[DB] 大数据概述
什么是大数据
- 电商推荐系统
- 大量订单如何存储(十年)
- 大量的订单如何计算(不关心算法)
- 天气预报
- 大量的天气数据如何存储
- 大量天气数据如何计算
- 核心问题
- 数据的存储:分布式文件系统(HDFS)
- 数据的计算:分布式计算(MapReduce、Spark RDD)
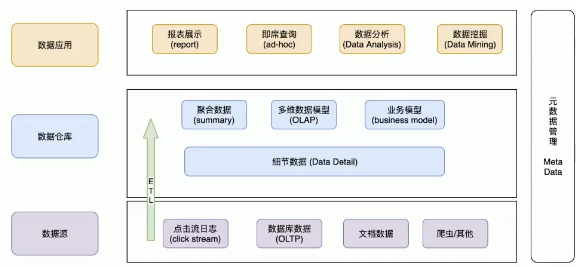
数据仓库
- 传统方式:搭建数据仓库(Data Warehouse)解决大数据问题
- 数据仓库就是一个数据库(Oracle、MySQL、MS)
- Oracle DBCA
- 一般只做查询(select)
- 大数据也是一般只做查询(分析,不修改数据)
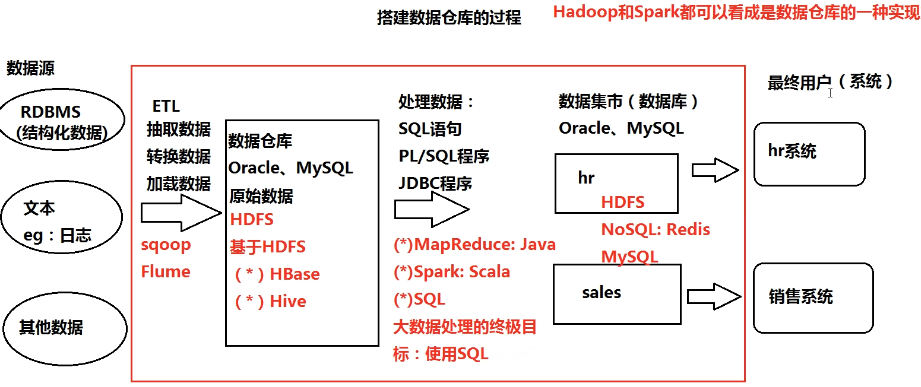
- Hadoop和Spark都可看做数据仓库的一种实现方式
- Oracle、MySQL是单机版数据库,无法实现分布式集群
- 搭建过程
- 数据源
- RDBMS(结构化数据)
- 文本、日志等(非结构化数据)
- 其他数据
- 数据清洗:抽取、转换、加载数据(ETL)
- 原始数据保存到数据库(Oracle、MySQL)
- 处理数据(SQL、JDBC)
- 处理后的数据保存到数据集市(Oracle、MySQL)
- 提供给最终用户(系统)
- 数据源
OLTP和OLAP
- OLTP
- Online Transaction Processing 联机事务处理
- insert、update、delete
- 传统关系型数据库解决的问题
- OLAP
- Online Analytic Processing 联机分析处理,一般只做查询select(分析,不支持事务)
- 数据仓库是一种OLAP
- Hadoop、Spark可看做一种数据仓库解决方案
Google三篇论文
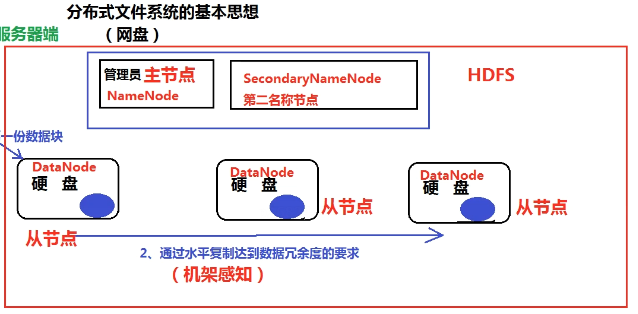
- GFS(Google File System)
- 分布式文件系统
- 硬盘不够大->加硬盘
- 硬盘不够安全->冗余
- Oracle费用:50万/年/CPU
- 大量使用pc服务器(去掉机箱、外设、硬盘)
- 数据存在内存,速度快,用冗余保证安全
- HDFS:通过数据块传输(128M),水平复制,默认冗余度3
- 机架感知:兼顾安全与效率(HDFS封装)
- 倒排索引(Reverted Index)
- 数据保存在了哪个硬盘上?
