理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成:
(1)安装和部署
(3)Ceph 物理和逻辑结构
(4)Ceph 的基础数据结构
(6)QEMU-KVM 和 Ceph RBD 的 缓存机制总结
(8)关于Ceph PGs
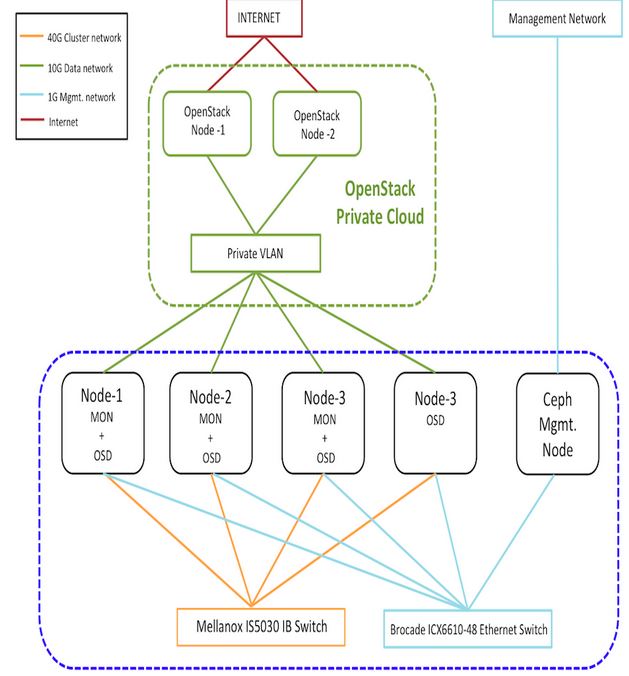
1. 测试环境
为了深入学习 Ceph 以及 Ceph 和 OpenStack 的集成,搭建了如下的测试环境:
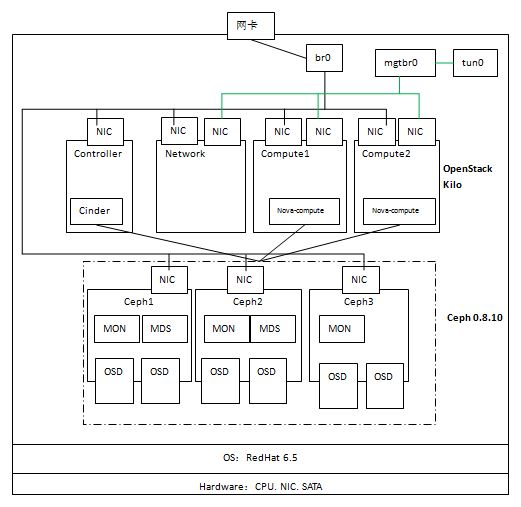
硬件环境:
- System X 服务器一台,CPU、内存和磁盘空间足够
- 服务器只有一个物理网卡
软件环境:
- 服务器安装 RedHat 6.5 操作系统
- OpenStack 使用 Ubuntu 镜像库中的 Kilo master 版本
- 每个节点操作系统采用 Ubuntu 14.04 服务器版
2. Ceph 集群部署
从上图可见,该环境使用三个虚机作为Ceph节点,每个节点上增加两个虚拟磁盘 vda 和 vdb 作为 OSD 存储磁盘,每个节点上安装 MON,前两个节点上安装 MDS。三个节点使用物理网络进行通信。
(0)准备好三个节点 ceph{1,2,3}:安装操作系统、设置 NTP、配置 ceph1 可以通过 ssh 无密码访问其余节点(依次运行 ssh-keygen,ssh-copy-id ceph2,ssh-copy-id ceph3,修改 /etc/ssh/sshd_config 文件中的 PermitRootLogin yes 来使得 ssh 支持 root 用户)
| 节点名称 | IP 地址 | 部署进程 | 数据盘 |
| ceph1 | 192.168.1.194 | 1MON+1MDS+2OSD | /dev/vda, /dev/vdb |
| ceph2 | 192.168.1.195 | 1MON+1MDS+2OSD | /dev/vda, /dev/vdb |
| ceph3 | 192.168.1.218 | 1MON+1OSD | /dev/vda, /dev/vdb |
(1)在 ceph1 上安装 ceph-deploy,接下来会使用这个工具来部署 ceph 集群
(2)在ceph 上,运行 ceph-deploy install ceph{1,2,3} 命令在各节点上安装 ceph 软件。安装好后可以查看 ceph 版本:
root@ceph1:~# ceph -v
ceph version 0.80. (ea6c958c38df1216bf95c927f143d8b13c4a9e70)
(3)在 ceph1 上执行以下命令创建 MON 集群
ceph-deploy new ceph{,,}
ceph-deploy mon create ceph{,,}
ceph-deploy mon create-initial
完成后查看 MON 集群状态:
root@ceph1:~# ceph mon_status
{"name":"ceph1","rank":,"state":"leader","election_epoch":,"quorum":[,,],"outside_quorum":[],"extra_probe_peers":[],"sync_provider":[],"monmap":{"epoch":,"fsid":"4387471a-ae2b-47c4-b67e-9004860d0fd0","modified":"0.000000","created":"0.000000","mons":[{"rank":,"name":"ceph1","addr":"192.168.1.194:6789\/0"},{"rank":,"name":"ceph2","addr":"192.168.1.195:6789\/0"},{"rank":,"name":"ceph3","addr":"192.168.1.218:6789\/0"}]}}
(4)在各节点上准备数据盘,只需要在 fdisk -l 命令输出中能看到数据盘即可,不需要做任何别的操作,然后在 ceph1 上执行如下命令添加 OSD
ceph-deploy --overwrite-conf osd prepare ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda
ceph-deploy --overwrite-conf osd activate ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda ceph-deploy --overwrite-conf osd prepare ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb
ceph-deploy --overwrite-conf osd activate ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb
该命令详细信息:
- 格式: ceph-deploy osd prepare {node-name}:{data-disk}[:{journal-disk}]
