在Solr中配置和使用ansj分词
在上一节【编译Ansj之Solr插件】中介绍如何编译ansj分词在solr(lucene)环境中使用的接口,本章将介绍如何在solr中使用ansj,其步骤主要包括:下载或者编译ansj和nlp-lang等jar包、在schema中配置相关类型、将ansj和nlp-lang等jar包配置到solr中、测试ansj分词效果。
一、下载或者编译ansj-seg和nlp-lang等jar包。
1、您可以到 http://maven.ansj.org/org/ansj/ansj_seg/ | http://maven.ansj.org/org/nlpcn/ 中下载相关jar包。
ansj-seg相关jar包,如下图所示:
nlp-lang 是ansj-seg分词中关于自然语言处理相关工具类,功能比较强大:

2、下载相关源码,自己编译。
这种是相对复杂的,但是如果长久使用,这种是很有必要的。对于这种优秀的分词,我们更有必要好好研究一番。
github地址:https://github.com/NLPchina/ansj_seg
git客户端地址:http://git-scm.com/download/
git下载源码命令:git clone https://github.com/NLPchina/ansj_seg.git
下载后的文件结构如下:
可见代码是用maven组中管理的。对于maven的安装配置本文旧粗略带过,主要包括:
下载maven相关包,解压:

配置环境变量M2_HOME:C:\apache-maven-3.2.1
配置PATHb环境变量:%M2_HOME%\bin;
mvn常有命令:mvn clean install#清理本地缓存、下载依赖jar包 可以添加-DskipTests=true忽略单元测试;mvn eclipse:clean #清理mvn生成的eclipse工程;mvn eclipse:eclipse #根据pom.xml生成eclipse工程。
步骤:
在源码根路径下执行: mvn clean install -DskipTests=true 命令,在target目录下生成jar包。
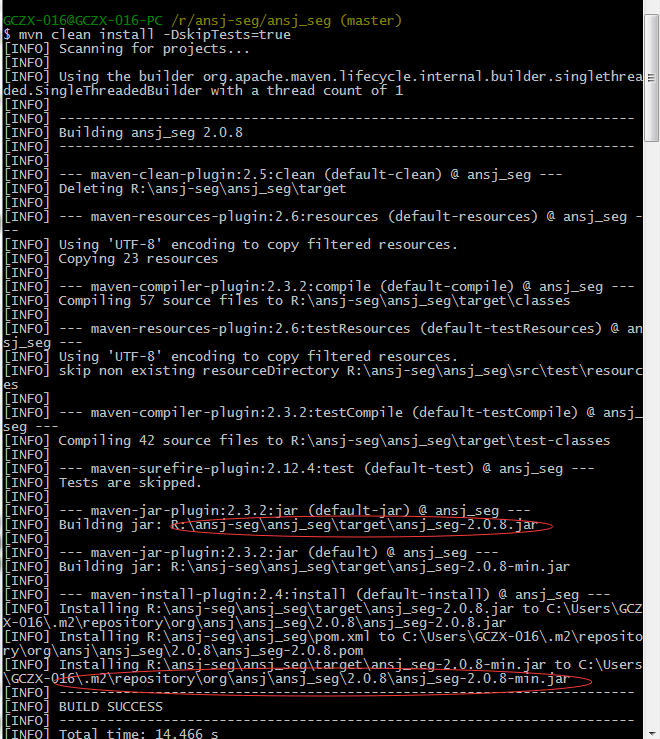
target目录:
同义的道理,可以编译nlp-lang jar包,地址:https://github.com/NLPchina/nlp-lang
二、在solr schema.xml中配置好ansj字段类型。
1、创建ansj类型。
找到schema.xml,添加ansj类型text_ansj:
<!--ansj start --> <fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.ansj.solr.AnsjTokenizerFactory" isQuery="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.ansj.solr.AnsjTokenizerFactory"/>
</analyzer>
</fieldType> <!--ansj end -->
org.ansj.solr.AnsjTokenizerFactory 是我们编译的ansj-lucene插件。
2、配置需要索引的字段。
<!-- ansj_test field -->
<field name="POI_OID" type="string" indexed="false" stored="true"/>
<field name="POI_NAME" type="text_ansj" indexed="true" stored="false"/>
