《TensorFlow2深度学习》学习笔记(二)手动搭建并测试简单神经网络(附mnist.npz下载方式)
本实验使用了mnist.npz数据集,可以使用在线方式导入,但是我在下载过程中老是因为网络原因被打断,因此使用离线方式导入,离线包已传至github方便大家下载:
https://github.com/guangfuhao/Deeplearning/blob/master/mnist.npz (mnist.npz下载)
下面是全部代码:
#1.Import the neccessary libraries needed
import numpy as np
import tensorflow as tf
import matplotlib
from matplotlib import pyplot as plt ######################################################################## #2.Set default parameters for plots
matplotlib.rcParams['font.size'] = 20
matplotlib.rcParams['figure.titlesize'] = 20
matplotlib.rcParams['figure.figsize'] = [9, 7]
matplotlib.rcParams['font.family'] = ['STKaiTi']
matplotlib.rcParams['axes.unicode_minus']=False ########################################################################
#3.Initialize Parameters #Initialize learning rate
lr = 1e-3
#Initialize loss array
losses = []
#Initialize the weights layers and the bias layers
w1=tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))
b1=tf.Variable(tf.zeros([256]))
w2=tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1))
b2=tf.Variable(tf.zeros([128]))
w3=tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1))
b3=tf.Variable(tf.zeros([10])) ######################################################################## #4.Import the minist dataset by numpy offline
def load_mnist():
#define the directory where mnist.npz is(Please watch the '\'!)
path = r'F:\learning\machineLearning\forward_progression\mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'],f['y_train']
x_test, y_test = f['x_test'],f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
(train_image,train_label),_ = load_mnist()
x = tf.convert_to_tensor(train_image, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(train_label, dtype=tf.int32)
#Reshape x from [60k, 28, 28] to [60k, 28*28]
x=tf.reshape(x,[-1,28*28]) ######################################################################## #5.Combine x and y as a tuple and batch them
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
'''
#Encapsulate train_db as an iterator object
train_iter = iter(train_db)
sample = next(train_iter)
''' ######################################################################## #6.Iterate database for 20 times
for epoch in range(20):
#For every batch:x:[128, 28*28],y: [128]
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape: # tf.Variable
# x: [b, 28*28]
# h1 = x@w1 + b1
# [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] => [b, 10]
out = h2@w3 + b3 # y: [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10) # compute loss
# mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss) # compute gradients
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
#Update the weights and the bias
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5]) if step % 100 == 0:
print(epoch, step, 'loss:', float(loss)) losses.append(float(loss)) ######################################################################## #7.Show the change of losses via matplotlib
plt.figure()
plt.plot(losses, color='C0', marker='s', label='训练')
plt.xlabel('Epoch')
plt.legend()
plt.ylabel('MSE')
#Save figure as '.svg' file
#plt.savefig('forward.svg')
plt.show()
第一部分没什么好讲的,导入了numpy,tensorflow,matplot和pyplot库
import numpy as np
import tensorflow as tf
import matplotlib
from matplotlib import pyplot as plt
第二部分设置了matplot画图的一些参数
pylot使用rc配置文件来自定义图形的各种默认属性,称之为rc配置或rc参数。通过rc参数可以修改默认的属性,包括窗体大小、每英寸的点数、线条宽度、颜色、样式、坐标轴、坐标和网络属性、文本、字体等
font.size为字体大小,figure.titlesize为标题大小,figure.figsize为图像显示大小,font.family设置字体为STKaiTi显示中文,axes.unicode_minus设置正常显示字符
matplotlib.rcParams['font.size'] = 20
matplotlib.rcParams['figure.titlesize'] = 20
matplotlib.rcParams['figure.figsize'] = [9, 7]
matplotlib.rcParams['font.family'] = ['STKaiTi']
matplotlib.rcParams['axes.unicode_minus']=False
第三部分初始化一些参数,lr为学习率(我将lr调整为1e-2时最终的losses变的更小了,但是目前并不知道这个值会对网络的最终表现产生什么样的影响),就是控制参数在每次梯度下降中下降的速率,losses用来存储每次epoch结束时的loss,还用截断正态分布(在tf.truncated_normal中如果x的取值在区间(μ-2σ,μ+2σ)之外则重新进行选择。这样保证了生成的值都在均值附近)初始化了三层权重层和用0初始化了偏置层
#Initialize learning rate
lr = 1e-3
#Initialize loss array
losses = []
#Initialize the weights layers and the bias layers
w1=tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))
b1=tf.Variable(tf.zeros([256]))
w2=tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1))
b2=tf.Variable(tf.zeros([128]))
w3=tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1))
b3=tf.Variable(tf.zeros([10]))
第四部分导入了minist数据集并对x的维度做了预处理,其中path为自己本地下载的mnist.npz的位置,注意这里是右斜杠!