- 其中,node-name 表示待创建 OSD 的目标 Ceph 节点;data-disk 表示 OSD 的数据盘;journal-disk 表示日志盘,它可以是一个单独的磁盘,后者 OSD 数据盘上的一个分区,或者一个 SSD 磁盘上的分区。
- 比如:ceph-deploy osd prepare osdserver1:sdb:/dev/ssd 表示在 osdserver1 上使用 sdb 磁盘做数据盘和 /dev/ssd 分区做日志分区来创建一个 OSD 守护进程。
要使得多个OSD数据盘共享一个单独的 SSD 磁盘,首先要使用 fdisk 对该磁盘进行分区,比如下面的命令将 /dev/sdd 分为两个区:
Command (m for help): n
Partition type:
p primary ( primary, extended, free)
e extended
Select (default p):
Using default response p
Partition number (-, default ):
Using default value
First sector (-, default ):
Using default value
Last sector, +sectors or +size{K,M,G} (-, default ):
Using default value Command (m for help): w
The partition table has been altered!
结果是:
Disk /dev/sdd: MB, bytes
heads, sectors/track, cylinders, total sectors
Units = sectors of * = bytes
Sector size (logical/physical): bytes / bytes
I/O size (minimum/optimal): bytes / bytes
Disk identifier: 0x6767c86e Device Boot Start End Blocks Id System
/dev/sdd1 Linux
/dev/sdd2 Linux
此时,执行下面的命令来创建并激活 OSD:
ceph-deploy --overwrite-conf osd prepare ceph1:sdb:/dev/sdd1 ceph2:sdb:/dev/sdd1
ceph-deploy --overwrite-conf osd activate ceph1:sdb1:/dev/sdd1 ceph2:sdb1:/dev/sdd1
注意prepare 和 activate 两个命令参数的区别,前者是使用磁盘,后者是使用分区。
备注:看起来最上面的命令有误,需要修改,TBD。它其实是使用了 /data/osd 目录存放数据,而磁盘 /dev/vda 作为日志盘。
另外,如果是第二次安装的话,需要删除已经存在的 /dev/sdd1 这样的分区,然后再使用命令 ceph-deploy disk zap /dev/sdd 来将其数据全部删除。
完成之后,会将 osd 盘挂载到 /var/lib/ceph/osd 下面的两个目录,目录名为 ceph-<osd id>
/dev/sdc1 on /var/lib/ceph/osd/ceph- type xfs (rw,noatime,inode64)
/dev/sdb1 on /var/lib/ceph/osd/ceph- type xfs (rw,noatime,inode64)
而日志盘则会在各自的 osd 目录下创建一个 link,比如 /var/lib/ceph/osd/ceph-2/journal:
lrwxrwxrwx root root Jun : journal -> /dev/sdd2
完成后查看 OSD 状态:
root@ceph1:~# ceph osd tree
# id weight type name up/down reweight
- 0.1399 root default
- 0.03998 host ceph1
0.01999 osd. up
0.01999 osd. up
- 0.05997 host ceph2
0.01999 osd. up
0.01999 osd. up
- 0.03998 host ceph3
0.01999 osd. up
0.01999 osd. up
(5)将 Admin key 复制到其余各个节点,然后安装 MDS 集群
ceph-deploy admin ceph1 ceph2 ceph3
ceph-deploy mds create ceph1 ceph2
完成后可以使用 “ceph mds” 命令来操作 MDS 集群,比如查看状态:
root@ceph1:~# ceph mds stat
e13: // up {=ceph1=up:active}, up:standby
看起来 MDS 集群是个 active/standby 模式的集群。
至此,Ceph 集群部署完成,可以使用 ceph 命令查看集群状态:
root@ceph1:~# ceph mds stat
e13: // up {=ceph1=up:active}, up:standby
root@ceph1:~# ceph -s
cluster 4387471a-ae2b-47c4-b67e-9004860d0fd0
health HEALTH_OK