<field name="POI_NAME_SUGGEST" type="string" indexed="false" stored="true"/>
<field name="POI_ADDRESS" type="text_ansj" indexed="true" stored="false"/>
<field name="POI_ADDRESS_SUGGEST" type="string" indexed="false" stored="true"/>
<field name="POI_PHONE" type="string" indexed="true" stored="true"/>
<field name="POI_TYPE" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="POI_URL" type="string" indexed="false" stored="true"/>
<field name="POI_DIANPING" type="string" indexed="true" stored="true" />
<field name="POI_BRAND" type="string" indexed="true" stored="true"/>
<field name="POI_CITY" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="POI_TAG" type="text_ansj" indexed="true" stored="true"/>
<field name="POI_LAT" type="double" indexed="false" stored="true"/>
<field name="POI_LON" type="double" indexed="false" stored="true"/>
<field name="POI_DATA_TYPE" type="string" indexed="true" stored="false"/>
三、在solr环境中配置好ansj。
在编译好的ansj-seg、nlp-lang、ansj_lucene4_plug 放到solr war包的lib下。
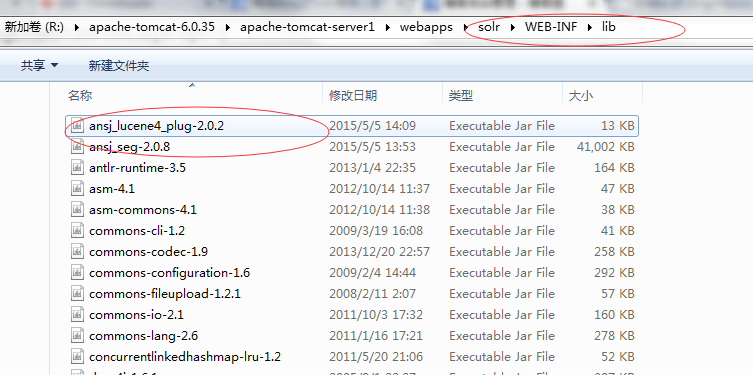
配置ansj相关词库和配置文件,这些配置文件在ansj源码目录下:
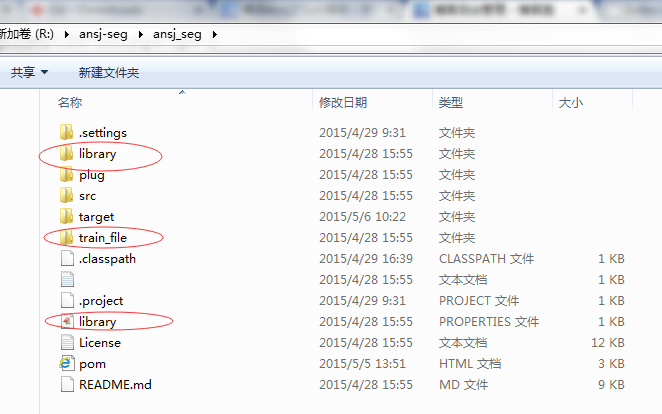
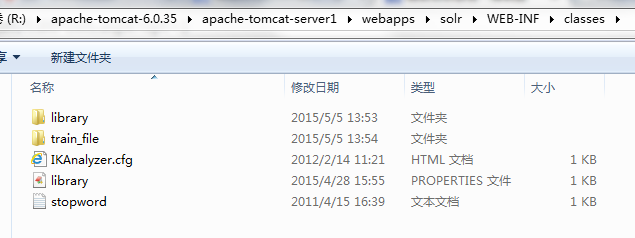
把这三个配置文件放到solr程序WEB-INF/classes目录下,classes目录不存在则手动创建。
四、测试ansj分词效果。
ansj配置好了以后,把solr所在的tomcat启动一下。用solr管理页面查看效果:
1、测试分词 "南京市长江大桥”
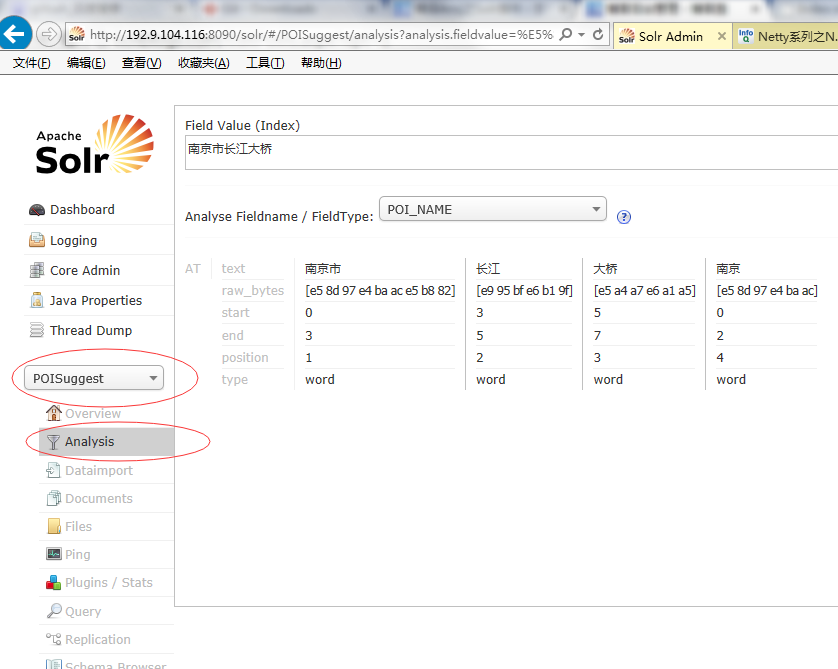
备注:在文本框中输入“南京市长江大桥” 点击右边蓝色的按钮“Analyse Values”
文章转载,请注明出处:http://www.cnblogs.com/likehua/p/4481219.html
在Solr中配置和使用ansj分词的更多相关文章
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr的配置和在java中的使用
Solr是一个全局站内搜索引擎,可以快速的搜索出结果. Solr依赖于tomcat,把Solr的war包放到tomcat中即可运行. 使用solr,需要在solr的schema.xml中配置solr与 ...
