Python3.9安装PySpider步骤及问题解决
先写一些前言吧,自己感觉python已经有一定的基础了,但是在安装这个过程居然用了一下午,感觉有些收货,特地写下来与大家分享一下。
- PySpider是一个强大的网络爬虫系统,GitHub地址:https://github.com/binux/pyspider;官方文档地址:http://docs.pyspider.org/en/latest。
- PySpider,提供WEBUI系统,支持PhantomJS进行JS的渲染采集,内置pyquery作为选择器,可拓展程度不高。
- Scrapy,原生是代码和命令操作,对接Portia实现可视化,使用parse命令调试,对接Scrapy-Splash组件进行JS渲染采集,对接XPath/CSS选择器和正则匹配,可对接Middleware、Pipeline、Extension等组件拓展。
- PySpider,架构分为Scheduler调度器(发起任务调度),Fetcher抓取器(抓取网页内容),Processer处理器(解析网页内容)。
话不多说,上安装过程(PS,本机环境windows10,Python3.9.0):
1、首先需要安装PhantomJS,这个比较简单,就直接按照网上流程安装对应版本就行。
2、安装PyCurl,这个是安装PySpider的先决条件,直接pip安装会报错,可以下载.whl文件安装,网址https://www.lfd.uci.edu/~gohlke/pythonlibs/#pycurl,
3、安装PySpider,直接pip安装就行。
4、安装调试:
(1)、安装完Pyspider,命令行运行pyspider,会报错:SyntaxError: invalid syntax:
这个是因为python以及相关依赖版本过高。可以使用Pycharm (亦可直接用文档更改代码),点击File-Open打开python\lib\sit-packages\pyspider,将文件夹pyspider 加载进去,按Ctrl+Shift+F快捷键调出全局搜索,输入async,即可在“In Project”下找到所有含有关键字的.py 文件,逐一打开,按Ctrl+R调出替换栏,将async 替换为shark 即可。就是分别在run.py、tornado_fetcher.py、webui>app.py,ctrl+f查找async替换掉就可以了。(注意大写的Async不要替换)
(2)、再次运行发现报错:AttributeError: module 'fractions' has no attribute 'gcd',
这个函数在Python3.5之后就废弃了,官方建议使用math.gcd()。所以在libs/base_handler文件中上方加入 import math下面fractions.gcd()改为math.gcd(…)就可以了
(3)、再次运行发现报错:Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.
webui文件里面的webdav.py文件打开,修改第209行即可。把
'domaincontroller': NeedAuthController(app),
修改为:
'http_authenticator':{
'HTTPAuthenticator':NeedAuthController(app),
},
(4)、再次运行发现报错:cannot import name 'DispatcherMiddleware' from 'werkzeug.wsgi' (d:\python39\lib\site-packages\werkzeug\wsgi.py)
这个是werkzeug的版本太高问题,需要进行修改
python -m pip uninstall werkzeug # 卸载
python -m pip install werkzeug==0.16.1
#安装0.16.1版本
(5)、同样也需要更换wsgidav
版本
pip uninstall wsgidav
pip install wsgidav==2.4.1
(6)、再次运行pyspider,发现卡死在result_worker starting,运行pyspider all卡死在, fetcher starting…
百度,① 有说需要打开一个命令行端口运行pyspider,卡住后运行第二个并关掉第一个端口;② 有说需要关闭防火墙;③ 有说需要先安装redis
但是,我都尝试一遍还是卡在那里。
(7)最后选择重新安装一遍,
① 把之前安装的包卸载,具有有:wsgidav,werkzeug,pycurl,pyspider(已经安装的redis没有卸载,防火墙中python权限打开没关)
② 按照上述(1)~(5)步骤安装,过程中发现Flask与相关包冲突,并最Flask的版本进行了更新。具体描述如下:
a)发现在安装 werkzeug 时报错:
ERROR: pip's dependency resolver does not currently take
into account all the packages that are installed. This behaviour is the source
of the following dependency conflicts.
flask 2.0.1 requires Werkzeug>=2.0, but you have werkzeug
0.16.1 which is incompatible.
b)卸载flask,继续安装
wsgidav 时报错:
ERROR: pip's dependency resolver does not currently take
into account all the packages that are installed. This behaviour is the source
of the following dependency conflicts.
pyspider 0.3.10 requires Flask>=0.10, which is not
installed.