- 记录数据保存的位置信息(元信息)
- 索引:目录(索引表,保存行地址,类似书后名词索引按字母顺序排序),提高查询效率(没有索引时需要遍历)
- 单词保存在哪句话中?分词,建立目录(单词表),记录单词位置信息
- 可使用MapReduce建立倒排索引



- MapReduce
- 分布计算模型
- 问题来源:PageRank(网页排名)
- 搜索结果中,Rank越高的Page排名越靠前
- 被指向越多的网页Rank越高
- 用矩阵记录Rank
- 用MapReduce计算大矩阵
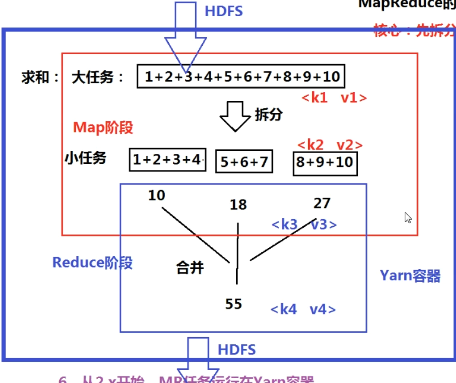
- 思想:先拆分、再合并
- 编程模型
- MR任务:job=map+reduce
- Map的输出是Reduce的输入
- 一个MR任务,一共存在4对输入和输出
- 所有输入输出都是<key value>形式
- Map阶段:<k1 v1>输入,<k2 v2>输出
- Reduce阶段:<k3 v3>输入,<k4 v4>输出
- k2=k3,v2和v3数据类型一致,v3是一个集合,该集合中的每个值就是v2
- 如下图v3=(10,18,27)
- 所有<key value>数据类型必须是Hadoop自己的数据类型
- IntWritable LongWritable Text NullWritable
- Hadoop类型实现了Hadoop的序列化机制(Writable接口)
- 从2.x开始,MR运行在Yarn容器中(类似JSP部署在Tomcat)
- Yarn=ResourceManager(主节点)+NodeManager(从节点)
- MR任务处理的数据是HDFS的数据
- mapreduce实例:/share/hadoop/mapreduce/example
- web console:localhost:8088/cluster
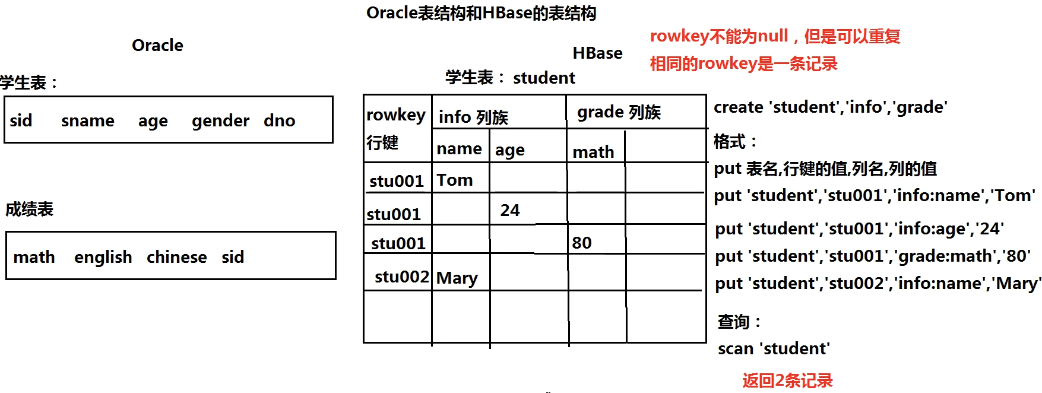
- BigTable(大表)
- 关系型数据库
- 基于关系模型(用二维表保存数据)
- 行式数据库
- MySQL、Oracle
- insert update delete 性能高
- 常见NoSQL数据库
- Redis:内存数据库
- HBase:面向列
- MongoDB:面向文档(BSON文档:JSON的二进制)
- select 性能高
- 核心思想
- 把所有数据存入一张表
- 数据冗余
- 提高性能(空间换时间)
- 把同样的数据存入Oracle和大表
- HBase = ZooKeeper + HMaster(主节点) + RegionServer(从节点)
- 关系型数据库
参考
大数据学习路线
https://blog.csdn.net/juan11115/article/details/102834913
https://www.zhihu.com/question/351790709/answer/865237610
http://www.imooc.com/article/270280
[DB] 大数据概述的更多相关文章
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 大数据相关概念和hdfs
大数据 概述 大数据是新处理模式才能具备更多的决策力,洞察力,流程优化能力,来适应海量高增长率,多样化的数据资产. 大数据面临的问题 怎么存储海量数据(kb,mb,gb,tb,pb,eb,zb) 怎么 ...