monmap e1: mons at {ceph1=192.168.1.194:/,ceph2=192.168.1.195:/,ceph3=192.168.1.218:/}, election epoch , quorum ,, ceph1,ceph2,ceph3
mdsmap e13: // up {=ceph1=up:active}, up:standby
osdmap e76: osds: up, in
在这过程中,失败和反复是难免的,在任何时候,可以使用如下的命令将已有的配置擦除然后从头安装:
ceph-deploy purge ceph{,,}
ceph-deploy purgedata ceph{,,}
ceph-deploy forgetkeys
3. OpenStack 集群部署
3.1 网络准备
为方便起见,管理网络直接连接物理网卡;租户网络就比较麻烦一点,因为机器上只有一个物理网卡,幸亏所有的计算节点都在同一个物理服务器上,因此可以:
1. 在物理服务器上,创建一个虚拟网卡 tap0,再创建一个 linux bridge ‘mgtbr0’
tunctl -t tap0 -u root
chmod /dev/net/tun
ifconfig tap0 0.0.0.0 promisc
brctl addbr mgtbr0
brctl addif mgtbr0 tap0
2. 这是 mgtbr0 的配置脚本:
[root@rh65 ~]# cat /etc/sysconfig/network-scripts/ifcfg-mgtbr0
DEVICE=mgtbr0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=static
IPADDR=10.0.0.100
PREFIX=
GATEWAY=10.0.0.1
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
TYPE=Bridge
3. 在网络和各计算节点上,增加一块网卡,连接到物理服务器上的 bridge。
把所有的节点连接到管理和租户网络后,在物理服务器上看到的 linux bridge 是这样子:
bridge name bridge id STP enabled interfaces
br0 .3440b5d905ee no eth1 #物理网卡
vnet0 #controller 节点
vnet1 #network 节点
vnet2 #compute1 节点
vnet3 #compute2 节点
vnet4 #ceph1 节点
vnet5 #ceph2 节点
vnet8 #ceph3 节点
br1 8000.000000000000 no
mgtbr0 .f29e2c075ca6 no tap0 #虚拟网卡
vnet6 #network 节点
vnet7 #compute1 节点
vnet9 #compute2 节点
3.2 OpenStack 安装和配置
参考 Installation Guide for Ubuntu 14.04 (LTS) 完成配置,没感觉到 Kilo 版本和 Juno 版本太大的不同,除了 keystone 使用 Apache web server 替代了 Keystone WSGI Server 以外(注意不能同时启动 apache2 和 keystone 服务,两者有冲突,感觉 Kilo 版本中 Identity 部分改动很大,还是存在不少问题)。
4. OpenStack 和 Ceph 整合配置
本例中,OpenStack Cinder、Glance 和 Nova 分别会将卷、镜像和虚机镜像保存到 Ceph 分布式块设备(RBD)中。
4.1 Ceph 中的配置
(1)在 ceph 中创建三个 pool 分别给 Cinder,Glance 和 nova 使用
ceph osd pool create volumes
ceph osd pool create images
ceph osd pool create vms
(2)将 ceph 的配置文件传到 ceph client 节点 (glance-api, cinder-volume, nova-compute andcinder-backup)上:
ssh controller sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
ssh compute1 sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
ssh compute2 sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
(3)在各节点上安装ceph 客户端
在 glance-api 节点,安装 librbd
sudo apt-get install python-rbd 在 nova-compute 和 cinder-volume 节点安装 ceph-common:
sudo apt-get install ceph-common
(4)配置 cinder 和 glance 用户访问 ceph 的权限
# cinder 用户会被 cinder 和 nova 使用,需要访问三个pool
ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images' # glance 用户只会被 Glance 使用,只需要访问 images 这个 pool
ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images'
(5)将 client.cinder 和 client.glance 的 keystring 文件拷贝到各节点并设置访问权限
ceph auth get-or-create client.glance | ssh controller sudo tee /etc/ceph/ceph.client.glance.keyring
ssh controller sudo chown glance:glance /etc/ceph/ceph.client.glance.keyring ceph auth get-or-create client.cinder | ssh controller sudo tee /etc/ceph/ceph.client.cinder.keyring
ssh controller sudo chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring ceph auth get-or-create client.cinder | ssh compute1 sudo tee /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh compute2 sudo tee /etc/ceph/ceph.client.cinder.keyring
(6)在 compute1 和 compute2 节点上做 libvirt 配置
ceph auth get-key client.cinder | ssh compute1 tee client.cinder.key
cat > secret.xml <<EOF
<secret ephemeral='no' private='no'>
<uuid>e21a123a-31f8-425a-86db-7204c33a6161</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
EOF
sudo virsh secret-define --file secret.xml
sudo virsh secret-set-value --secret e21a123a-31f8-425a-86db-7204c33a6161 --base64 $(cat client.cinder.key) && rm client.cinder.key secret.xml
4.2 OpenStack 中的配置
4.2.1 Glance 中的配置
在 /etc/glance/glance-api.conf 文件中做如下修改: [DEFAULT]
...
show_image_direct_url = True
...
[glance_store]
stores=glance.store.rbd.Store (设置为 rbd 也可以?)
default_store = rbd
rbd_store_pool = images
rbd_store_user = glance
rbd_store_ceph_conf = /etc/ceph/ceph.conf
rbd_store_chunk_size =
注意:如果在创建 image 时候出现 AttributeError: 'NoneType' object has no attribute 'Rados' 错误,则需要安装 python-rados
4.2.2 配置 Cinder volume
修改 /etc/cinder/cinder.conf: [DEFAULT]
...
#volume_group = cinder-volumes
volume_driver = cinder.volume.drivers.rbd.RBDDriver
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = false
rbd_max_clone_depth =
rbd_store_chunk_size =
rados_connect_timeout = -
glance_api_version =
rbd_user = cinder
rbd_secret_uuid = e21a123a-31f8-425a-86db-7204c33a6161
...
注意:
(1)cinder-volume 节点上的 ceph 配置文件是必须存在的,因为 cinder-volume 需要使用它来建立和 Ceph 集群的连接,不存在的话则会报错误。
cinder/volume/drivers/rbd.py 文件:
client = self.rados.Rados(rados_id=self.configuration.rbd_user, conffile=self.configuration.rbd_ceph_conf)
缺失 ceph 配置文件时 cinder-volume 报错:
-- ::54.127 INFO cinder.volume.manager [req-d921feed-db0b--b01b-13dde3da6285 - - - - -] Starting volume driver RBDDriver (1.1.)
