Kafka入门教程(一)
转自:https://blog.csdn.net/yuan_xw/article/details/51210954
1 Kafka入门教程
1.1 消息队列(Message Queue)
Message Queue消息传送系统提供传送服务。消息传送依赖于大量支持组件,这些组件负责处理连接服务、消息的路由和传送、持久性、安全性以及日志记录。消息服务器可以使用一个或多个代理实例。
JMS(Java
Messaging Service)是Java平台上有关面向消息中间件(MOM)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口简化企业应用的开发,翻译为Java消息服务。
1.2 MQ消息模型

KafkaMQ消息模型图1-1
1.3 MQ消息队列分类
消息队列分类:点对点和发布/订阅两种:
1、点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
1.4 MQ消息队列对比
1、RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Loadbalance)或者数据持久化都有很好的支持。
2、ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
3、ActiveMQ:Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列。
4、Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受。
1.5 Kafka简介
Kafka是分布式发布-订阅消息系统,它最初由
LinkedIn 公司开发,使用 Scala语言编写,之后成为
Apache 项目的一部分。在Kafka集群中,没有“中心主节点”的概念,集群中所有的服务器都是对等的,因此,可以在不做任何配置的更改的情况下实现服务器的的添加与删除,同样的消息的生产者和消费者也能够做到随意重启和机器的上下线。

Kafka消息系统生产者和消费者部署关系图1-2

Kafka消息系统架构图1-3
1.6 Kafka术语介绍
1、消息生产者:即:Producer,是消息的产生的源头,负责生成消息并发送到Kafka
服务器上。
2、消息消费者:即:Consumer,是消息的使用方,负责消费Kafka服务器上的消息。
3、主题:即:Topic,由用户定义并配置在Kafka服务器,用于建立生产者和消息者之间的订阅关系:生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
4、消息分区:即:Partition,一个Topic下面会分为很多分区,例如:“kafka-test”这个Topic下可以分为6个分区,分别由两台服务器提供,那么通常可以配置为让每台服务器提供3个分区,假如服务器ID分别为0、1,则所有的分区为0-0、0-1、0-2和1-0、1-1、1-2。Topic物理上的分组,一个
topic可以分为多个 partition,每个
partition 是一个有序的队列。partition中的每条消息都会被分配一个有序的
id(offset)。
5、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为
broker。
6、消费者分组:Group,用于归组同类消费者,在Kafka中,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
7、Offset:消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset。
1.7 Kafka中Broker
1、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为
broker。
2、Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。
3、为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
4、Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。Message消息是有多份的。
5、Broker不保存订阅者的状态,由订阅者自己保存。
6、无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
7、消息订阅者可以rewind
back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
1.8 Kafka的Message组成
1、Message消息:是通信的基本单位,每个
producer 可以向一个 topic(主题)发布一些消息。
2、Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
3、partition中的每条Message包含了以下三个属性:
offset 即:消息唯一标识:对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容。
1.9 Kafka的Partitions分区
1、Kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存。
2、可以将一个topic切分多任意多个partitions,来消息保存/消费的效率。
3、越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
1.10 Kafka的Consumers
1、消息和数据消费者,订阅
topics并处理其发布的消息的过程叫做 consumers。
2、在
kafka中,我们可以认为一个group是一个“订阅者”,一个Topic中的每个partions,只会被一个“订阅者”中的一个consumer消费,不过一个
consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时)。注意:kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
3、一个partition中的消息只会被group中的一个consumer消息。每个group中consumer消息消费互相独立。
1.11 Kafka的持久化
1、一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append
log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),partition是以文件的形式存储在文件系统中。
2、Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。

Kafka消息分区Partition图1-4
Partition:
Topic物理上的分组,一个 topic可以分为多个
partition,每个 partition
是一个有序的队列。partition中的每条消息都会被分配一个有序的
id(offset)。
3、为数据文件建索引:稀疏存储,每隔一定字节的数据建立一条索引。下图为一个partition的索引示意图:

Kafka消息分区Partition索引图1-5
1.12 Kafka的分布式实现:
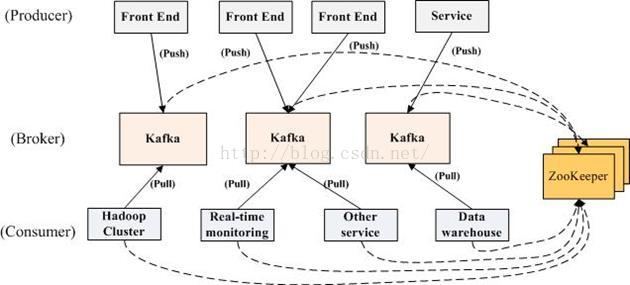
Kafka分布式关系图1-6

