在Solr中配置和使用ansj分词
在上一节【编译Ansj之Solr插件】中介绍如何编译ansj分词在solr(lucene)环境中使用的接口,本章将介绍如何在solr中使用ansj,其步骤主要包括:下载或者编译ansj和nlp-lang等jar包、在schema中配置相关类型、将ansj和nlp-lang等jar包配置到solr中、测试ansj分词效果。
一、下载或者编译ansj-seg和nlp-lang等jar包。
1、您可以到 http://maven.ansj.org/org/ansj/ansj_seg/ | http://maven.ansj.org/org/nlpcn/ 中下载相关jar包。
ansj-seg相关jar包,如下图所示:
nlp-lang 是ansj-seg分词中关于自然语言处理相关工具类,功能比较强大:

2、下载相关源码,自己编译。
这种是相对复杂的,但是如果长久使用,这种是很有必要的。对于这种优秀的分词,我们更有必要好好研究一番。
github地址:https://github.com/NLPchina/ansj_seg
git客户端地址:http://git-scm.com/download/
git下载源码命令:git clone https://github.com/NLPchina/ansj_seg.git
下载后的文件结构如下:
可见代码是用maven组中管理的。对于maven的安装配置本文旧粗略带过,主要包括:
下载maven相关包,解压:

配置环境变量M2_HOME:C:\apache-maven-3.2.1
配置PATHb环境变量:%M2_HOME%\bin;
mvn常有命令:mvn clean install#清理本地缓存、下载依赖jar包 可以添加-DskipTests=true忽略单元测试;mvn eclipse:clean #清理mvn生成的eclipse工程;mvn eclipse:eclipse #根据pom.xml生成eclipse工程。
步骤:
在源码根路径下执行: mvn clean install -DskipTests=true 命令,在target目录下生成jar包。
target目录:
同义的道理,可以编译nlp-lang jar包,地址:https://github.com/NLPchina/nlp-lang
二、在solr schema.xml中配置好ansj字段类型。
1、创建ansj类型。
找到schema.xml,添加ansj类型text_ansj:
<!--ansj start --> <fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.ansj.solr.AnsjTokenizerFactory" isQuery="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.ansj.solr.AnsjTokenizerFactory"/>
</analyzer>
</fieldType> <!--ansj end -->
org.ansj.solr.AnsjTokenizerFactory 是我们编译的ansj-lucene插件。
2、配置需要索引的字段。
<!-- ansj_test field -->
<field name="POI_OID" type="string" indexed="false" stored="true"/>
<field name="POI_NAME" type="text_ansj" indexed="true" stored="false"/>