def load_mnist():
#define the directory where mnist.npz is(Please watch the '\'!)
path = r'F:\learning\machineLearning\forward_progression\mnist.npz'
f = np.load(path)
x_train, y_train = f['x_train'],f['y_train']
x_test, y_test = f['x_test'],f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
(train_image,train_label),_ = load_mnist()
x = tf.convert_to_tensor(train_image, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(train_label, dtype=tf.int32)
#Reshape x from [60k, 28, 28] to [60k, 28*28]
x=tf.reshape(x,[-1,28*28])
第五部分将数据集做了batch切分,每个batch为128(这里的batch大小为什么是128存疑,我试过200和100但没发现什么区别)条数据,至于什么是Batch和Epoch,可以直接向下至文末查看
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
第六部分Epoch20次,用mse计算loss,下面为mse的解释:

tf.GradientTape(梯度带)
__init__(persistent=False,watch_accessed_variables=True)
作用:创建一个新的GradientTape
参数:
persistent: 布尔值,用来指定新创建的gradient tape是否是可持续性的。默认是False,意味着只能够调用一次gradient()函数
watch_accessed_variables: 布尔值,表明这个gradien tap是不是会自动追踪任何能被训练(trainable)的变量。默认是True。要是为False的话,意味着你需要手动去指定你想追踪的那些变量
下面的前向计算过程都需要包裹在 with tf.GradientTape() as tape 上下文中,使得前向计算时能够保存计算图信息,方便反向求导运算。assign_sub()将原地(In-place)减去给定的参数值,实现参数的自我更新操作
for epoch in range(20):
#For every batch:x:[128, 28*28],y: [128]
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape: # tf.Variable
# x: [b, 28*28]
# h1 = x@w1 + b1
# [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] => [b, 10]
out = h2@w3 + b3 # y: [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10) # compute loss
# mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss) # compute gradients
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
#Update the weights and the bias
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5]) if step % 100 == 0:
print(epoch, step, 'loss:', float(loss)) losses.append(float(loss))
第七部分将losses随训练次数的增加的变化展示出来
plt.figure()
plt.plot(losses, color='C0', marker='s', label='训练')
plt.xlabel('Epoch')
plt.legend()
plt.ylabel('MSE')
#Save figure as '.svg' file
#plt.savefig('forward.svg')
plt.show()
下图是最终的loss曲线:
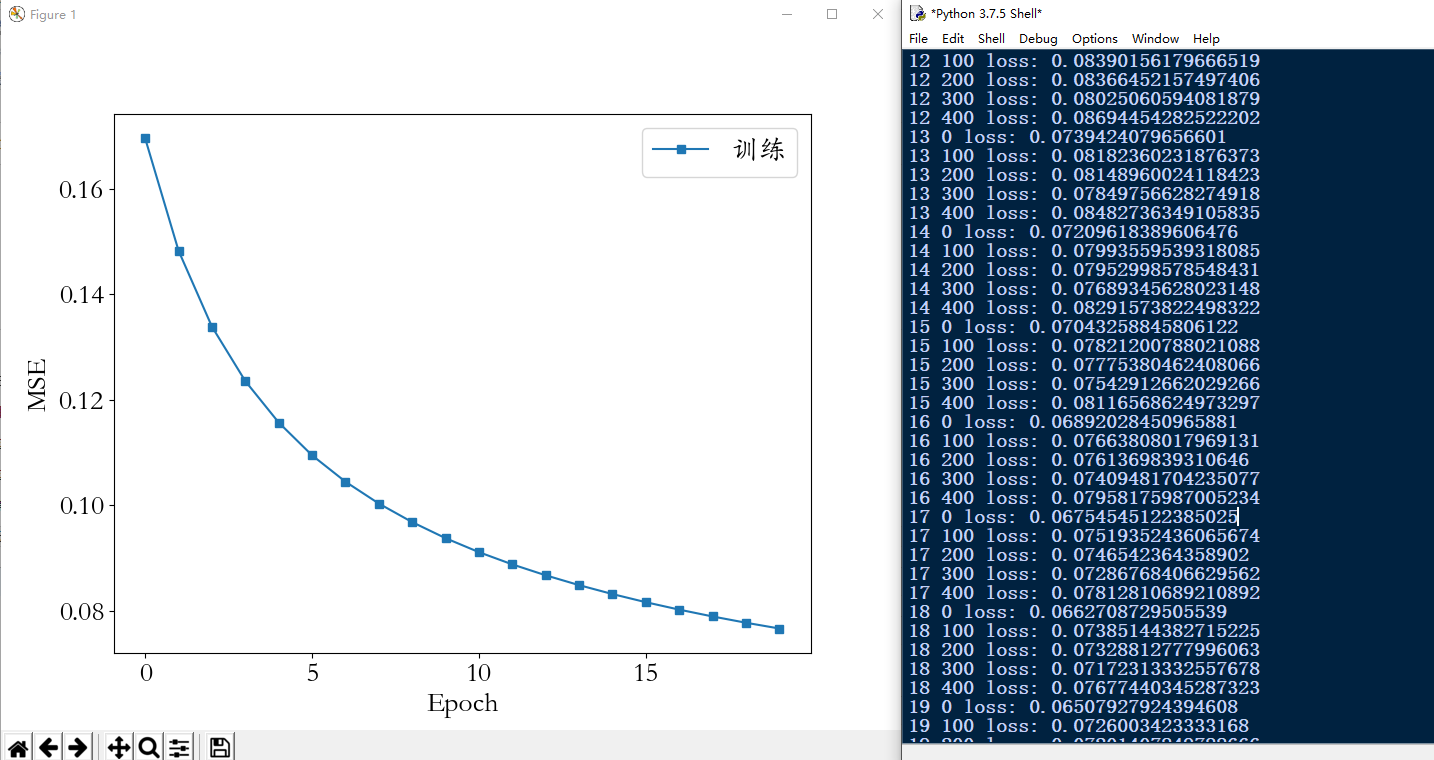
Batch和Epoch通俗易懂的解释:(参考自https://blog.csdn.net/weixin_42137700/article/details/84302045)
假设您有一个包含200个样本(数据行)的数据集,并且您选择的Batch大小为5和1,000个Epoch。
这意味着数据集将分为40个Batch,每个Batch有5个样本。每批五个样品后,模型权重将更新。
这也意味着一个epoch将涉及40个Batch或40个模型更新。
有1000个Epoch,模型将暴露或传递整个数据集1,000次。在整个培训过程中,总共有40,000Batch。
《TensorFlow2深度学习》学习笔记(二)手动搭建并测试简单神经网络(附mnist.npz下载方式)的更多相关文章
- Tensorflow学习:(二)搭建神经网络
一.神经网络的实现过程 1.准备数据集,提取特征,作为输入喂给神经网络 2.搭建神经网络结构,从输入到输出 3.大量特征数据喂给 NN,迭代优化 NN 参数 4.使 ...
- vue新手入门之使用vue框架搭建用户登录注册案例,手动搭建webpack+Vue项目(附源码,图文详解,亲测有效)
前言 本篇随笔主要写了手动搭建一个webpack+Vue项目,掌握相关loader的安装与使用,包括css-loader.style-loader.vue-loader.url-loader.sass ...
- Mybatis-Plus 实战完整学习笔记(二)------环境搭建
第二章 使用实例 1.搭建测试数据库 -- 创建库 CREATE DATABASE mp; -- 使用库 USE mp; -- 创建表 CREATE TABLE tbl_employee( ...
