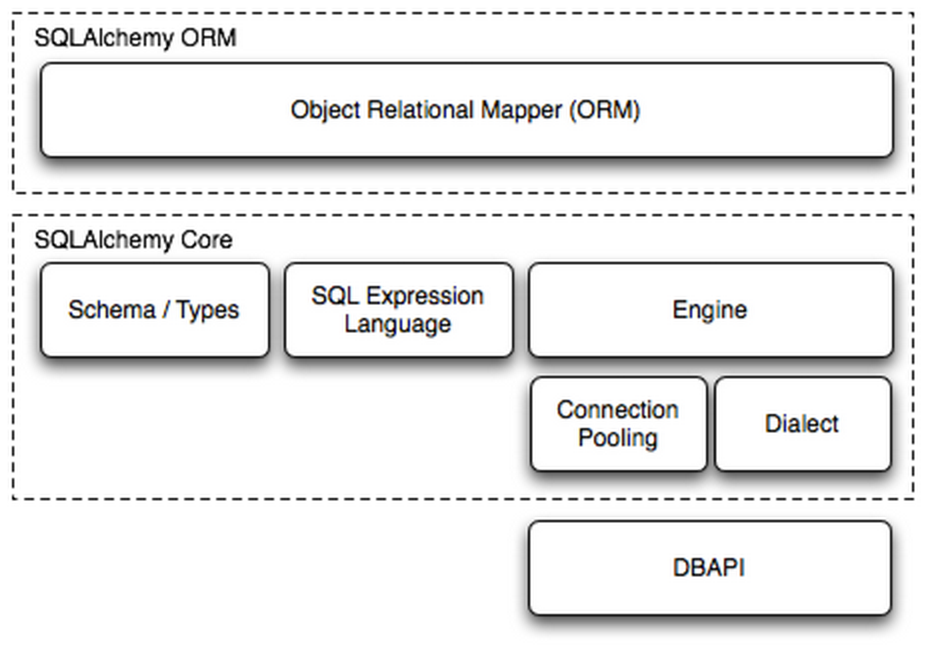
首先来看看SQL Alchemy的基本用法:
在使用SQL Alchemy的时候必须包子Mysql的字符集为utf-8(默认为Latin1),使用以下命令进入MySQL的配置
sudo vim /etc/mysql/my.cnf
插入信息:
[client]
default-character-set = utf8
[mysqld]
character-set-server = utf8
[mysql]
default-character-set = utf8
下面开始正式连接数据库
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://root****@locahost:3306/blog#****为MySQLroot用户密码,此命令运行了默认在3306端口的blog数据库
下面开始描述表结构:
SQL alchemy有declarative系统来进行数据库中表的结构描述,以创建user为例:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String engine = create_engine("mysql+pymysql://root:123456@localhost:3306/test2db?charset=utf8")
Base = declarative_base() # 生成基类 class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True) def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.name)# Base.metadata.create_all(engine)#创建表结构
创建了users的表,有三个字段(用Column语句描述),包括id,name和password,数据类型处理integer和string外还有text,Boolean,smallinteger和datetime,nullable=False表示不可为空,index=True表示在该列创建索引,并且用repr函数定义了返回输出格式
表的本质就是各种关系的集合,那么我们来看看这些关系的定义
一对多关系
用户跟文章肯定有一个关系,而且该关系还是一对多(一个作者对应多个文章)
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,Text
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship engine = create_engine("mysql+mysqldb://root:123456@localhost:3306/test2db?charset = utf8") Base = declarative_base() # 生成基类 class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True)
articles = relationship('Article',backref = 'author')#连接User和Article在users中使用articles调用,在articles中使用users调用。 def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.name)
class Article(Base):
__tablename__ = 'articles'
article_id = Column(Integer, primary_key=True,nullable=False, index=True)
title = Column(String(255),nullable = False,index = True)
content = Column(Text)
user_id = Column(integer,ForeignKey('users.id'))
def __repr__(self):
return '%S'(%r)%(self.__class__.__name__,self.title) Base.metadata.create_all(engine)#创建表结构
一对一关系
如果需要储存一个更详细的个人资料User_Info,其与User的映射应该是一对一的。
#coding:utf8
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,Text
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship engine = create_engine("mysql+mysqldb://root:123456@localhost:3306/blog?charset = utf8") Base = declarative_base() # 生成基类
class User(Base):
__tablename__ = "users" # 表名
id = Column(Integer, primary_key=True,nullable=False, index=True)
name = Column(String(20),nullable=False)
password = Column(String(20),nullable=False, index=True)
article = relationship('Article',backref = 'author')
userinfo=relationship('userinfo',backref='author',uselist=False)#只需要将此处uselist设为False便是一对一 class Article(Base):
