[DB] 大数据概述
什么是大数据
- 电商推荐系统
- 大量订单如何存储(十年)
- 大量的订单如何计算(不关心算法)
- 天气预报
- 大量的天气数据如何存储
- 大量天气数据如何计算
- 核心问题
- 数据的存储:分布式文件系统(HDFS)
- 数据的计算:分布式计算(MapReduce、Spark RDD)
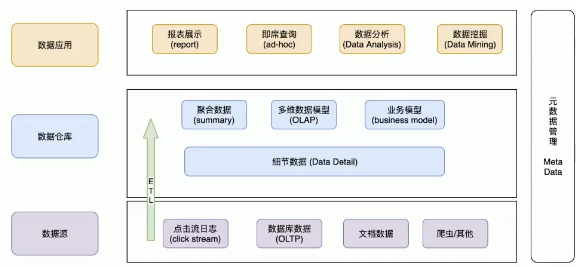
数据仓库
- 传统方式:搭建数据仓库(Data Warehouse)解决大数据问题
- 数据仓库就是一个数据库(Oracle、MySQL、MS)
- Oracle DBCA
- 一般只做查询(select)
- 大数据也是一般只做查询(分析,不修改数据)
- Hadoop和Spark都可看做数据仓库的一种实现方式
- Oracle、MySQL是单机版数据库,无法实现分布式集群
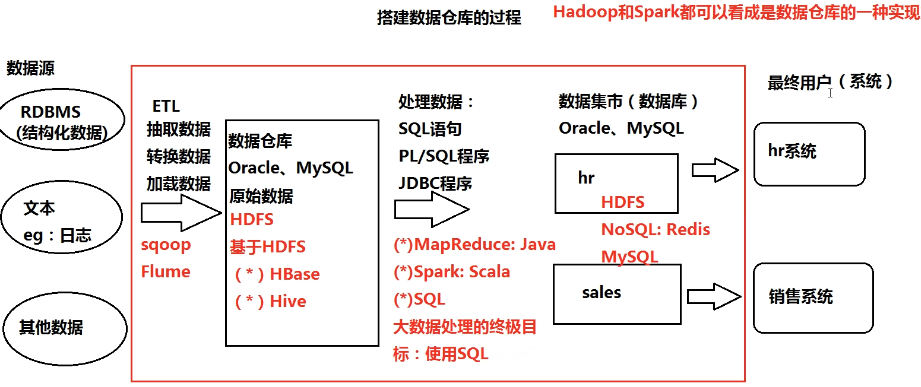
- 搭建过程
- 数据源
- RDBMS(结构化数据)
- 文本、日志等(非结构化数据)
- 其他数据
- 数据清洗:抽取、转换、加载数据(ETL)
- 原始数据保存到数据库(Oracle、MySQL)
- 处理数据(SQL、JDBC)
- 处理后的数据保存到数据集市(Oracle、MySQL)
- 提供给最终用户(系统)
- 数据源
OLTP和OLAP
- OLTP
- Online Transaction Processing 联机事务处理
- insert、update、delete
- 传统关系型数据库解决的问题
- OLAP
- Online Analytic Processing 联机分析处理,一般只做查询select(分析,不支持事务)
- 数据仓库是一种OLAP
- Hadoop、Spark可看做一种数据仓库解决方案
Google三篇论文
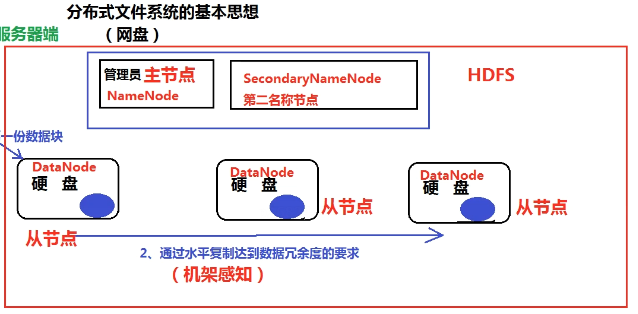
- GFS(Google File System)
- 分布式文件系统
- 硬盘不够大->加硬盘
- 硬盘不够安全->冗余
- Oracle费用:50万/年/CPU
- 大量使用pc服务器(去掉机箱、外设、硬盘)
- 数据存在内存,速度快,用冗余保证安全
- HDFS:通过数据块传输(128M),水平复制,默认冗余度3
- 机架感知:兼顾安全与效率(HDFS封装)
- 倒排索引(Reverted Index)
- 数据保存在了哪个硬盘上?
