Kubernetes自动横向伸缩集群节点以及介绍PDB资源
在kubernetes中,有HPA在需要的时候创建更多的pod实例。但万一所有的节点都满了,放不下更多pod了,怎么办?显然这个问题并不局限于Autoscaler创建新pod实例的场景。即便是手动创建pod,也可能碰到因为资源被已有pod使用殆尽,以至于没有节点能接收新pod的清况。
在这种情况下,需要删除一些已有的pod, 或者纵向缩容它们,抑或向集群中添加更多节点。如果Kubernetes集群运行在自建基础架构上,那得添加一台物理机,并将其加入集群。但如果集群运行于云端基础架构之上,添加新的节点通常就是点击几下鼠标,或者向云端做API调用。这可以自动化的,对吧?
Kubernetes支持在需要时立即自动从云服务提供者请求更多节点。该特性由Cluster Autoscaler执行。
1.Cluster Autoscaler介绍
Cluster Autoscales负责在由于节点资源不足,而无法调度某pod到己有节点时,自动部署新节点。它也会在节点长时间使用率低下的情况下下线节点。
从云端基础架构请求新节点
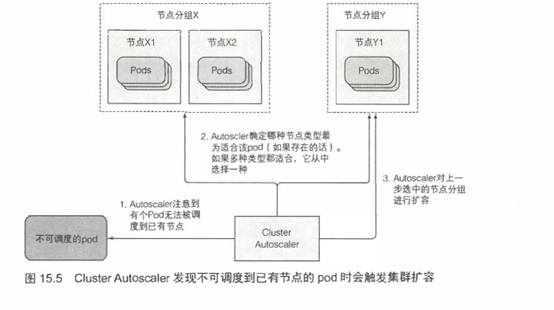
如果在一个pod被创建之后,Scheduler无法将其调度到任何一个己有节点,一个新节点就会被创建。ClusterAutoscaler会注意此类pod,并请求云服务提供者启动一个新节点。但在这么做之前,它会检查新节点有没有可能容纳这个(些)pod,毕竟如果新节点本来就不可能容纳它们,就没必要启动这么一个节点了。
云服务提供者通常把相同规格(或者有相同特性)的节点聚合成组。因此ClusterAutoscaler不能单纯地说“给我多一个节点”,它还需要指明节点类型。
ClusterAutoscaler通过检查可用的节点分组来确定是否有至少一种节点类型能容纳未被调度的pod。如果只存在唯一一此种节点分组,ClusterAutoscaler就可以增加节点分组的大小,让云服务提供商给分组中增加一个节点。但如果存在多个满足条件的节点分组,ClusterAutoscaler就必须挑一个最合适的。这里“最合适”的精确含义显然必须是可配置的。在最坏的情况下,它会随机挑选一个。图15.5简单描述了ClusterAutoscaler面对一个不可调度pod时是如何反应的。
新节点启动后,其上运行的Kubelet会联系API服务器,创建一个Node资源以注册该节点。从这一刻起,该节点即成为Kubernetes集群的一部分,可以调度pod于其上了。
简单吧?那么缩容呢?
归还节点
当节点利用率不足时,Cluster Autoscaler也需要能够减少节点的数目。Cluster Autoscaler通过监控所有节点上请求的CPU与内存来实现这一点。如果某个节点上所有pod请求的CPU、内存都不到50%,该节点即被认定为不再需要。
这并不是决定是否要归还某一节点的唯一因素。Cluster Autoscaler也会检查是否有系统pod(仅仅)运行在该节点上(这并不包括每个节点上都运行的服务,比如DaemonSet所部署的服务)。如果节点上有系统pod在运行,该节点就不会被归还。对非托管pod,以及有本地存储的pod也是如此,否则就会造成这些pod提供的服务中断。换句话说,只有当Cluster Autoscaler知道节点上运行的pod能够重新调度到其他节点,该节点才会被归还。
当一个节点被选中下线,它首先会被标记为不可调度,随后运行其上的pod将被疏散至其他节点。因为所有这些pod都属于ReplicaSet或者其他控制器,它们的替代pod会被创建并调度到其他剩下的节点(这就是为何正被下线的节点要先标记为不可调度的原因)。
手动标记节点为不可调度、排空节点
节点也可以手动被标记为不可调度并排空。不涉及细节,这些工作可用以下kubectl命令完成:
- kubectl cordon <node>标记节点为不可调度(但对其上的pod不做任何事)。
- kubectl drain <node>标记节点为不可调度,随后疏散其上所有pod。
两种情形下,在你用kubectl uncordon <node>解除节点的不可调度状态之前,不会有新pod被调度到该节点。
2.启用Cluster Autoscaler
集群自动伸缩在以下云服务提供商可用:
- Google Kubernetes Engine(GKE)
- Google Compute Engine(GCE)
- Amazon Web Services(AWS)
- Microsoft Azure
启动Cluster Autoscaler的方式取决于Kubernetes集群运行在哪。如果你的kubia集群运行在GKE上,可以这样启用Cluster Autoscaler :