-- ::54.162 ERROR cinder.volume.manager [req-d921feed-db0b--b01b-13dde3da6285 - - - - -] Error encountered during initialization of driver: RBDDriver
-- ::54.163 ERROR cinder.volume.manager [req-d921feed-db0b--b01b-13dde3da6285 - - - - -] error calling conf_read_file: errno EINVAL
对 cinder-volume 来说,它所需要的 ceph.conf 中的信息主要是 MON 服务器的地址,以及cinder 所使用的用户的验证方式,因此需要将 keystring 文件 ceph.client.cinder.keyring 放在同一个目录下面。
mon_initial_members = ceph1, ceph2, ceph3
mon_host = 9.115.251.194,9.115.251.195,9.115.251.218
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
filestore_xattr_use_omap = true
(2)可以支持 multi-backend 配置,在每个 backend 中使用不同的 Ceph pool,甚至使用不同的 rbd_ceph_conf 来支持多个 Ceph 集群。
做完以上配置之后,你就可以通过cinder 在 Ceph 中创建 volume 了。
4.3.3 配置 Nova Compute
其实 nova compute 使用 RBD 有两种功能:
- 一种是将 cinder volume 挂接给虚拟机
- 另一种是从 cinder volume 上启动虚拟机,此时 nova 需要创建一个 RBD image,把 glance image 的内容导入,再交给 libvirt
4.3.3.1 将 cinder volume 挂接给 nova instance
修改 nova compute 节点上的 nova.conf 文件:
[libvirt]
rbd_user = cinder
rbd_secret_uuid = e21a123a-31f8-425a-86db-7204c33a6161
如果只是将 ceph volume 挂接到 Nova 虚机的话,nova-compute 是不需要从 ceph 配置文件中读取 MON 服务器的信息的,而是调用 cinder api 去获取。因此,在计算节点上缺失 ceph 配置文件其实是不影响将 ceph 卷挂接到 nova 虚机的。 注意这是 Havana 以后的行为,对于之前的版本,nova-compute 从 ceph 配置文件中读取 MON 信息,因此需要 ceph 配置文件。详见 ticket:Nova failed to mount a RBD volume without extra ceph.conf。做了这个改动以后,另一个好处是,向 nova 支持多个 ceph 集群提供了可能,因为使用 ceph 配置文件的话只能使用一个文件,而 cinder 中可以 使用 multi-backend 技术来支持多个 ceph 集群。
所以 nova.conf 中主要是配置访问 ceph 的 user 和 secret id,以便从本机上保存的 secrets 中获取密钥。配置文件中只保存有 rbd secret id,因为本机上需要有该 id 对应的 secret的完整内容。
关于为什么只需要这两个参数,还可以阅读 LibvirtNetVolumeDriver 类的代码,该类实现了 libirt 访问 Ceph 等网络存储的功能。
在执行 nova attach-volume 之后(如下图步骤5),nova-compute 会修改 nova instance 的 libvirt xml 文件。示例如下:
<disk type='network' device='disk'>
<driver name='qemu' type='raw' cache='writeback'/>
<auth username='cinder'>
