Unsupervised Feature Learning via Non-Parametric Instance Discrimination
概
这篇文章也是最近很虎的contrastive learning的经典之作, 其用于下游任务的处理虽没现在的简单粗暴, 但效果依然很好.
主要内容
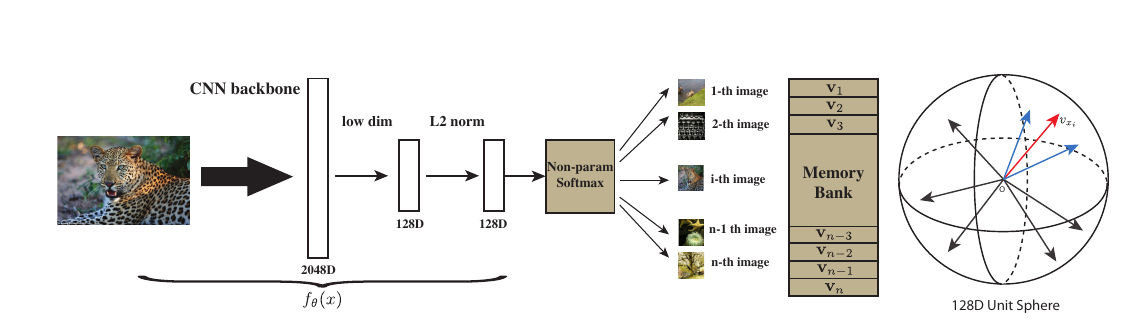
因为作者实际上是从一个无监督的角度去考虑的, 其出发点就是, 如果希望将分类器将每一个样本都区分开来, 是否能够获得比较好的特征呢? 输入\(x\)经过embedding function 得到\(f_{\theta}(x)\), 即特征, 那么现在的问题是:
- 目标是将所有样本作为一个单独的类别, 这就会导致类别个数很大, 甚至成百上千万, 如果这是还和普通的分类任务一样, 将
\]
则最后一个分类层的权重\(W \in \mathbb{R}^{k \times n}\), 这将是无法承受的存储量和计算量.
为了解决这个问题, 作者选择的首先构造一个memory bank, 将特征存储起来, 第\(i\)个样本对应的为\(v_i\), 而当前\(f_{\theta}(x_i)\)记作\(f_i\), 则
\]
这里\(\tau\)是temperature.
这样就避免了\(w\), 且符合直觉: 即衡量了\(f_{\theta}(x)\)与数据中的第\(i\)个样本的相关度. 但是, 虽然这一定程度上减少了存储量, 但是计算量并没有减少, 即我们需要估计分母\(Z_i\), 实际上, 这就是一个配平的问题, 这是负样本采样可以发挥作用的地方.
假设
\]
其中\(P_n(i)\)为一个均匀分布, 即每个特征被选中的概率为\(\frac{1}{n}\). 然后便是经典的损失
\]
个人感觉: \(P_d(i, v) = P(v) \cdot Q(i|v)\), 其中\(Q(i|v)\)仅当\(v\)为第\(i\)个样本点的特征是概率为\(1\)否则为\(0\). 而\(P_n(i, v) = P(v) \cdot \frac{1}{n}\). 同时, 估计
\]
感觉就像是一个抽样. 这个\(\frac{n}{m}\)最新的文章里出现过, 但是当时没感觉出其意义来, 原来源头是在这?
解决了计算了和存储问题, 还有一个训练不稳定的问题要解决.
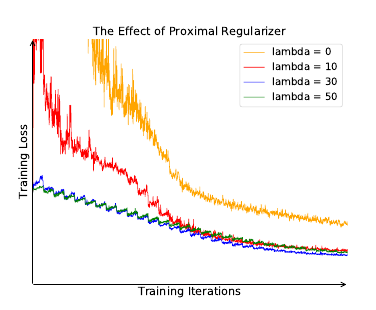
训练不稳定的诱因, 作者认为是每个样本作为一个类, 如此每个类在每个epoch里仅会被访问一次. 解决策略是用proximal 算子:
\]
有疑问的是, 我看的proximal算法里面, 应该是\(\log h(i, v^{(t)})\), 虽然二者可能相差不大.
