TF-IDF算法简析
TF-IDF算法可用来提取文档的关键词,关键词在文本聚类、文本分类、文献检索、自动文摘等方面有着重要应用。
算法原理
TF:Term Frequency,词频
IDF:Inverse Document Frequency,逆文档频率
词频(TF):某一个词在该文件中出现的频率
计算方法为:

逆文档频率(IDF):总文件数目除以包含该词的文件数目
计算方法为:
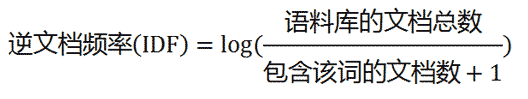
分母加1是为了防止该词不在语料库中而导致被除数为零
最后,TF-IDF的计算方式为:

TF-IDF 的主要思想为:
如果某个词在一篇文档中出现的频率高(即 TF 高),并且在语料库中其他文档中很少出现(即 IDF 高),则认为这个词具有很好的类别区分能力
算法过程:先计算出文档中每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词作为关键词进行输出
算法优点:
原理简单,能满足大多数实际需求
算法缺点:
- 单纯以 “词频” 衡量一个词的重要性,不够全面(文档频率小的词就越重要,文档频率大的词就越无用,显然这并不是完全正确的)
- TF-IDF值的计算没有加入词的位置信息,不够严谨(出现在文档标题、第一段、每一段的第一句话中的词应给予较大的权重)
Python实现
jieba
jieba内置了TF-IDF算法,调用非常简单,例:
sen = '自然语言处理是人工智能和语言学领域的分支学科,此领域探讨如何处理及运用自然语言,包括多方面和步骤。'
print(' jieba extract:', jieba.analyse.extract_tags(sen, topK=topK)) # ['自然语言', '领域', '处理']
topK:返回 TF-IDF 值最大的关键词个数,此处为 3
更详细用法可参考官方文档:https://github.com/fxsjy/jieba
sklearn
关键词提取需用到 CountVectorizer 和 TfidfVectorizer,示例代码:
corpus = [ # 语料
'自然语言处理是人工智能和语言学领域的分支学科,此领域探讨如何处理及运用自然语言,包括多方面和步骤。',
'计算机视觉是一门研究如何使机器“看”的科学,用摄影机和计算机代替人眼对目标进行识别、跟踪和测量。',
'机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。'
]
corpus = [jieba.lcut(sen) for sen in corpus]
with open('stop_words.txt', encoding='utf8') as f:
stop_words = [line.strip() for line in f.readlines()]
corpus = [' '.join(filter_stop_words(sen, stop_words)) for sen in corpus] cvec = CountVectorizer()
cvec.fit_transform(corpus)
feature_words = cvec.get_feature_names()
feature_words = np.array(feature_words) tvec = TfidfVectorizer()
tvec = tvec.fit_transform(corpus)
first_sen = tvec.toarray()[0]
max_indices = np.argsort(-first_sen)[:topK]
print('sklearn extract:', feature_words[max_indices]) # ['自然语言' '领域' '语言学']
完整项目地址:https://github.com/cyandn/practice/tree/master/TF-IDF
参考:
https://www.jianshu.com/p/b0ba00ccaf9c
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
https://blog.csdn.net/Eastmount/article/details/50323063
https://blog.csdn.net/m0_37324740/article/details/79411651
TF-IDF算法简析的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- DiskGenius注册算法简析
初次接触DiskGenius已经成为遥远的记忆,那个时候还只有DOS版本.后来到Windows版,用它来处理过几个找回丢失分区的案例,方便实用.到现在它的功能越来越强大,成为喜好启动技术和桌面支持人员 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- 基于DFA敏感词查询的算法简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: a.直 ...
- SHA安全散列算法简析
1 SHA算法简介 1.1 概述 SHA (Secure Hash Algorithm,译作安全散列算法) 是美国国家安全局 (NSA) 设计,美国国家标准与技术研究院(NIST) 发布的一系列密码散 ...
随机推荐
- HTML中的音频 视频 的播放代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- javascript实现上传图片并展示
我们也都知道上传图片的样子是这样的(选择前)是这样的(选择后). 先在HTML设置图片上传 <form action="" method=""> & ...
- JMX——以可视化形式管理与监控正在运行中的Java程序
简单理解: MBean:管理的最小单元,一个MBean就是一个可以被监控的JavaBean. MBeanServer:一个池子,各个MBean都会注册到该池子中,并且该池子提供一系列的管理.监控API ...
- kernel: nfsd: too many open TCP sockets, consider increasing the number of threads
在/var/log/syslog中看到如下报错: kernel: nfsd: too many open TCP sockets, consider increasing the number o ...
- 第一部分day2-for、while、数据类型(字符串、列表、元组)
数据类型 数据类型的初识 1.数字 整数 int (integer) 整型 (注:python3 不区分整型和长整型,统一称之为整型) 长整型 float(浮点型) complex(复数) 是由实数和 ...
- centos7下搭建JDK和Hadoop
涉及基础操作命令 这里只是将涉及到的提了下一下具体的使用还需要读者自己查阅资料 tar 解压命令 su 进入root用户模式 rm -rf 删除 cd /文件名/.../ 进入某个文件夹下 注意要逐层 ...
- postMessage的使用
一.简介 1.postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档.多窗口.跨域消息传递 2.postMessage(data,origin)方法接受两个参数 ...
- ABP 报错1
报错:.net core 2.2 HTTP Error 502.5 - ANCM Out-Of-Process Startup Failure 解决:安装.net core 2.2就解决了, 本地安装 ...
- Problem C. 欧皇 ————2019.10.12
题目: 再次感激土蛋 #include <bits/stdc++.h> using namespace std; typedef long long ll; ; ll C[][]; voi ...
- 【游记】CSP-S2019游记
\(\Large\texttt{Day -1}\) 今天晚上gryz开了也许是晚宴(awa),有水饺和蛋糕.因为去拿笔记本的原因没有吃到蛋糕..好可惜. 明天不用上早自习太棒了. 明天出发报道. 这笔 ...