TF-IDF算法简析
TF-IDF算法可用来提取文档的关键词,关键词在文本聚类、文本分类、文献检索、自动文摘等方面有着重要应用。
算法原理
TF:Term Frequency,词频
IDF:Inverse Document Frequency,逆文档频率
词频(TF):某一个词在该文件中出现的频率
计算方法为:

逆文档频率(IDF):总文件数目除以包含该词的文件数目
计算方法为:
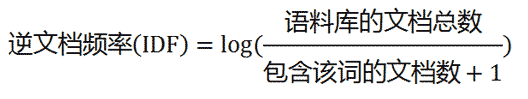
分母加1是为了防止该词不在语料库中而导致被除数为零
最后,TF-IDF的计算方式为:

TF-IDF 的主要思想为:
如果某个词在一篇文档中出现的频率高(即 TF 高),并且在语料库中其他文档中很少出现(即 IDF 高),则认为这个词具有很好的类别区分能力
算法过程:先计算出文档中每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词作为关键词进行输出
算法优点:
原理简单,能满足大多数实际需求
算法缺点:
- 单纯以 “词频” 衡量一个词的重要性,不够全面(文档频率小的词就越重要,文档频率大的词就越无用,显然这并不是完全正确的)
- TF-IDF值的计算没有加入词的位置信息,不够严谨(出现在文档标题、第一段、每一段的第一句话中的词应给予较大的权重)
Python实现
jieba
jieba内置了TF-IDF算法,调用非常简单,例:
sen = '自然语言处理是人工智能和语言学领域的分支学科,此领域探讨如何处理及运用自然语言,包括多方面和步骤。'
print(' jieba extract:', jieba.analyse.extract_tags(sen, topK=topK)) # ['自然语言', '领域', '处理']
topK:返回 TF-IDF 值最大的关键词个数,此处为 3
更详细用法可参考官方文档:https://github.com/fxsjy/jieba
sklearn
关键词提取需用到 CountVectorizer 和 TfidfVectorizer,示例代码:
corpus = [ # 语料
'自然语言处理是人工智能和语言学领域的分支学科,此领域探讨如何处理及运用自然语言,包括多方面和步骤。',
'计算机视觉是一门研究如何使机器“看”的科学,用摄影机和计算机代替人眼对目标进行识别、跟踪和测量。',
'机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。'
]
corpus = [jieba.lcut(sen) for sen in corpus]
with open('stop_words.txt', encoding='utf8') as f:
stop_words = [line.strip() for line in f.readlines()]
corpus = [' '.join(filter_stop_words(sen, stop_words)) for sen in corpus] cvec = CountVectorizer()
cvec.fit_transform(corpus)
feature_words = cvec.get_feature_names()
feature_words = np.array(feature_words) tvec = TfidfVectorizer()
tvec = tvec.fit_transform(corpus)
first_sen = tvec.toarray()[0]
max_indices = np.argsort(-first_sen)[:topK]
print('sklearn extract:', feature_words[max_indices]) # ['自然语言' '领域' '语言学']
完整项目地址:https://github.com/cyandn/practice/tree/master/TF-IDF
参考:
https://www.jianshu.com/p/b0ba00ccaf9c
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
https://blog.csdn.net/Eastmount/article/details/50323063
https://blog.csdn.net/m0_37324740/article/details/79411651
TF-IDF算法简析的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- DiskGenius注册算法简析
初次接触DiskGenius已经成为遥远的记忆,那个时候还只有DOS版本.后来到Windows版,用它来处理过几个找回丢失分区的案例,方便实用.到现在它的功能越来越强大,成为喜好启动技术和桌面支持人员 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- 基于DFA敏感词查询的算法简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: a.直 ...
- SHA安全散列算法简析
1 SHA算法简介 1.1 概述 SHA (Secure Hash Algorithm,译作安全散列算法) 是美国国家安全局 (NSA) 设计,美国国家标准与技术研究院(NIST) 发布的一系列密码散 ...
随机推荐
- 把JSON数据格式转换为Python的类对象
JOSN字符串转换为自定义类实例对象 有时候我们有这种需求就是把一个JSON字符串转换为一个具体的Python类的实例,比如你接收到这样一个JSON字符串如下: {"Name": ...
- ORM之EF初识
之前有写过ef的codefirst,今天来更进一步认识EF! 一:EF的初步认识 ORM(Object Relational Mapping):对象关系映射,其实就是一种对数据访问的封装.主要实现流程 ...
- 网传英特尔酷睿第十代桌面处理器(Comet Lake 14nm)规格
自从农企(AMD)2016年开始崛起时,牙膏厂(英特尔)就开始发力,陆续两代推出性价比颇高的桌面处理器, 第八代.第九代酷睿桌面处理器相当的给力,而第十代酷睿桌面处理器会很猛啊,据传从酷睿i3到酷睿i ...
- 201871010108-高文利《面向对象程序设计(java)》第二周学习总结
项目 内容 这个作业属于哪个课程 <任课教师博客主页链接>https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地址>http ...
- 201871010121-王方《面向对象程序设计(Java)》第四周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- jsp获取map
1.简单Map User user = new User(); user.setName("zmy"); user.setAge(); user.setBirthday(new D ...
- CF308C-Sereja and Brackets-(线段树+括号匹配)
题意:给出一段括号,多次询问某个区间内能匹配多少括号. 题解:线段树,结构体三个属性,多余的左括号l,多余的右括号r,能够匹配的括号数val. 当前结点的val=左儿子的val+右儿子的val+min ...
- A Deep Dive into PL/v8
Back in August, Compose.io announced the addition of JavaScript as an internal language for all new ...
- I/O管理杂记
这是一篇杂记,记录了操作系统层面与I/O管理的零散知识点,用于温习使用.由于I/O管理是一个很大的范畴,后续会不断按照自己的生产需求来补充用的到的知识点.计算机系统是人造系统,没有绝对的对错(相对于自 ...
- Python错误“ImportError: No module named MySQLdb”解决方法
这个错误可能是因为没有安装MySQL模块,这种情况下执行如下语句安装: pip install MySQLdb 如果安装时遇到错误“_mysql.c:29:20: 致命错误:Python.h:没有那个 ...