$ gcloud container clusters update kubia --enable-autoscaling \
--min-nodes=3 --max-nodes=5
如果集群运行在GCE上,需要在运行kubi-ub.sh前设置以下环境变量:
- KUBE ENABLE CLUSTER AUTOSCALER=true
- KUBE AUTOSCALER MIN NODES=3
- KUBE AUTOSCALER MAX NODES=5
可以参考https://github.com/kubemetes/auto-scaler/tree/master/cluster-autoscaler上的ClusterAutoscaler GitHub版本库,来了解在其他平台上如何启用它。
注意:Cluster Autoscaler将它的状态发布到kube-system命名空间的cluster-autoscale-status ConfigMap上。
至于很多云开启的方式去查找云平台的官方文档。
3.限制集群缩容时的服务干扰
如果一个节点发生非预期故障,不可能阻止其上的pod变为不可用;但如果一个节点被Cluster Autoscaler或者人类操作员主动下线,可以用一个新特性来确保下线操作不会干扰到这个节点上pod所提供的服务。
一些服务要求至少保持一定数量的pod持续运行,对基于quorum的集群应用而言尤其如此。为此,Kubernetes可以指定下线等操作时需要保持的最少pod数量,通过创建一个podDisruptionBudget资源的方式来利用这一特性。
尽管这个资源的名称听起来挺复杂的,实际上它是最简单的Kubernetes资源之一。它只包含一个pod标签选择器和一个数字,指定最少需要维持运行的pod数量,从Kubernetes1.7开始,还有最大可以接收的不可用pod数量。看看PodDisruptionBudget(PDB)资源长什么样,但不会通过YAML文件来创建它。将用kubectl create podDisruptionBudget命令创建它,然后再查看一下YAML文件。
如果想确保kubia pod总有3个实例在运行(它们有app=kubia这个标签),像这样创建PodDisruptionBudget资源:
$ kubectl create pdb kubia-pdb --selector=app=kubia --min-available=3
poddisruptionbudget "kubia-pdb" created
现在获取这个PDB的YAML文件,如下代码:
#代码15.10 一个podDisruptioonBudget定义
$ kubectl get pdb kubia-pdb -o yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: kubia-pdb
spec:
minAvailable:3 #应该有多少个pod始终可用
selector:
matchLabels: #用来确定该预算应该覆盖哪些pod的标签选择器
app: kubia
status:
....
也可以用一个百分比而非绝对数值来写minAvailable字段。比方说,可以指定60%带app=kubia标签的pod应当时刻保持运行。
注意:从Kubernetes1.7开始,podDismptionBudget资源也支持maxUnavailable。如果当很多pod不可用而想要阻止pod被剔除时,就可以用maxUnavailable字段而不是minAvailable。
关于这个资源,没有更多要讲的了。只要它存在,Cluster Autoscaler与kubectl drain命令都会遵守它;如果疏散一个带有app=kubia标签的pod会导致它们的总数小于3,那这个操作就永远不会被执行。
比方说,如果总共有4个pod,minAvailable像例子中一样被设为3,pod疏散过程就会挨个进行,待ReplicaSet控制器把被疏散的pod换成新的,才继续下一个。
Kubernetes自动横向伸缩集群节点以及介绍PDB资源的更多相关文章
- db2 数据库配置HADR+TSA添加集群节点
Db2配置HADR高可用+TSA添加集群节点 一.服务器资源 Master IP:10.78.10.1 数据库:dbclassSlave IP:10.78.10.2 数据库:dbclassVIP:10 ...
- Kubernetes从懵圈到熟练:读懂这一篇,集群节点不下线
排查完全陌生的问题,完全不熟悉的系统组件,是售后工程师的一大工作乐趣,当然也是挑战.今天借这篇文章,跟大家分析一例这样的问题.排查过程中,需要理解一些自己完全陌生的组件,比如systemd和dbus. ...