- Solr中Schema.xml中文版
<?xml version="1.0" encoding="UTF-8" ?> <!-- Licensed to the Apache Sof ...
- ansj分词
本文转载至:https://blog.csdn.net/bitcarmanlee/article/details/53607776 最近的项目需要使用到分词技术.本着不重复造轮子的原则,使用了ansj ...
- Solr索引配置
Solr主配置文件 schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的.主要包括FieldTypes.Fields和其他的一些缺省 ...
- elasticsearch安装ansj分词器
1.概述 elasticsearch用于搜索引擎,需要设置一些分词器来优化索引.常用的有ik_max_word: 会将文本做最细粒度的拆分.ik_smart: 会做最粗粒度的拆分.ansj等. ...
- BugPhobia沟通篇章:Solr模式配置与数据导入调研
0x01 :Scrum Meeting特别说明 特别说明,考虑到编译原理课程考核的时间安排,每天开发时间急剧缩短以至于难以维系正常的Scrum Meeting,因此,将2015/12/13 00:00 ...
- ansj分词史上最详细教程
最近的项目需要使用到分词技术.本着不重复造轮子的原则,使用了ansj_seg来进行分词.本文结合博主使用经过,教大家用最快的速度上手使用ansj分词. 1.给ansj来个硬广 项目的github地址: ...
随机推荐
- php 相关模块备忘
在安装php的时候,不管是编译安装: ./configure --prefix=/usr/local/php --with-config-file-path=/usr/local/php/etc -- ...
- Typescript 中类的继承
Typescript中类的定义与继承与后端开发语言java/C#等非常像,实现起来非常方便,而且代码便于阅读. 用Typescript写较大项目时是非常有优势的. /** * BaseClass */ ...
- C# 如何实现带消息数的App图标
上次写了一篇博文,但是每次更新图标时,桌面会闪烁(刷新),有博友说人家的图标都不会刷新,还能动画.我想了一下,如果要达到这个效果,可以用Form来实现,就是在Form中嵌入一个图片,然后用一个labe ...
- MySQL之MySQL5.7中文乱码
自己的MySQL服务器不能添加中文,于是自己使用 show variables like 'character%'; 查看了当前的编码格式 我又通过以下方法将其设置为utf-8 SETcharacte ...
- go语言最新版本 下载地址
国内官方网站无法打开.放在了百度云中,定期会更新: 链接:http://pan.baidu.com/s/1dD59duh 密码:46ek 备用地址:http://pan.baidu.com/s/1hq ...
- AdaBoost
一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单"听取多人意见,最后综合决策",但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学 ...
- Autodesk的照片建模云服务—Autodesk ReCap 360 photo
现实捕捉技术方兴未艾,简单的讲现实捕捉技术就是把现实中的现状信息数字化到计算机中以便做进一步的处理.对于不同的应用目的会有不同的捕捉设备,工程或传媒娱乐行业中经常用到的肯定就是三维模型了.那如何得到三 ...
- 【Leafletjs】5.L.Control 自定义一个Control
L.Control 所有leaflet控制的基础类.继承自IControl接口. 你可以这样添加控件: control.addTo(map); // the same as map.addContro ...
- Sharepoint学习笔记—习题系列--70-576习题解析 -(Q32-Q35)
Question 32 You are designing the modification of an existing SharePoint 2010 intranet site for a sc ...
- Android NDK之JNI陷阱
背景: 最近一个月一直在做移植库的工作,将c代码到share library移植到Android平台.这就涉及到Android NDK(native develop kit)内容.这里只想记录下JNI ...