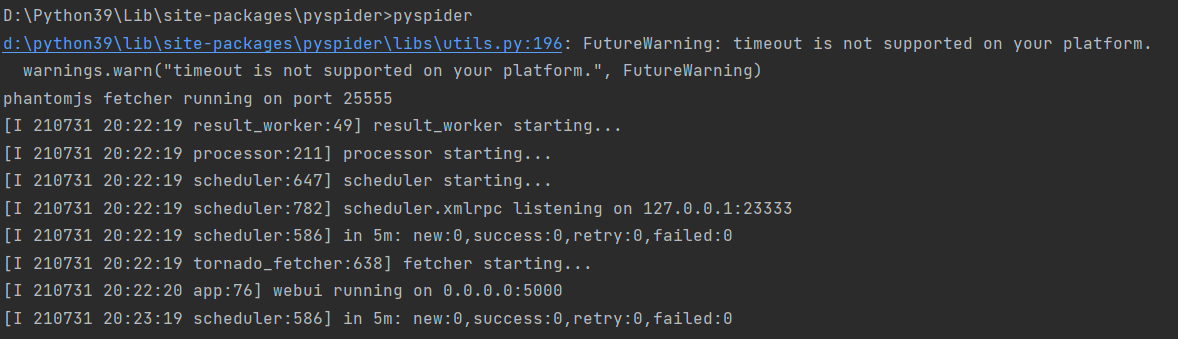
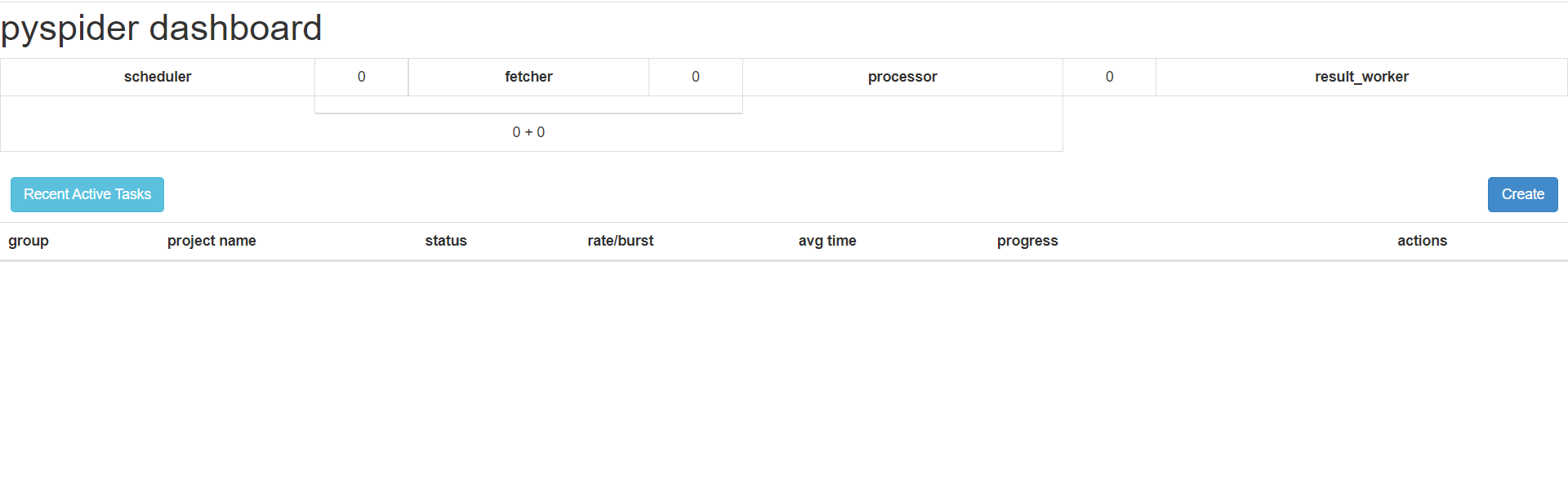
c)安装 flask==1.0.2 ,如果安装0.10版本,发现pyspider的网页UI部分内容渲染失败。1.0.2版本刚好合适
d)安装成功截图:
Python3.9安装PySpider步骤及问题解决的更多相关文章
- Python3.7安装pyspider
下面是Python3.7安装pyspider的方式,能安装成功但是后期有很多问题,所以不建议,请使用3.5版本的Python进行安装!!!由于要做爬虫工作,所以学习pyspider框架,下面介绍安装步 ...
