sql索引实例
1.创建表并插入数据
在Sql Server2008中创建测试数据库Test,接着创建数据库表并插入数据,sql代码如下:
USE Test
IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'emp_pay')
DROP TABLE emp_pay
GO
USE Test
IF EXISTS (SELECT name FROM sys.indexes
WHERE name = 'employeeID_ind')
DROP INDEX emp_pay.employeeID_ind
GO
USE Test
GO
CREATE TABLE emp_pay
(
employeeID int NOT NULL,
base_pay money NOT NULL,
commission decimal(2, 2) NOT NULL
)
INSERT emp_pay
VALUES (1, 500, .10)
INSERT emp_pay
VALUES (2, 1000, .05)
INSERT emp_pay
VALUES (6, 800, .07)
INSERT emp_pay
VALUES (5, 1500, .03)
INSERT emp_pay
VALUES (9, 750, .06)
执行完上述sql代码以后我们会发现在Test数据库中多出了一张emp_pay表,数据库表的内容如下图所示:
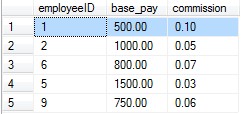
2.无索引查找
从上图我们可以看出数据库中存储的数据排列顺序与我们插入的先后顺序一致。接下来我们查询employeeID=5的字段,执行如下sql代码:
USE Test
SELECT * FROM emp_pay where employeeID=5
在SQL SERVER MANAGEMENT STUDIO中我们点击“显示估计的查询计划”,会出现如下图所示的查询计划图:

其中表扫描的内容为:
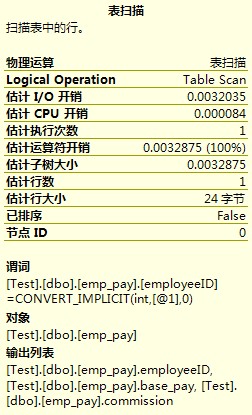
3.创建索引
接下来我们为上述表添加聚集唯一索引,代码如下:
SET NOCOUNT OFF
CREATE UNIQUE CLUSTERED INDEX employeeID_ind
ON emp_pay (employeeID)
GO
在执行完上述创建索引的代码以后,我们再次查询emp_pay的数据内容,如下图所示:

从上图我们可以发现数据内容已经按照employeeID进行了排序。
我们继续执行前面关于employeeID=5的查询,点击“显示估计的执行计划”,出现如下图所示内容:

聚集索引查找的内容为:

总结:
当我们为数据库表中的某一个字段创建索引,并且在查询语句中where子句中用到这样一个字段,那么查询效率会有所提高,我们上述实验因为数据量的关系查询效率提高不明显。
补充
我们上面添加的索引是唯一聚集索引,因此当插入的数据在employeeID字段出现重复时会报错。假如我们在创建索引之前数据字段出现重复,那么就不能创建唯一索引。
创建索引以后的排序(PS:2012-5-28)
执行如下sql语句
update emp_pay set employeeID=7 where employeeID=1;
然后再次执行全表查询,我们发现查询结果如下所示:
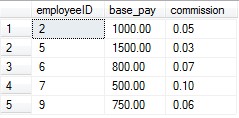
只要我们更新了employeeID,那么最后的更新结果都会按照employeeID的值进行升序排序。这是因为我们在employeeID上创建了索引的缘故。
删除索引(PS:2012-6-4)
我们可以通过sql server management studio这个工具删除索引,也可以通过sql语句进行索引的删除,假设我们要求删除在前面创建的索引employeeID_ind,那么sql语句如下代码所示:
DROP INDEX employeeID_ind ON emp_pay;
sql索引实例的更多相关文章
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- SQL索引学习-聚集索引
这篇接着我们的索引学习系列,这次主要来分享一些有关聚集索引的问题.上一篇SQL索引学习-索引结构主要是从一些基础概念上给大家分享了我的理解,没有实例,有朋友就提到了聚集索引的问题,这里列出来一下: 其 ...
- 数据库性能优化:SQL索引
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- SQL索引一步到位
以下均非原创,仅供分享.学习!!! SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? S ...
- {好文备份}SQL索引一步到位
SQL索引一步到位(此文章为"数据库性能优化二:数据库表优化"附属文章之一) SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百 ...
- 转载:SQL索引一步到位
原文: http://www.cnblogs.com/AK2012/archive/2013/01/04/2844283.html SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文 ...
- SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文章之一)
SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文章之一) SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭 ...
- SQL索引详解
转自:http://www.cnblogs.com/AK2012/archive/2013/01/04/2844283.html SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可 ...
- 数据库性能优化一:SQL索引一步到位
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
随机推荐
- WordPress插件入口菜单创建的位置代码
Add_management_page() 在Tools下面创建 Add_options_page() 在Settings下面创建 Add_theme_page() 在Appearance下面创建 A ...
- BZOJ4448:[SCO2015]情报传递
题目大意:给你一棵树,有两种操作,一个是修改某个点的权值,另一个是询问两点之间的距离以及路径上小于某个值的数的个数. 询问两点之间距离直接lca即可,对于求个数的问题可以用主席树完成. #includ ...
- request获取请求头和请求数据
package cn.itcast.request; import java.io.IOException; import java.io.InputStream; import java.io.Pr ...
- 【iCore3 双核心板】例程二十四:LAN_DHCP实验——动态分配IP地址
实验指导书及代码包下载: http://pan.baidu.com/s/1i4vMMv7 iCore3 购买链接: https://item.taobao.com/item.htm?id=524229 ...
- Apache模块mod_security 和 Nginx过滤配置
1.安装mod_securityyum install mod_security 2.安装mod_security_crsyum install mod_security_crs 3.在/etc/ht ...
- 使用 U盘 重装 Mac OSX
一.制作 U 盘系统启动盘 1.从 App Store 上下载 OS Application.(这里需要注意,取消下载完的自动更新,并存储下这个 OS.Application 文件,因为系统更新完后, ...
- 前台 JSON对象转换成字符串 相互转换 的几种方式
在最近的工作中,使用到JSON进行数据的传递,特别是从前端传递到后台,前台可以直接采用ajax的data函数,按json格式传递,后台Request即可,但有的时候,需要传递多个参数,后台使用requ ...
- 《奥威Power-BI销售计划填报 》精彩回顾
我们经常遇到这样的问题:业务单据是来自ERP系统,销售计划是EXCEL做的,想把两者整合在一起做分析,怎么办? 单据大,导出EXCEL太费劲,也很难分析到历史数据,但又不能动ERP系统 (自己也不会改 ...
- CSS display 属性
实例 使段落生出行内框: p.inline { display:inline; } 所有主流浏览器都支持 display 属性. 注释:如果规定了 !DOCTYPE,则 Internet Explor ...
- php截取字符串
1.substr(源字符串,其实位置[,长度])-截取字符串返回部分字符串 <?php $str ="phpddt.com"; echo substr($str, 2); / ...