- Akka(12): 分布式运算:Cluster-Singleton-让运算在集群节点中自动转移
在很多应用场景中都会出现在系统中需要某类Actor的唯一实例(only instance).这个实例在集群环境中可能在任何一个节点上,但保证它是唯一的.Akka的Cluster-Singleton提供 ...
- kubernetes集群节点多网卡,calico指定网卡
kubernetes集群节点多网卡,calico指定网卡 1.calico如果有节点是多网卡,所以需要在配置文件中指定内网网卡 spec: containers: - env: - name: DAT ...
- 使用kubeadm搭建Kubernetes(1.10.2)集群(国内环境)
目录 目标 准备 主机 软件 步骤 (1/4)安装 kubeadm, kubelet and kubectl (2/4)初始化master节点 (3/4) 安装网络插件 (4/4)加入其他节点 (可选 ...
- 【葵花宝典】lvs+keepalived部署kubernetes(k8s)高可用集群
一.部署环境 1.1 主机列表 主机名 Centos版本 ip docker version flannel version Keepalived version 主机配置 备注 lvs-keepal ...
- 被集群节点负载不均所困扰?TKE 重磅推出全链路调度解决方案
引言 在 K8s 集群运营过程中,常常会被节点 CPU 和内存的高使用率所困扰,既影响了节点上 Pod 的稳定运行,也会增加节点故障的几率.为了应对集群节点高负载的问题,平衡各个节点之间的资源使用率, ...
- Kubernetes(k8s)部署redis-cluster集群
Redis Cluster 提供了一种运行 Redis 安装的方法,其中数据 在多个 Redis 节点之间自动分片. Redis Cluster 还在分区期间提供了一定程度的可用性,这实际上是在某些节 ...
- 使用国内的镜像源搭建 kubernetes(k8s)集群
1. 概述 老话说的好:努力学习,提高自己,让自己知道的比别人多,了解的别人多. 言归正传,之前我们聊了 Docker,随着业务的不断扩大,Docker 容器不断增多,物理机也不断增多,此时我们会发现 ...
随机推荐
- 普里姆(Prim)算法
概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图(即"带权图")里搜索最小生成树.即此算法搜索到的边(Edge)子集所构成的树中,不但包括了连通图里的所有顶点(V ...
- linux自动化交互脚本expect详解set timeout 5是 意思是在expect语句中,5s后超时,不再作出选择。
linux自动化交互脚本expect详解 更新时间:2020年10月21日 10:13:20 作者:lendsomething 这篇文章主要介绍了linux自动化交互脚本expect的相 ...
- 怎样使用yum-cron为CentOS7自动更新重要的安全补丁
怎样使用yum-cron为CentOS自动更新重要的安全补丁 2017年4月19日 | 分类: [技术] 参考:https://linux.die.net/man/8/yum-cron参考:http: ...
- 020.Python生成器和生成器函数
一 生成器 1.1 基本概念 元组推导式是是生成器(generator) 生成器定义 生成器可以实现自定义,迭代器是系统内置的,不能够更改 生成器的本质就是迭代器,只不过可以自定义. 生成器有两种定义 ...
- Centos 7.4搭建es7.12.0+Skywalking7.8.5
Skywalking整体架构图和分布式追踪系统原理:https://blog.csdn.net/weixin_39866487/article/details/111581322 软件包版本1.ela ...
- python3 xlutils对Excel追加内容
在实际应用中我们通常会需要向一个Excel中追加内容,但是在python3中xlwt用起来有点不太方便,下面介绍一下xlutils包的用法,xlutils包依赖于xlrd包,所以需要导入xlrd包,还 ...
- MyBatisPlus详细总结记录
本文由 简悦 SimpRead 转码, 原文地址 mp.weixin.qq.com 小 Hub 领读: 一篇写得非常详细的文章,增删改查,各种插件,让你测底熟悉 mybatis plus. 作者:yo ...
- Archlinux常用软件推荐 更新于2021年4月
记录一下常用软件 必装软件 包管理工具 yay 代替pacman的包管理 yaourt 备用 终端工具 zsh oh-my-zsh-git 搭配zsh利器` proxychains4 终端代理工具` ...
- MongoDB(12)- 查询嵌入文档的数组
插入测试数据 db.inventory.insertMany( [ { item: "journal", instock: [ { warehouse: "A" ...
- GO学习-(13) Go语言基础之结构体
Go语言基础之结构体 Go语言中没有"类"的概念,也不支持"类"的继承等面向对象的概念.Go语言中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性. ...