__tablename__ = 'articles'
article_id = Column(Integer, primary_key=True,nullable=False, index=True)
title = Column(String(255),nullable = False,index = True)
content = Column(Text)
user_id = Column(Integer,ForeignKey('users.id')) class Info_User(Base):
__tablename__='userinfo'
id=Column(Integer,primary_key=True,nullable=False,index=True)
qq=Column(String(32),nullable=False,index=True)
tel=Column(String(32),nullable=False,index=True)
user_id=Column(Integer,ForeignKey('users.id')) Base.metadata.create_all(engine)#创建表结构
多对多的关系:
一个文章可能有多个标签,一个标签也可能对应多本文章,这就是多对多的关系。多对多不能直接定义,需要分解为两个一对多,并引入一张额外的表来协助完成。
article_tag = Table(
'article_tag', Base.metadata,
Column('article_id', Integer, ForeignKey('articles.id'),nullable=False,primary_key=True),
Column('tag_id', Integer, ForeignKey('tags.id'),nullable=False,primary_key=True)
) class Tag(Base): __tablename__ = 'tags' id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True) def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.name)
表结构已经搭好,现在开始往里面填充数据,此处我们使用faker模块来模拟数据。
import faker
faker = Factory.create()
Session = sessionmaker(bind=engine)
session = Session()#创建了一个可以与MySQL对话的实例 faker_users = [User(
username=faker.name(),
password=faker.word(),
email=faker.email(),
) for i in range(10)]
session.add_all(faker_users) faker_categories = [Category(name=faker.word()) for i in range(5)]
session.add_all(faker_categories) faker_tags= [Tag(name=faker.word()) for i in range(20)]
session.add_all(faker_tags) for i in range(100):
article = Article(
title=faker.sentence(),
content=' '.join(faker.sentences(nb=random.randint(10, 20))),#10-20个不等长的sentence
author=random.choice(faker_users),
category=random.choice(faker_categories)
)
for tag in random.sample(faker_tags, random.randint(2, 5)):2-5个tags
article.tags.append(tag)
session.add(article) session.commit()
通过以上代码创建了10个用户,5个分类,20个标签,100篇文章,使用 SQLAlchemy 往数据库中添加数据,我们只需要创建相关类的实例,调用 session.add() 添加一个,或者 session.add_all() 一次添加多个, 最后 session.commit() 就可以了。
查:使用get语法,filter_by按照某一特定格式筛选(使用=),filter按照一些格式筛选(使用==),all查询所有
article = session.query(Article).get(1)
改:
article.title = 'this is my first blog'
session.add(article)
session.commit()
增:
article.tag.append(Tag(name='python'))
session.add(article)
session.commit()
删:
session.delete(article)
session.commit()
ORM Basic的更多相关文章
- NHibernate官方文档中文版--基础ORM(Basic O/R Mapping)
映射声明 对象/关系映射在XML文件中配置.mapping文件这样设计是为了使它可读性强并且可修改.mapping语言是以对象为中心,意味着mapping是围绕着持久化类声明来建立的,而不是围绕数据表 ...
- 基于.NET C#的 sqlite 数据库 ORM 【Easyliter】
因为工作原因经常用到SQLITE数据库,但又找不到好用的ORM所以自个整理了一个简单好用的轻量极ORM框架:Easyliter 功能介绍: 1.支持SQL语句操作 2.支持 List<T> ...