- 大数据运维尖刀班 | 集群_监控_CDH_Docker_K8S_两项目_腾讯云服务器
说明:大数据时代,传统运维向大数据运维升级换代很常见,也是个不错的机会.如果想系统学习大数据运维,个人比较推荐通信巨头运维大咖的分享课:https://url.cn/5HIqOOr,主要是实战强.含金 ...
- 有必要了解的大数据知识(一) Hadoop
前言 之前工作中,有接触到大数据的需求,虽然当时我们体系有专门的大数据部门,但是由于当时我们中台重构,整个体系的开发量巨大,共用一个大数据部门,人手已经忙不过来,没法办,为了赶时间,我自己负责的系统的 ...
- Laxcus大数据管理系统2.0(2)- 第一章 基础概述 1.1 基于现状的一些思考
第一章 基础概述 1.1 基于现状的一些思考 在过去十几年里,随着互联网产业的普及和高速发展,各种格式的互联网数据也呈现爆炸性增长之势.与此同时,在数据应用的另一个重要领域:商业和科学计算,在各种新兴 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据及Hadoop的概述
一.大数据存储和计算的各种框架即工具 1.存储:HDFS:分布式文件系统 Hbase:分布式数据库系统 Kafka:分布式消息缓存系统 2.计算:Mapreduce:离线计算框架 stor ...
随机推荐
- ES9的新特性:正则表达式RegExp
简介 正则表达式是我们做数据匹配的时候常用的一种工具,虽然正则表达式的语法并不复杂,但是如果多种语法组合起来会给人一种无从下手的感觉. 于是正则表达式成了程序员的噩梦.今天我们来看一下如何在ES9中玩 ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- 从西天取经的九九八十一难来看Java设计模式:模板方法模式
目录 示例 模板方法模式 定义 意图 主要解决问题 适用场景 优缺点 西天取经的九九八十一难 示例 当我们设计一个类时,我们能明确它对外提供的某个方法的内部执行步骤, 但一些步骤,不同的子类有不同的行 ...
- Day06_30_抽象类(Abstract)
抽象类 Abstract 什么是抽象类? 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就 ...
- SpringCloud-微服务架构编码构建
SpringCloud Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线).分布式系统的协调导致了样板模式, ...
- 为什么传统软件厂商都想转型做Saas?
欢迎关注微信公众号:sap_gui (ERP咨询顾问之家) 早些年,我工作笔记用的最多的是微软的OneNote,这东西好用不说,不仅能够存在云端,也能存放在本地.可惜到了Office2019之后,On ...
- 01- Sublime的工具安装以及使用
一 sublime安装与使用 sublime介绍: sublime是一个代码编辑器,可以编写HTML,PHP,js,css等文件. Sublime有哪些优点: 1.跨平台 2.扩展性强 3.提交小,运 ...
- 05- web网站链接测试与XENU工具使用
什么是链接 链接也叫超链接,是指从某一个网页元素指向另一个目标的连接关系,这个目标可以是另一个网站的网页,可以是本网站的一个网页,可以使同一个网页的不同位置,还可以是一个图片,一个视频,一个文件甚至是 ...
- 硬件篇-03-SLAM移动底盘电气设计
最近因为在忙毕设,专栏已经1个多月没更,对于托更我很抱歉.不过这几周真的没什么时间,Rick&Morty的最新集我到现在都还没看哈哈. 现在毕设已经搞得差不多了,水专栏文章的快乐生 ...
- 限制pyqt5应用程序 只允许打开一次
起因 pyqt5程序创建桌面快捷方式后,多次单击图标 会打开多个UI界面,这种情况肯定是不允许的! 解决 if __name__ == '__main__': try: app = QtWidgets ...