mysql总结:索引,存储引擎,大批量数据插入,事务,锁
mysql总结
索引概述:
索引是高效获取数据的数据结构
索引结构:
B+Tree()
Hash(不支持范围查询,精准匹配效率极高)
存储引擎:
常见存储引擎:
Myisam:5.5之前默认引擎,支持表锁,不支持外键和事务,查询插入性能很高
InnoDB:支持事务,外键,支持行级锁,5.5之后默认存储引擎,5.6之后支持全文索引
Memory:所有数据置于内存中,拥有极高的效率,但是重启数据会丢失
Archive:拥有很快的插入速度,但是查询相对差劲
Federated:将不同的mysql服务器联合,逻辑形成一个完整的数据库,适合分布式场景
树的区别:
二叉树:可能产生不平衡,顺序数据可能会出现链表结构
平衡二叉树:插入需要自旋,性能根据层级而定,性能不稳定
b+tree:
主键聚簇叶子节点存放数据,非叶子节点存放索引,
二级索引非叶子节点存放索引,叶子节点存放主键
索引优缺点:
优点:
大大加快查询速度
使用分组和排序时候可以显著减少分组和排序时间
唯一索引可以保证字段唯一
可以加速表与表之间的连接
缺点
创建和维护索引需要消耗时间,随着数据量增加时间也会增加
占用磁盘空间
对表进行urd操作时候也要动态维护,urd性能会下降
创建索引原则(我们对哪种数据创建索引):
更新频繁数据不易创建索引
数据量少的没必要创建,全表和用索引可能差不多
首先考虑在where和orderby字段建立索引
索引分类:
单列索引(只包含单个列):
主键索引:唯一且不为null,一个表只能有一个,(聚集索引:叶子节点下存储数据)
唯一索引:唯一且只能有一个Null值(二级索引,叶子节点存储主键)
普通索引:没有限制(二级索引,叶子节点存储主键)
组合索引/复合索引(包含多列):
为了避免回表,进行更高效的查询
全文索引:
like+%(InnoDB(5.6之后支持)默认3个字符,最大84,MyISam默认4最小1个字符)
空间索引(使用较少)
Sql性能分析
数据库的执行频次
- show session status like 'Com_____'; --查询当前会话统计结果
- show global status like 'Com_____'; --查询字数据库上次启动至今的结果
- show status like 'Innodb_rows_%';
慢查询日志
-- 查看慢日志配置信息
show variables like '%slow_query_log%’;
-- 开启慢日志查询
set global slow_query_log=1;
-- 查看慢日志记录SQL的最低阈值时间
show variables like 'long_query_time%’;
-- 修改慢日志记录SQL的最低阈值时间
set global long_query_time=4;
profile Sql执行查询
explain/desc执行计划查询
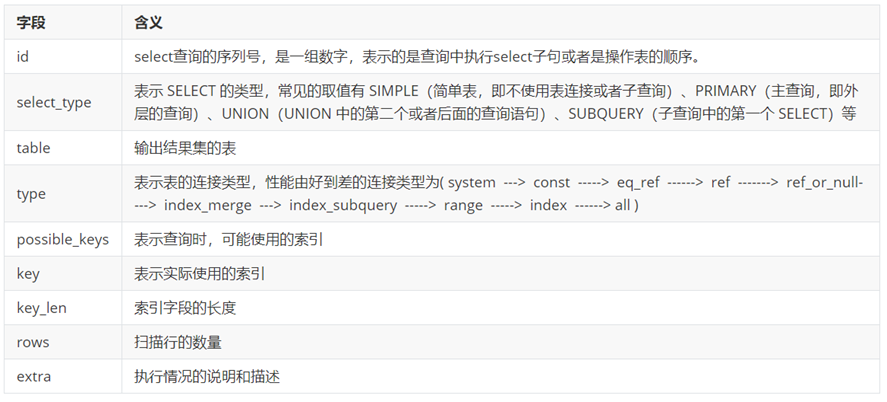
id 相同表示加载表的顺序是从上到下。
id 不同id值越大,优先级越高,越先被执行。
id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
type含义

extra含义

索引使用
联合索引:
遵循最左原则,如果最左使用中间跳过了某个字段,会造成后面索引失效,范围查询右侧的列会失效,尽量是<= ,>=
索引失效:
索引列进行了函数运算
没有遵循最有匹配原则
字符串类型索引没有加'',造成隐士转换,导致索引失效
左模糊查询
如果最左使用中间跳过了某个字段,会造成后面索引失效,范围查询右侧的列会失效,尽量是<= ,>=
mysql优化器判定全表比用索引块
or链接索引失效
sql提示:
多个索引下,可以提醒执行器是由哪个索引,建议使用,忽略使用,强制使用
覆盖索引:
查询返回字段都在联合索引中会直接拿到数据,避免回表即联合索引
前缀索引:
针对字段数据库较大的建立索引,缩小索引长度
单列/联合索引:
避免单列索引在and情况下第二索引不生效,使用联合索引,使用恰当可避免回表
索引设计原则
表层面:数据量大,且查询频繁
字段层面:经常在where groupby orderby后的字段
索引层: 唯一的建立唯一索引,尽量联合索引,大文本尽量前缀索引
附加原则:
区分度较高
索引不易过多
索引不为null加上非空约束
所长度尽量短
锁机制
锁的分类:
按粒度分:
全局锁:锁定全局,用于数据备份保证数据库完整性
表锁(加锁快,并发低,不会死锁):
表锁:锁定整张表
元数据锁:保证数据完整执行,修改的锁会和所有锁冲突
意向锁:为了避免加表锁时候,全局扫描行锁
行锁(加锁慢,锁冲突低,并发高,会死锁)
行锁:锁定单行数据
间隙锁:锁定间隙,不包含当前数据
临键锁:锁定当前数据和间隙(行锁+间隙锁)
按类型分:
读锁(共享):阻塞写,可读
写锁(排他):阻塞读写
事务
事务隔离级别:
读未提交:一个事务可以读取另一个事务未提交的数据(脏读,不可重复读,幻读)
读已提交:可读取另一个事务已经提交的事务(不可重复读,幻读)
不可重复读(默认):事务开启时不在允许修改操作,可避免脏读,不可重复读但是会造成(幻读)
串行化:最高事务隔离级别,效率低下
大批量数据插入优化
主键顺序插入
批量插入减少IO,批量最好500左右
load加载数据至数据结构
-- 1、首先,检查一个全局系统变量 'local_infile' 的状态, 如果得到如下显示 Value=OFF,则说明这是不可用的
show global variables like 'local_infile';
-- 2、修改local_infile值为on,开启local_infile