<field name="POI_NAME_SUGGEST" type="string" indexed="false" stored="true"/>
<field name="POI_ADDRESS" type="text_ansj" indexed="true" stored="false"/>
<field name="POI_ADDRESS_SUGGEST" type="string" indexed="false" stored="true"/>
<field name="POI_PHONE" type="string" indexed="true" stored="true"/>
<field name="POI_TYPE" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="POI_URL" type="string" indexed="false" stored="true"/>
<field name="POI_DIANPING" type="string" indexed="true" stored="true" />
<field name="POI_BRAND" type="string" indexed="true" stored="true"/>
<field name="POI_CITY" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="POI_TAG" type="text_ansj" indexed="true" stored="true"/>
<field name="POI_LAT" type="double" indexed="false" stored="true"/>
<field name="POI_LON" type="double" indexed="false" stored="true"/>
<field name="POI_DATA_TYPE" type="string" indexed="true" stored="false"/>
三、在solr环境中配置好ansj。
在编译好的ansj-seg、nlp-lang、ansj_lucene4_plug 放到solr war包的lib下。
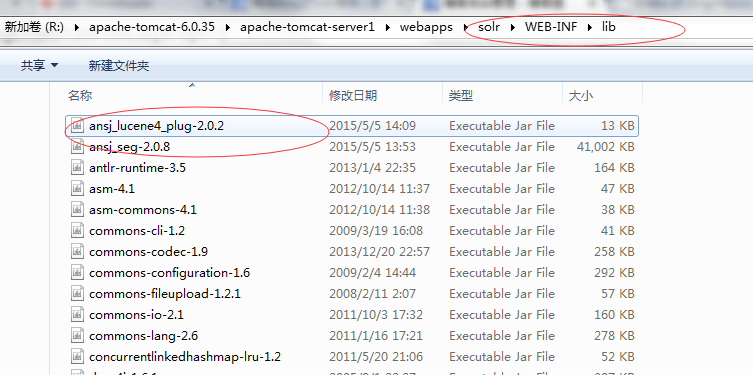
配置ansj相关词库和配置文件,这些配置文件在ansj源码目录下:
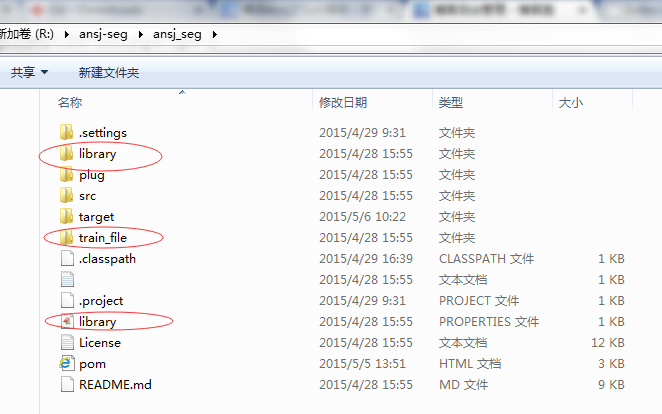
把这三个配置文件放到solr程序WEB-INF/classes目录下,classes目录不存在则手动创建。
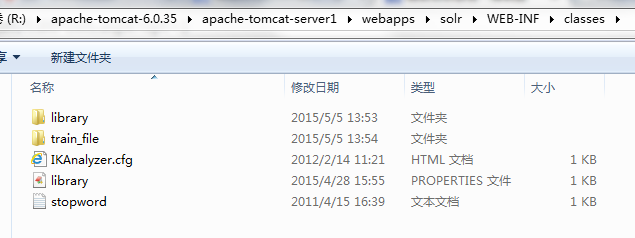
四、测试ansj分词效果。
ansj配置好了以后,把solr所在的tomcat启动一下。用solr管理页面查看效果:
1、测试分词 "南京市长江大桥”
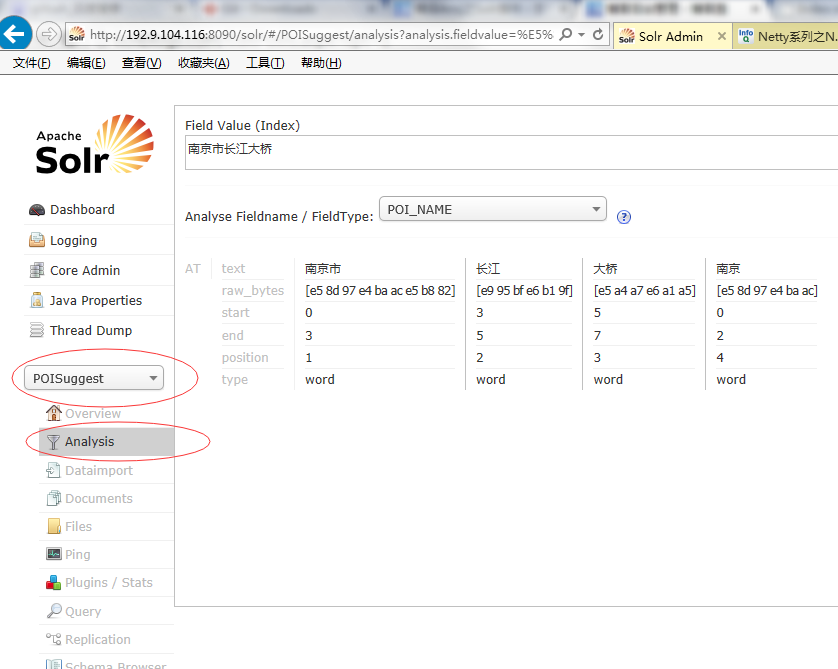
备注:在文本框中输入“南京市长江大桥” 点击右边蓝色的按钮“Analyse Values”
文章转载,请注明出处:http://www.cnblogs.com/likehua/p/4481219.html
在Solr中配置和使用ansj分词的更多相关文章
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr的配置和在java中的使用
Solr是一个全局站内搜索引擎,可以快速的搜索出结果. Solr依赖于tomcat,把Solr的war包放到tomcat中即可运行. 使用solr,需要在solr的schema.xml中配置solr与 ...