Kafka生产环境关系图1-7
1.13 Kafka的通讯协议:
1、Kafka的Producer、Broker和Consumer之间采用的是一套自行设计基于TCP层的协议,根据业务需求定制,而非实现一套类似ProtocolBuffer的通用协议。
2、基本数据类型:(Kafka是基于Scala语言实现的,类型也是Scala中的数据类型)
定长数据类型:int8,int16,int32和int64,对应到Java中就是byte,
short, int和long。
变长数据类型:bytes和string。变长的数据类型由两部分组成,分别是一个有符号整数N(表示内容的长度)和N个字节的内容。其中,N为-1表示内容为null。bytes的长度由int32表示,string的长度由int16表示。
数组:数组由两部分组成,分别是一个由int32类型的数字表示的数组长度N和N个元素。
3、Kafka通讯的基本单位是Request/Response。
4、基本结构:
RequestOrResponse => MessageSize(RequestMessage | ResponseMessage)
|
名称 |
类型 |
描术 |
|
MessageSize |
int32 |
表示RequestMessage或者ResponseMessage的长度 |
|
RequestMessage ResponseMessage |
— |
5、通讯过程:
客户端打开与服务器端的Socket
往Socket写入一个int32的数字(数字表示这次发送的Request有多少字节)
服务器端先读出一个int32的整数从而获取这次Request的大小
然后读取对应字节数的数据从而得到Request的具体内容
服务器端处理了请求后,也用同样的方式来发送响应。
6、RequestMessage结构:
RequestMessage => ApiKey ApiVersionCorrelationId ClientId Request
|
名称 |
类型 |
描术 |
|
ApiKey |
int16 |
表示这次请求的API编号 |
|
ApiVersion |
int16 |
表示请求的API的版本,有了版本后就可以做到后向兼容 |
|
CorrelationId |
int32 |
由客户端指定的一个数字唯一标示这次请求的id,服务器端在处理完请求后也会把同样的CorrelationId写到Response中,这样客户端就能把某个请求和响应对应起来了。 |
|
ClientId |
string |
客户端指定的用来描述客户端的字符串,会被用来记录日志和监控,它唯一标示一个客户端。 |
|
Request |
— |
Request的具体内容。 |
7、ResponseMessage结构:
ResponseMessage => CorrelationId Response
|
名称 |
类型 |
描术 |
|
CorrelationId |
int32 |
对应Request的CorrelationId。 |
|
Response |
— |
对应Request的Response,不同的Request的Response的字段是不一样的。 |
Kafka采用是经典的Reactor(同步IO)模式,也就是1个Acceptor响应客户端的连接请求,N个Processor来读取数据,这种模式可以构建出高性能的服务器。
8、Message结构:
Message:Producer生产的消息,键-值对
Message => Crc MagicByte Attributes KeyValue
|
名称 |
类型 |
描术 |
|
CRC |
int32 |
表示这条消息(不包括CRC字段本身)的校验码。 |
|
MagicByte |
int8 |
表示消息格式的版本,用来做后向兼容,目前值为0。 |
|
Attributes |
int8 |
表示这条消息的元数据,目前最低两位用来表示压缩格式。 |
|
Key |
bytes |
表示这条消息的Key,可以为null。 |
|
Value |
bytes |
表示这条消息的Value。Kafka支持消息嵌套,也就是把一条消息作为Value放到另外一条消息里面。 |
9、MessageSet结构:
MessageSet:用来组合多条Message,它在每条Message的基础上加上了Offset和MessageSize
MessageSet => [Offset MessageSize Message]
|
名称 |
类型 |
描术 |
|
Offset |
int64 |
它用来作为log中的序列号,Producer在生产消息的时候还不知道具体的值是什么,可以随便填个数字进去。 |
|
MessageSize |
int32 |
表示这条Message的大小。 |
|
Message |
- |
表示这条Message的具体内容,其格式见上一小节。 |
10、 Request/Respone和Message/MessageSet的关系:
Request/Response是通讯层的结构,和网络的7层模型对比的话,它类似于TCP层。
Message/MessageSet定义的是业务层的结构,类似于网络7层模型中的HTTP层。Message/MessageSet只是Request/Response的payload中的一种数据结构。
备注:Kafka的通讯协议中不含Schema,格式也比较简单,这样设计的好处是协议自身的Overhead小,再加上把多条Message放在一起做压缩,提高压缩比率,从而在网络上传输的数据量会少一些。
1.14 数据传输的事务定义:
1、at most once:最多一次,这个和JMS中”非持久化”消息类似.发送一次,无论成败,将不会重发。
at most once:消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后”未处理”的消息将不能被fetch到,这就是“atmost
once”。
2、at least once:消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。