- ORM框架:EF与NHibernate了解
在.Net Framework SP1微软包含一个实体框架(Entity Framework),此框架可以理解成微软的一个ORM产品.用于支持开发人员通过对概念性应用程序模型编程(而不是直接对关系存储 ...
- Database ORM
Database ORM Introduction Basic Usage Mass Assignment Insert, Update, Delete Soft Deleting Timestamp ...
- 【转载】ADO.NET与ORM的比较(3):Linq to SQL实现CRUD
[转载]ADO.NET与ORM的比较(3):Linq to SQL实现CRUD 说明:个人感觉在Java领域大型开发都离不了ORM的身影,所谓的SSH就是Spring+Struts+Hibernate ...
- C# Android 开发中使用 Sqlite.NET ORM
开发环境:VS2015 Xamarin Sqlite.NET ORM 不就相当于 Entiry Framework For Xamarin 吗? 相当于用 C# 开发安卓程序访问 Sqlite 可以使 ...
- @Basic表示一个简单的属性 懒加载,急加载
5.@Basic(fetch=FetchType,optional=true) 可选 @Basic表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的getXxxx()方法,默认 即为 @Ba ...
- ORM,DAO,MVC,POJO
1.ORM 对象关系映射(Object Relational Mapping,简称ORM)是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述对象和数据库之间 ...
- 杂项-ORM:LinqToSQL
ylbtech-杂项-ORM:LinqToSQL LINQ TO SQL 是包含在.NET Framework 3.5 版中的一种 O/RM 组件(对象关系映射),O/RM 允许你使用 .NET 的类 ...
随机推荐
- 前端开发利器webStorm
这里推荐一个前端开发工具webStorm.用了大概快半年了,发现所有其他工具无出其右的.目前最新版本已经到4.0.2,半年前还是2.X 相比aptana.dreamweaver.sublime和vim ...
- 【Unity3D技术文档翻译】第1.1篇 AssetBundle 工作流
译者前言:本章是关于从创建到加载,再到使用 AssetBundle 的整个流程的概述.阅读本章将对 AssetBundle 的工作流程有个简单而全面的了解. 本章原文所在章节:[Unity Manua ...
- CentOS7上LNMP安装包一步搭建LNMP环境
系统需求: CentOS/RHEL/Fedora/Debian/Ubuntu/Raspbian Linux系统 需要5GB以上硬盘剩余空间 需要128MB以上内存(如果为128MB的小内存VPS,Xe ...
- C# 如何使用预处理指令?
#define Debug #define Release #undef Release #if Debug using System; #endif 注意:#define 必须在文档最前面
- Spring Data JPA 入门Demo
什么是JPA呢? 其实JPA可以说是一种规范,是java5.0之后提出来的用于持久化的一套规范:它不是任何一种ORM框架,在我看来,是现有ORM框架在这个规范下去实现持久层. 它的出现是为了简化现有的 ...
- linux中的三个文件时间
Linux系统文件有三个主要的时间属性,分别是ctime(change time), atime(access time), mtime(modify time). 后来为了解决atime的性能问题, ...
- Ansible自动化运维笔记1(安装配置)
1.Ansible的安装 pip install ansible==1.9.1 ansible1.9.1版本依赖的软件有 Python2.6以上版本 paramiko模块 PyYAML Jinja2 ...
- 64位Kali无法顺利执行pwn1问题的解决方案
问题描述 环境:VMware Fusion + kali-linux-2018.1-amd64.iso 问题:在Terminal利用./pwn1执行pwn1会出现 bash: ./pwn1:没 ...
- spring+mybatis+c3p0数据库连接池或druid连接池使用配置整理
在系统性能优化的时候,或者说在进行代码开发的时候,多数人应该都知道一个很基本的原则,那就是保证功能正常良好的情况下,要尽量减少对数据库的操作. 据我所知,原因大概有这样两个: 一个是,一般情况下系统服 ...
- 机器学习中应用到的各种距离介绍(附上Matlab代码)
转载于博客:各种距离 在做分类时常常需要估算不同样本之间的相似性度量(SimilarityMeasurement),这时通常采用的方法就是计算样本间的"距离"(Distance). ...