Unsupervised Feature Learning via Non-Parametric Instance Discrimination的更多相关文章
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
- 泡泡一分钟:Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition
Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition Peng Yin, Lingyun Xu, Z ...
- 转:无监督特征学习——Unsupervised feature learning and deep learning
http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio clas ...
- [转] 无监督特征学习——Unsupervised feature learning and deep learning
from:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio ...
- UFLDL(Unsupervised Feature Learning and Deep Learning)
UFLDL(Unsupervised Feature Learning and Deep Learning)Tutorial 是由 Stanford 大学的 Andrew Ng 教授及其团队编写的一套 ...
- Unsupervised Feature Learning and Deep Learning(UFLDL) Exercise 总结
7.27 暑假开始后,稍有时间,“搞完”金融项目,便开始跑跑 Deep Learning的程序 Hinton 在Nature上文章的代码 跑了3天 也没跑完 后来Debug 把batch 从200改到 ...
- Joint Detection and Identification Feature Learning for Person Search
Joint Detection and Identification Feature Learning for Person Search 2018-06-02 本文的贡献主要体现在: 提出一种联合的 ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 图像分类之特征学习ECCV-2010 Tutorial: Feature Learning for Image Classification
ECCV-2010 Tutorial: Feature Learning for Image Classification Organizers Kai Yu (NEC Laboratories Am ...
随机推荐
- MapReduce02 序列化
目录 MapReduce 序列化 概述 自定义序列化 常用数据序列化类型 int与IntWritable转化 Text与String 序列化读写方法 自定义bean对象实现序列化接口(Writable ...
- 系列好文 | Kubernetes 弃用 Docker,我们该何去何从?
作者 | 张攀(豫哲) 来源 | 尔达 Erda 公众号 导读:Erda 作为一站式云原生 PaaS 平台,现已面向广大开发者完成 70w+ 核心代码全部开源!**在 Erda 开源的同时,我们计划编 ...
- Hadoop、Hive【LZO压缩配置和使用】
目录 一.编译 二.相关配置 三.为LZO文件创建索引 四.Hive为LZO文件建立索引 1.hive创建的lzo压缩的分区表 2.给.lzo压缩文件建立索引index 3.读取Lzo文件的注意事项( ...
- oracle异常处理——ORA-01000:超出打开游标最大数
oracle异常处理--ORA-01000:超出打开游标最大数https://www.cnblogs.com/zhaosj/p/4309352.htmlhttps://blog.csdn.net/u0 ...
- mysql 5.7 压缩包安装教程
前言 : 避免之前装的MySQL影响 首先进入dos窗口执行 sc delete mysql 删除已有的mysql服务 (一) 下载MySQL5.7 版本压缩包 网址 https://de ...
- JavaIO——内存操作流、打印流
我们之前所做的都是对文件进行IO处理,实则我们也可以对内存进行IO处理.我们将发生在内存中的IO处理称为内存流. 内存操作流也可分为两类:字节内存流和字符内存流. (1)ByteArrayInputS ...
- Dubbo多版本控制
当系统进行升级时,一般都是采用"灰度发布(又称为金丝雀发布)"过程.即在低压力时段,让部分消费者先调用新的提供者实现类,其余的仍然调用老的实现类,在新的实现类运行没有问题的情况下, ...
- 【前端】关于DOM节点
参考这个: https://juejin.cn/post/6844903849614901261 DOM树的根节点是document对象 DOM节点类型:HTML元素节点(element nodes) ...
- [特征工程] GBDT
- 软件开发生命周期(SDLC)
一.简介 软件开发生命周期又叫做 SDLC(Software Development Life Cycle),它是集合了计划.开发.测试和部署过程的集合.如下图所示 : 二.五个阶段 1.分析阶段: ...