- Solr中Schema.xml中文版
<?xml version="1.0" encoding="UTF-8" ?> <!-- Licensed to the Apache Sof ...
- ansj分词
本文转载至:https://blog.csdn.net/bitcarmanlee/article/details/53607776 最近的项目需要使用到分词技术.本着不重复造轮子的原则,使用了ansj ...
- Solr索引配置
Solr主配置文件 schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的.主要包括FieldTypes.Fields和其他的一些缺省 ...
- elasticsearch安装ansj分词器
1.概述 elasticsearch用于搜索引擎,需要设置一些分词器来优化索引.常用的有ik_max_word: 会将文本做最细粒度的拆分.ik_smart: 会做最粗粒度的拆分.ansj等. ...
- BugPhobia沟通篇章:Solr模式配置与数据导入调研
0x01 :Scrum Meeting特别说明 特别说明,考虑到编译原理课程考核的时间安排,每天开发时间急剧缩短以至于难以维系正常的Scrum Meeting,因此,将2015/12/13 00:00 ...
- ansj分词史上最详细教程
最近的项目需要使用到分词技术.本着不重复造轮子的原则,使用了ansj_seg来进行分词.本文结合博主使用经过,教大家用最快的速度上手使用ansj分词. 1.给ansj来个硬广 项目的github地址: ...
随机推荐
- 【前端福利】用grunt搭建自动化的web前端开发环境-完整教程
jQuery在使用grunt,bootstrap在使用grunt,百度UEditor在使用grunt,你没有理由不学.不用! 1. 前言 各位web前端开发人员,如果你现在还不知道grunt或者听说过 ...
- iOS 代理反向传值
在上篇博客 iOS代理协议 中,侧重解析了委托代理协议的概念等,本文将侧重于它们在开发中的应用. 假如我们有一个需求如下:界面A上面有一个button.一个label.从界面A跳转到界面B,在界面B的 ...
- DevExpress免费线上公开课17日开课
小伙伴们,前几日DevExpress 正式发布了2015的第二次重大版本v15.2.3(更新说明),对于新版本中新增的一些功能和控件,你一定会有一些疑问,比如哪些功能是值得我们关注的,哪些控件有比较重 ...
- Android Material design
1.Material Design:扁而不平 2.Android Support Design 库 之 Snackbar使用及源码分析 3.十大Material Design开源项目,直接拿来用!
- View的事件体系
View的滑动 实现手段 优点 缺点 备注 scrollTo/scrollBy 使用简单 只能滑动view的内容,并不会滑动view本身. 且内容超出view本身的布局范围部分的不会显示 不适合有交互 ...
- 【代码笔记】iOS-竖状图
一,效果图. 二,工程图. 三,代码. RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController ...
- jQuery代码优化:事件委托篇
推荐阅读原文:http://www.ituring.com.cn/article/467# 推荐11收藏 随着DOM结构的复杂化和Ajax等动态脚本技术的运用,事件委托自然浮出了水面.jQuery为绑 ...
- [Java]Hessian客户端和服务端代码例子
简要说明:这是一个比较简单的hessian客户端和服务端,主要实现从客户端发送指定的数据量到服务端,然后服务端在将接收到的数据原封不动返回到客户端.设计该hessian客户端和服务端的初衷是为了做一个 ...
- git merge git pull时候遇到冲突解决办法git stash
在使用git pull代码时,经常会碰到有冲突的情况,提示如下信息: error: Your local changes to 'c/environ.c' would be overwritten b ...
- R语言数据的输入
键盘输入 调用edit函数,比如我们要让用户输入一个长度为5的向量并赋值给变量a,那么可以: a<-vector() a<-edit(a) 另外也可以用函数fix来直接编辑变量,而不需要再 ...