<secret type='ceph' uuid='e21a123a-31f8-425a-86db-7204c33a6161'/>
</auth>
<source protocol='rbd' name='volumes/volume-b4e9a905-d59e-46e4-aa6d-e57c90000013'>
<host name='9.115.251.194' port='6789'/>
<host name='9.115.251.195' port='6789'/>
<host name='9.115.251.218' port='6789'/>
</source>
<backingStore/>
<target dev='vdb' bus='virtio'/>
<serial>b4e9a905-d59e-46e4-aa6d-e57c90000013</serial>
<alias name='virtio-disk1'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</disk>
因此,如果只是需要支持将 Ceph 卷挂接到 nova 虚机的话,可以在计算节点上的 ceph 配置文件中,可以只保留 client 部分的配置信息,包括 RBD Cache 的配置以及日志配置等,这样就可以避免和具体哪一个 Ceph 集群的硬绑定。而这个配置其实是给 librbd 准备的,便于对它进行调试。下面是一个配置示例:
[client]
rbd cache = true
#rbd cache = false
#rbd cache writethrough until flush = true
#admin socket = /var/run/ceph/$cluster-$type.$id.$pid.$cctid.asok
log file = /var/log/ceph/qemu-guest.$pid.log
#log file = /var/lib/libvirt/qemu/qemu-guest.$pid.log
admin socket=/var/log/ceph/rbd-$pid.asok
debug rbd = 20
debug rbd = 20,
debug objectcacher=20
debug objecter=20
debug ms = 1
挂接 Ceph RBD 卷给虚机的大致交互流程如下:
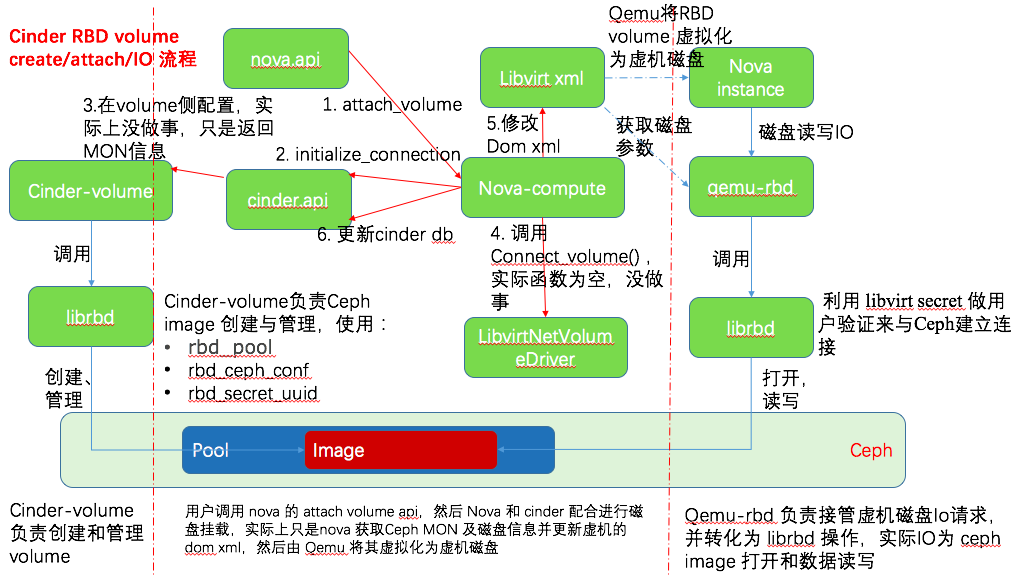
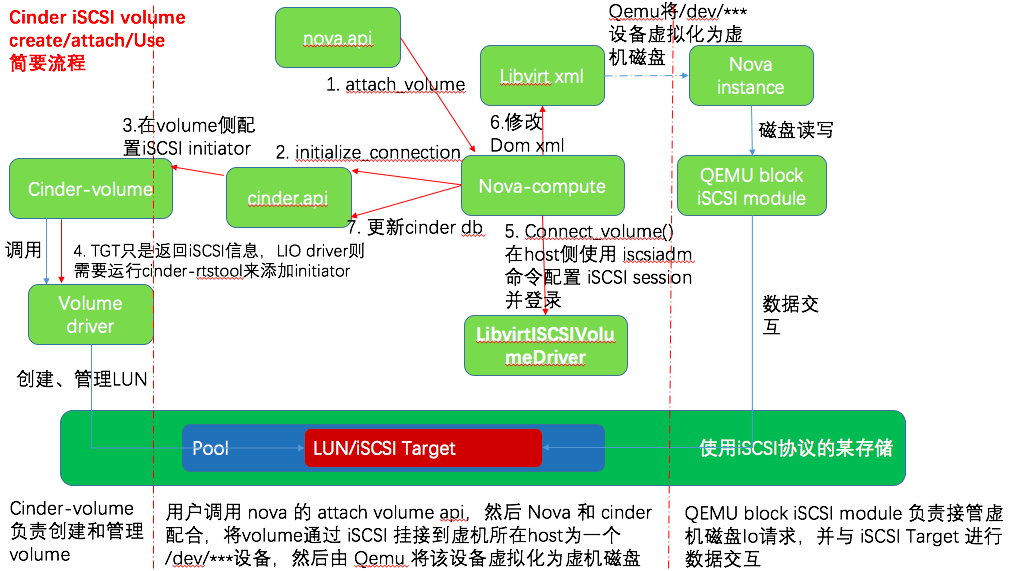
作为参考,下图为挂接 iSCSI volume 给虚机的大致流程,可以看出来挂接 Ceph volume 的流程简化了很多,因为不需要做 iSCSI 配置:
说明:
- 与 Ceph RBD volume 流程相比,这里面还需要 cinder volume driver 在 iSCSI Target 侧做 initiator 配置,还需要 libvirtISCSIVolumeDriver 在 host 侧进行 iSCSI session 配置,这样才能在 host 和 volume 之间建立起 iSCSI session,供 Qemu block iSCSI module 使用。
- 如果是 TGT iSCSI 的话,上图第4步返回的iSCSI信息的示例
{‘driver_volume_type’: ‘iscsi’, ‘data’: {‘auth_password’: ‘YZ2Hceyh7VySh5HY’,
‘target_discovered’: False,
‘encrypted’: False,
‘qos_specs’: None,
‘target_iqn’: ‘iqn.-.org.openstack:volume-8b1ec3fe-8c5
‘target_portal’: ‘11.0.0.8:′,
‘volume_id’: ‘8b1ec3fe-8c57-45ca-a1cf-a481bfc8fce2′,
‘target_lun’: ,
‘access_mode’: ‘rw’,
‘auth_username’: ‘nE9PY8juynmmZ95F7Xb7′,
‘auth_method’: ‘CHAP’}}