- 记录数据保存的位置信息(元信息)
- 索引:目录(索引表,保存行地址,类似书后名词索引按字母顺序排序),提高查询效率(没有索引时需要遍历)
- 单词保存在哪句话中?分词,建立目录(单词表),记录单词位置信息
- 可使用MapReduce建立倒排索引



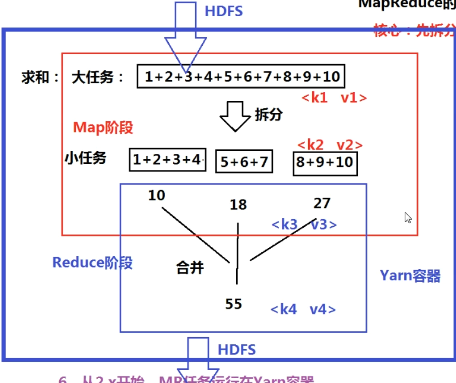
- MapReduce
- 分布计算模型
- 问题来源:PageRank(网页排名)
- 搜索结果中,Rank越高的Page排名越靠前
- 被指向越多的网页Rank越高
- 用矩阵记录Rank
- 用MapReduce计算大矩阵
- 思想:先拆分、再合并
- 编程模型
- MR任务:job=map+reduce
- Map的输出是Reduce的输入
- 一个MR任务,一共存在4对输入和输出
- 所有输入输出都是<key value>形式
- Map阶段:<k1 v1>输入,<k2 v2>输出
- Reduce阶段:<k3 v3>输入,<k4 v4>输出
- k2=k3,v2和v3数据类型一致,v3是一个集合,该集合中的每个值就是v2
- 如下图v3=(10,18,27)
- 所有<key value>数据类型必须是Hadoop自己的数据类型
- IntWritable LongWritable Text NullWritable
- Hadoop类型实现了Hadoop的序列化机制(Writable接口)
- 从2.x开始,MR运行在Yarn容器中(类似JSP部署在Tomcat)
- Yarn=ResourceManager(主节点)+NodeManager(从节点)
- MR任务处理的数据是HDFS的数据
- mapreduce实例:/share/hadoop/mapreduce/example
- web console:localhost:8088/cluster
- BigTable(大表)
- 关系型数据库
- 基于关系模型(用二维表保存数据)
- 行式数据库
- MySQL、Oracle
- insert update delete 性能高
- 常见NoSQL数据库
- Redis:内存数据库
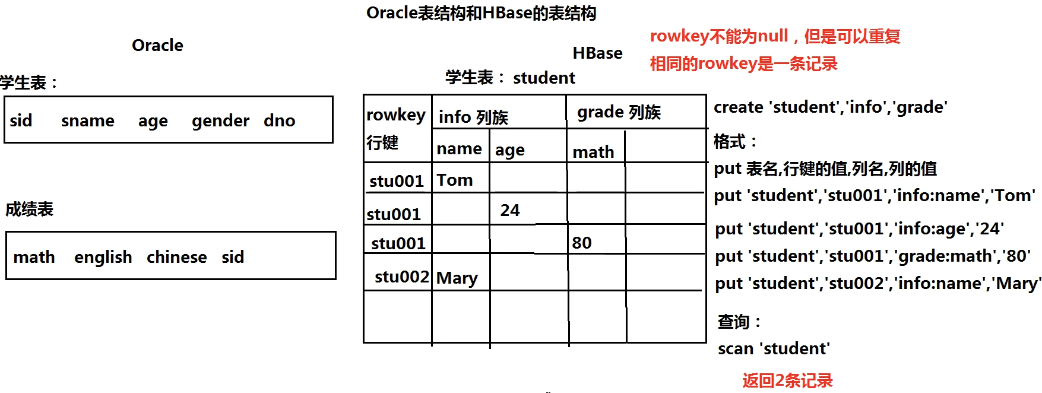
- HBase:面向列
- MongoDB:面向文档(BSON文档:JSON的二进制)
- select 性能高
- 核心思想
- 把所有数据存入一张表
- 数据冗余
- 提高性能(空间换时间)
- 把同样的数据存入Oracle和大表
- HBase = ZooKeeper + HMaster(主节点) + RegionServer(从节点)
- 关系型数据库
参考
大数据学习路线
https://blog.csdn.net/juan11115/article/details/102834913
https://www.zhihu.com/question/351790709/answer/865237610
http://www.imooc.com/article/270280
[DB] 大数据概述的更多相关文章
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- 大数据相关概念和hdfs
大数据 概述 大数据是新处理模式才能具备更多的决策力,洞察力,流程优化能力,来适应海量高增长率,多样化的数据资产. 大数据面临的问题 怎么存储海量数据(kb,mb,gb,tb,pb,eb,zb) 怎么 ...