- 深度学习入门教程UFLDL学习实验笔记二:使用向量化对MNIST数据集做稀疏自编码
今天来做UFLDL的第二个实验,向量化.我们都知道,在matlab里面基本上如果使用for循环,程序是会慢的一逼的(可以说基本就运行不下去)所以在这呢,我们需要对程序进行向量化的处理,所谓向量化就是将 ...
- Scala学习教程笔记二之函数式编程、Object对象、伴生对象、继承、Trait、
1:Scala之函数式编程学习笔记: :Scala函数式编程学习: 1.1:Scala定义一个简单的类,包含field以及方法,创建类的对象,并且调用其方法: class User { private ...
- redis学习笔记(二)——java中jedis的简单使用
redis怎么在java中使用,那就是要用到jedis了,jedis是redis的java版本的客户端实现,原本原本想上来就直接学spring整合redis的,但是一口吃个胖子,还是脚踏实地,从基础开 ...
- hibernate框架学习笔记1:搭建与测试
hibernate框架属于dao层,类似dbutils的作用,是一款ORM(对象关系映射)操作 使用hibernate框架好处是:操作数据库不需要写SQL语句,使用面向对象的方式完成 这里使用ecli ...
- 剑指offer学习读书笔记--二维数组中的查找
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都是按照从上到下递增的顺序排序.请设计一个函数,输入这样的一个二维数组和一个整数,判断数组是否含有这个整数. 1 2 8 9 2 4 9 1 ...
- U3D学习使用笔记(二)
1.在移动端www.texture使用时不能实时加载纹理,www.LoadImageIntoTexture使用没问题 2.public FaceFeature FaceFeatureData ...
随机推荐
- [Golang] Gin框架学习笔记
0x0 Gin简介 1.Gin 是什么? Gin 是一个用 Go (Golang) 编写的 HTTP web 框架. 它是一个类似于 martini 但拥有更好性能的 API 框架, 由于 httpr ...
- Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)
PSENet V2昨日刚出,今天翻译学习一下. 场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步.尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署 ...
- 最常见的Java面试题及答案汇总(二)
上一篇:最常见的Java面试题及答案汇总(一) 容器 18. java 容器都有哪些? 常用容器的图录: 19. Collection 和 Collections 有什么区别? java.util.C ...
- Docker Compose 部署Nginx服务实现负载均衡
Compose简介: Compose是Docker容器进行编排的工具,定义和运行多容器的应用,可以一条命令启动多个容器,使用Docker Compose,不再需要使用shell脚本来启动容器.Comp ...
- Linux文件的基本操作函数
1.Linux文件的基本操作 Linux文件的基本操作主要包括了文件的创建.打开.读写和关闭等基本操作. 1.1.文件操作系统调用 (1)创建文件系统函数 int creat(const char * ...
- python面试题300道答案参考1
提示 自己整合的答案,虽有百家之所长,仍很局限,如有需要改进的地方,或者有更好的答案,欢迎提出! [合理利用 Ctrl+F 提高查找效率] 文章来源 https://www.cnblogs.co ...
- .NET Core sdk和runtime区别
SDK和runtime区别 .net core Runtime[跑netcore 程序的] (CoreCLR) .net core SDK (开发工具包 [runtime(jre) + Rolysn( ...
- Django-09-cookie和session
1. 简介 <1> cookie不属于http协议范围,由于http协议无法保持状态,但实际情况,我们却又需要“保持状态”,因此cookie就是在这样一个场景下诞生. cookie的工作原 ...
- python 之 面向对象(元类、__call__、单例模式)
7.13 元类 元类:类的类就是元类,我们用class定义的类来产生我们自己的对象的,内置元类type是用来专门产生class定义的类 code=""" global x ...
- Python解析 算数表达式求值 栈的使用
使用Python实现一种算数表达式求值的算法,模拟这种使用栈的方式,这是由E.W.Dijkstra在20世纪60年代发明的一种非常简单的算法.代码模拟仅仅表现一种编程思想,代码的逻辑并不完全: if ...