- Dom xml 中 iSCSI 磁盘的信息示例
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native'/>
<source dev='/dev/disk/by-path/ip-10.0.0.2:3260-iscsi-iqn.2010-10.org.openstack:volume-2ed1b04c-b34f-437d-9aa3-3feeb683d063-lun-0'/>
<target dev='vdb' bus='virtio'/>
<serial>2ed1b04c-b34f-437d-9aa3-3feeb683d063</serial>
<address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</disk>
4.3.3.2 nova 从 cinder volume 上启动
在每个计算节点上的 /etc/nova/nova.conf 文件中做如下修改。与 4.3.3.1 中的配置相比,增加了 images 相关配置,这是因为 nova-compute 需要自己管理 rbd image 了(实现是通过 RBD imagebackend,它会调用 rbd 命令来创建 volume 并导入 image,并在需要的时候做 resize)。
[libvirt]
images_type = rbd #只有在 boot disk 放在 ceph 中才需要配置这个,否则,设置为 qcow2
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_user = cinder
rbd_secret_uuid = e21a123a-31f8-425a-86db-7204c33a6161 disk_cachemodes="network=writeback"
hw_disk_discard = unmap
inject_password = false
inject_key = false
inject_partition = -
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED"
当用户选择将 boot disk 放在 Ceph 中的话,需要在 nova.conf 中配置 images_rbd_ceph_conf ,这是因为就像 cinder-volume 一样,nova-compute 需要使用 ceph.conf 和其它参数创建和 Ceph 的连接,然后使用 ”rbd import --pool “命令来创建 image。这种情况下,如果没有 ceph.conf 文件的话,启动 nova-compute 服务时就会报错:
-- ::30.920 ERROR nova.openstack.common.threadgroup [req-9a61379c-52e9-48b7-9f7c-91c928fdaf2b - - - - -] error calling conf_read_file: errno EINVAL
因此,此时的 nova-compute 和 glance 以及 cinder-volume 的角色没什么不同,它们也需要使用相同的 ceph 配置文件。
至此,环境安装和配置完成,通过 cinder,glance 和 nova 命令创建的卷、镜像和虚机的镜像都会被保存在 Ceph 的 RBD 中。接下来的文章会深入分析其中的原理和实现。
参考文档:
- http://docs.ceph.com/docs/master/rbd/rbd-openstack/
- nova与cinder服务交互
- Ceph 官方的一个测试环境:(来源:http://ceph.com/category/performance-2/)
理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置的更多相关文章
- Zookeeper集群部署与配置(三)
在上一篇博客中我们讲解了<Zookeeper的单机配置>,此篇博客将继续介绍Zookeeper的集群部署与配置. 环境 集群配置的环境与单机配置的环境相同,唯一不同的就是集群是在多台服务器 ...