set global local_infile=1;
-- 3、加载数据
/*
脚本文件介绍 :
sql1.log ----> 主键有序
sql2.log ----> 主键无序
*/
load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
关闭唯一性校验,加载后再打开
-- 关闭唯一性校验
SET UNIQUE_CHECKS=0;
truncate table tb_user;
load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
SET UNIQUE_CHECKS=1;
减少事务,批量执行数据
mysql总结:索引,存储引擎,大批量数据插入,事务,锁的更多相关文章
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL最全存储引擎、索引使用及SQL优化的实践
1 MySQL的体系结构概述 整个MySQL Server由以下组成 :Connection Pool :连接池组件Management Services & Utilities :管理服务和 ...
- 重新学习MySQL数据库3:Mysql存储引擎与数据存储原理
重新学习Mysql数据库3:Mysql存储引擎与数据存储原理 数据库的定义 很多开发者在最开始时其实都对数据库有一个比较模糊的认识,觉得数据库就是一堆数据的集合,但是实际却比这复杂的多,数据库领域中有 ...
- Mysql 版本号、存储引擎、索引查询
[1]Mysql 版本号.存储引擎.索引查询 # 查看数据库版本号 SELECT VERSION(); # 查看数据库支持的引擎(默认即Support == DEFAULT行) SHOW ENGINE ...
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- MySQL支持多种存储引擎
MySQL的强大之处在于它的插件式存储引擎,我们可以基于表的特点使用不同的存储引擎,从而达到最好的性能. MySQL有多种存储引擎:MyISAM.InnoDB.MERGE.MEMORY(HEAP).B ...
- MySQL存储引擎,优化,事务
1唯一约束unique和主键key的区别? 1.什么是数据的存储引擎? 存储引擎就是如何存储数据.如何为存储的数据建立索引和如何更新.查询数据等技术的实现方法.因为在关系数据库中数 ...
- MySQL的常见存储引擎介绍与参数设置调优
MySQL常用存储引擎之MyISAM 特性: 1.并发性与锁级别 2.表损坏修复 check table tablename repair table tablename 3.MyISAM表支持的索引 ...
随机推荐
- maven中profiles使用详解
使用的场景 常常遇到一些项目中多环境切换的问题.比如在开发过程中用到开发环境,在测试中使用测试环境,在生产中用生产环境的情况.springboot中提供了 spring.profile.active的 ...
- JAVA异常与异常处理详解【转】
感谢!!!原文地址:https://www.cnblogs.com/knightsu/p/7114914.html 一.异常简介 什么是异常? 异常就是有异于常态,和正常情况不一样,有错误出错.在ja ...
- Eclipse集成Git/SVN插件及使用
感谢大佬:https://www.cnblogs.com/jpfss/p/8027347.html 1. Git插件安装 1.1 下载插件 首先打开Eclipse,然后点击Help>Instal ...
- action标签中method={1}怎么理解
其实用到method={数字}的时候,相应的前面的action是要出现*通配符来搭配的.比如一个小例子:<action name="user_*" class="U ...
- Node.js躬行记(15)——活动规则引擎
在日常的业务开发中,会包含许多的业务规则,一般就是用if-else硬编码的方式实现,这样就会增加逻辑的维护成本,若无注释,可能都无法理解规则意图. 因为一旦规则有所改变,那么就需要修改代码再发布代码, ...
- opencv笔记---contours
一 Contour Finding Contours使用 STL-style vector<> 表示,如 vector<cv::Point>, vector<cv::Po ...
- 『无为则无心』Python面向对象 — 46、类和对象
目录 1.理解类和对象 2.类 3.对象 4.Python中的对象 5.类和对象的定义 (1)定义类 (2)创建对象 (3)练习 6.拓展:isinstance() 函数 1.理解类和对象 (1)类和 ...
- SpringBoot整合Redis案例缓存首页数据、缓解数据库压力
一.硬编码方式 1.场景 由于首页数据变化不是很频繁,而且首页访问量相对较大,所以我们有必要把首页数据缓存到redis中,减少数据库压力和提高访问速度. 2.RedisTemplate Jedis是R ...
- 设置maven创建工程的jdk编译版本
方式一:在maven的主配置文件中指定创建工程时使用jdk1.8版本 <profile> <id>jdk-1.8</id> <activation> & ...
- Go内存逃逸分析
Go的内存逃逸及逃逸分析 Go的内存逃逸 分析内存逃逸之前要搞清楚一件事 我们编写的程序中的函数和局部变量是存放在栈上的(补充一点堆上存储的数据的指针 是存放在栈上的 因为指针的大小是可以提前预知的 ...