- python3.6安装pyspider
win10下安装pyspider 1.pip 我在安装pip的时候默认安装了Pip. 如果没有的话:pip安装 2.PhantomJS PhantomJS 是一个基于 WebKit 的服务器端 Jav ...
- Python3环境安装PySpider爬虫框架过程
收录待用,修改转载已取得腾讯云授权 大家好,本篇文章为大家讲解腾讯云主机上PySpider爬虫框架的安装. 首先,在此附上项目的地址,以及官方文档 PySpider 官方文档 安装流程 pip 首先确 ...
- Linux环境下安装Redis步骤即问题解决
第一步:将安装包在window平台上解压后拷贝到Linux机器的/usr/soft目录下,并且为文件夹和文件赋予最高权限,chmod+x *: 第二步:进入到redis-3.2.6目录下,执行make ...
- Linux下安装load generator步骤及问题解决
Linux下安装load generator步骤及问题解决 上一篇 / 下一篇 2014-08-06 18:33:00 / 个人分类:loadrunner相关 查看( 146 ) / 评论( 0 ) ...
- centos7 安装 pyspider 出现的一系列问题及解决方案集合
先安装python3 和 pip3 wget https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tgz 安装zlib-devel包(后面安装pi ...
- 安装pyspider遇到的坑
pyspider是国人写的一款开源爬虫框架,个人觉得这个框架用起来很方便,至于如何方便可以继续看下去. 作者博客:http://blog.binux.me/ 安装pyspider安装pyspider: ...
- ubuntu系统下安装pyspider:搭建pyspider服务器新手教程
首先感谢“巧克力味腺嘌呤”的博客和Debian 8.1 安装配置 pyspider 爬虫,本人根据他们的教程在ubuntu系统中进行了实际操作,发现有一些不同,也出现了很多错误,因此做此教程,为新手服 ...
- python3 django 安装
参考https://www.cnblogs.com/yuyang26/p/7411269.html 前提条件:python3.x环境 windows 步骤1 pip install Django==2 ...
随机推荐
- 题解 P3232 [HNOI2013]游走
洛谷P3232[NOI2013]游走 题目描述 给定一个 n 个点 m 条边的无向连通图,顶点从 1 编号到 n,边从 1 编号到 m. 小 Z 在该图上进行随机游走,初始时小 Z 在 1 号顶点,每 ...
- 树莓派FRP内网穿透及自启动
内网穿透的步骤和文件存档 实验室在远方部署了电脑主机来采集数据和图片,每次去调试会很麻烦,因而使用FRP内网穿透使得我们可以在实验室访问主机. 主要功能 实现远程可访问和开机自启FRP程序服务 安装和 ...
- WPF Frame 的 DataContext 不能被 Page 继承
转载至https://blog.csdn.net/sinat_31608641/article/details/88914517 已测试解决方案可行,因为WPF相关资料稀少,防止日后404,特搬运到自 ...
- 13、windows下卸载oracle
13.1.停用oracle服务: 进入计算机管理,在服务中,找到oracle开头的所有服务,右击选择停止: 13.2.删除oracle: 在开始菜单中,找到oracle->Universal I ...
- POJ 2236 Wireless Network 第一次做并查集,第一次写博客
题意是判断两台电脑是否能通讯,两台修好的电脑距离在指定距离内可直接通讯,且两台修好的电脑能通过一台修好的电脑间接通讯.代码如下: #include <iostream> #include ...
- SQL Server数据库阻塞,死锁查询
sql 查询卡顿数据库 SELECT SPID=p.spid, DBName = convert(CHAR(20),d.name), ProgramName = program_name, Login ...
- SpringBoot:springboot项目jar包如何引入外置配置文件
springboot项目打成jar包,默认读取的classpath路径下的配置文件,config.properties是自定义配置文件. 如果要把config.properties配置 ...
- Leetcode No.122 Best Time to Buy and Sell Stock II Easy(c++实现)
1. 题目 1.1 英文题目 You are given an array prices where prices[i] is the price of a given stock on the it ...
- 二进制方式搭建Kubernetes集群
环境准备: 演练暂时用单节点一台master和一台node节点来进行部署搭建(kubernetes 1.19版本) 角色 IP 组件 master 10.129.246.114 kube-apiser ...
- 传统.NET 4.x应用容器化体验(1)
我们都知道.NET Core应用可以跑在Docker上,那.NET Framework 4.x应用呢?借助阿里云ECS主机(Windows Server 2019 with Container版本), ...