at least once:消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是“atleast
once”,原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
3、exactly once:消息只会发送一次。
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的。
注:通常情况下“at-least-once”是我们首选。(相比at
most once而言,重复接收数据总比丢失数据要好)。
1.15 学习Kafka推荐书籍:
1. 《Apache
Kafka》
2. 《从Paxos到Zookeeper分布式一致性原理与实践》
–以上为《Kafka教程(一)Kafka入门教程》,如有不当之处请指出,我后续逐步完善更正,大家共同提高。谢谢大家对我的关注。
——厚积薄发(yuanxw)
Kafka入门教程(一)的更多相关文章
- kafka入门教程链接
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12882 经典入门教程 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创 ...
- Kafka入门教程(二)
转自:https://blog.csdn.net/yuan_xw/article/details/79188061 Kafka集群环境安装 相关下载 JDK要求1.8版本以上. JDK安装教程:htt ...
- kafka入门教程
1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有哪两个条件 ...
- 老王带你走过 Kafka 入门教程
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发. Linkedin于2010年贡献 ...
- Kafka入门 --安装和简单实用
一.安装Zookeeper 参考: Zookeeper的下载.安装和启动 Zookeeper 集群搭建--单机伪分布式集群 二.下载Kafka 进入http://kafka.apache.org/do ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- 《OD大数据实战》Kafka入门实例
官网: 参考文档: Kafka入门经典教程 Kafka工作原理详解 一.安装zookeeper 1. 下载zookeeper-3.4.5-cdh5.3.6.tar.gz 下载地址为: http://a ...
- 【原】Storm 入门教程目录
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Storm调度器 Storm配置 Guaranteeing Message Processing(消息处理 ...
- RabbitMQ入门教程(十七):消息队列的应用场景和常见的消息队列之间的比较
原文:RabbitMQ入门教程(十七):消息队列的应用场景和常见的消息队列之间的比较 分享一个朋友的人工智能教程.比较通俗易懂,风趣幽默,感兴趣的朋友可以去看看. 这是网上的一篇教程写的很好,不知原作 ...
随机推荐
- JS控制文本框禁止输入特殊字符
JS 控制不能输入特殊字符<input type="text" class="domain" onkeyup="this.value=this. ...
- C++类的静态成员变量与静态成员函数
1.类的静态成员变量 C++类的静态成员变量主要有以下特性: 1.静态成员变量需要类内定义,类外初始化 2.静态成员变量不依赖于类,静态成员变量属于全局区,不属于类的空间. 3.静态成员变量通过类名访 ...
- 服务集与AP的配合
一.实验目的 1)掌握添加无线网络配置 2)掌握配置信道和协议使用并配置在一个天线上同时运行两个服务集,即两个无线网络 二.实验仪器设备及软件 仪器设备:一台AC,两台AP,一台AR,一台LSW 软件 ...
- laravel groupby 报错
报错信息 laravel which is not functionally dependent on columns in GROUP BY clause; this is incompatible ...
- ansible模块及语法
常用模块详解 模块说明及示例: 1.ping模块ping模块 主要用于判断远程客户端是否在线,用于ping本身服务器,返回值是changed.ping示例 ansible clu -m ping 2. ...
- C++ 默认拷贝构造函数 深度拷贝和浅拷贝
C++类默认拷贝构造函数的弊端 C++类的中有两个特殊的构造函数,(1)无参构造函数,(2)拷贝构造函数.它们的特殊之处在于: (1) 当类中没有定义任何构造函数时,编译器会默认提供一个无参构造函数且 ...
- 【Jenkins】jenkins构建python项目提示:'python' 不是内部或外部命令,也不是可运行的程序或批处理文件
一.问题:jenkins构建python项目提示:'python' 不是内部或外部命令,也不是可运行的程序或批处理文件 二.原因:要在jenkins配置本地环境变量 三.解决方案:添加python.e ...
- 集合之Map接口
Map接口概述 Map与Collection并列存在.用于存储具有映射关系的数据 : key-value Map 中的 key 和 value 都可以是任何引用类型的数据 Map 中的 key 用Se ...
- 羽夏看Win系统内核——系统调用篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- VIM处理工具与正则表达式
*本文中/data目录为训练目录 1.在vim中设置TAB缩进为四个字符 打开vim 输入:set tabstop=4 2.复制/etc/rc.d/init.d/functions文件至/tmp/,替 ...