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
- openstack(pike 版)集群部署(一)----基础环境部署
一.环境 1.系统: a.CentOS Linux release 7.4.1708 (Core) b.更新yum源和安装常用软件 # yum -y install epel-release ba ...
- Redis cluster 集群部署和配置
目录 一.集群简介 cluster介绍 cluster原理 cluster特点 应用场景 二.集群部署 环境介绍 节点部署 启动集群 三.集群测试 一.集群简介 cluster介绍 redis clu ...
- openstack(Pike 版)集群部署(八)--- 连接Ceph Cluster 作为后端存储
一.openstack Glance + ceph Cluster 部署: 博客:http://www.cnblogs.com/weijie0717/p/8563294.html 参考 续 部分. ...
- openstack(Pike 版)集群部署(七)--- Cinder 部署
一.介绍 参照官网部署:https://docs.openstack.org/cinder/pike/install/index-rdo.html 继续上一博客进行部署:http://www.cnbl ...
- openstack(Pike 版)集群部署(三)--- Glance 部署
一.介绍 参照官网部署:https://docs.openstack.org/glance/queens/install/ 继续上一博客进行部署:http://www.cnblogs.com/weij ...
- openstack(2) -------RabbitMQ集群部署
一.RabbitMQ简介 RabbitMQ属于一个流行的开源消息队列系统.属于AMQP( 高级消息队列协议 ) 标准的一个 实现.是应用层协议的一个开放标准,为面向消息的中间件设计.用于在分布式系统中 ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
随机推荐
- 设计模式之 面向对象的养猪厂的故事,C#演示(一)
对于设计模式, 从本质上说, 其最大的用途就是适应需求的变化. 因为有了设计模式,我们可以在设计阶段就为未来可能发生的变化留下足够的空间. 我们通过一个建造现代化养猪场的故事, 来讨论一下设计模式与需 ...
- Node.js+Express配置入门
Node.js是一个Javascript运行环境(runtime).实际上它是对Google V8引擎进行了封装.V8引 擎执行Javascript的速度非常快,性能非常好.Node.js对一些特殊用 ...
- 图解.NET Stack和Heap的本质区别
现在越来越觉得对.NET基本概念的理解和掌握对于提升编程水平的重要性,先从.NET的 Stack(栈)和Heap(堆)说起,计算机的内存可以分为代码块内存,stack内存和heap内存.代码块内存是在 ...
- Java Swing快速构建窗体应用程序
以前接触java感觉其在桌面开发上,总是不太方便,没有一个好的拖拽界面布局工具,可以快速构建窗体. 最近学习了一下NetBeans IDE 8.1,感觉其窗体设计工具还是很不错的 , 就尝试一下做了一 ...
- 【移动适配】移动Web怎么做屏幕适配(三)
复杂纷扰的世界背后,总会有万变不离其宗的简单规则 啃先生 Mar.8th.2016 壹 | Fisrt 前面写了两篇移动适配相关的文章: <移动Web怎么做屏幕适配(一)>重点介绍了怎样利 ...
- sharepoint 开发相关工具总结
1.CAML Designer 2013 开发caml用 http://biwug-web.sharepoint.com/SitePages/Caml_designer.aspx 2.SharePoi ...
- Java中的引用类型(强引用、弱引用)和垃圾回收
Java中的引用类型和垃圾回收 强引用Strong References 强引用是最常见的引用: 比如: StringBuffer buffer = new StringBuffer(); 创建了一个 ...
- JAVA Web 实现会话跟踪的技术笔记
1.HTTP协议无状态:客户端的请求与服务器的响应所发生的一系列行为简单的说是客户发送了请求,服务器就给客户端响应,它们彼此之间都没有记录下来.如: 顾客与自动售货机 普通顾客(非会员)与商场 2.c ...
- Android 加载大图片到内存
本文演示android中图片加载到内存 首先设计界面: 代码如下: <LinearLayout xmlns:android="http://schemas.android.com/ap ...
- iOS cookie问题
获取cookie时汉字应转换为UTF8格式