- 大数据运维尖刀班 | 集群_监控_CDH_Docker_K8S_两项目_腾讯云服务器
说明:大数据时代,传统运维向大数据运维升级换代很常见,也是个不错的机会.如果想系统学习大数据运维,个人比较推荐通信巨头运维大咖的分享课:https://url.cn/5HIqOOr,主要是实战强.含金 ...
- 有必要了解的大数据知识(一) Hadoop
前言 之前工作中,有接触到大数据的需求,虽然当时我们体系有专门的大数据部门,但是由于当时我们中台重构,整个体系的开发量巨大,共用一个大数据部门,人手已经忙不过来,没法办,为了赶时间,我自己负责的系统的 ...
- Laxcus大数据管理系统2.0(2)- 第一章 基础概述 1.1 基于现状的一些思考
第一章 基础概述 1.1 基于现状的一些思考 在过去十几年里,随着互联网产业的普及和高速发展,各种格式的互联网数据也呈现爆炸性增长之势.与此同时,在数据应用的另一个重要领域:商业和科学计算,在各种新兴 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据及Hadoop的概述
一.大数据存储和计算的各种框架即工具 1.存储:HDFS:分布式文件系统 Hbase:分布式数据库系统 Kafka:分布式消息缓存系统 2.计算:Mapreduce:离线计算框架 stor ...
随机推荐
- java面试-CountDownLatch、CyclicBarrier、Semaphore谈谈你的理解
一.CountDownLatch 主要用来解决一个线程等待多个线程的场景,计数器不能循环利用 public class CountDownLatchDemo { public static void ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(四)——一步一步教你如何撸Dapr之订阅发布
之前的章节我们介绍了如何通过dapr发起一个服务调用,相信看过前几章的小伙伴已经对dapr有一个基本的了解了,今天我们来聊一聊dapr的另外一个功能--订阅发布 目录:一.通过Dapr实现一个简单的基 ...
- 迷宫问题(BFS)
给定一个n* m大小的迷宫,其中* 代表不可通过的墙壁,而"."代表平地,S表示起点,T代表终点.移动过程中,如果当前位置是(x, y)(下标从0开始),且每次只能前往上下左右.( ...
- Spring Boot 2.3 新特配置文件属性跟踪
背景 当我们使用 spring boot 在多环境打包,配置属性在不同环境的值不同,如下: spring: profiles: active: @project.profile@ #根据maven 动 ...
- JVM经典垃圾收集器
这个关系不是一成不变的,由于维护和兼容性测试的成本,在JDK 8时将Serial+CMS. ParNew+Serial Old这两个组合声明为废弃(JEP 173),并在JDK 9中完全取消了这些 ...
- (九)VMware Harbor 项目管理-上传/下载镜像
VMware Harbor项目管理 Harbor中的项目包含应用程序的所有存储库. Harbor有两类项目: 公共:所有用户都拥有公共项目的读取权限,您可以方便地以这种方式与其他人共享一些存储库. 私 ...
- 什么?女神发了朋友圈,快来围观之Java设计模式:观察者模式
目录 观察者模式 示例 定义 设计原则 意图 主要解决问题 何时使用 优缺点 女神和追求者的故事 Java中的实现 观察者模式 示例 微信公众号,关注就可以收到推送的消息,取消关注就不会收到 定义 定 ...
- Digit Counting UVA - 1225
Trung is bored with his mathematics homeworks. He takes a piece of chalk and starts writing a sequ ...
- 研发团队管理:IT研发中项目和产品原来区别那么大,项目级的项目是项目,产品级的项目是产品!!!
前言 从事IT行业多年,一路从小杂兵成长为大团队Leader,对于研发整个体系比较清楚,其实大多人都经历过但是都忽略了的研发成本管控的一个关键的点就是研发过程中项目级和产品级的区别. 市场基本 ...
- 05.ElementUI源码学习:项目发布配置(github pages&npm package)
0x00.前言 书接上文.项目第一个组件已经封装好,说明文档也已编写好.下面需要将说明文档发布到外网上,以此来展示和推广项目,使用 Github Pages功能实现.同时将组件发布之 npm 上,方便 ...