SQL Server 使用文件组备份降低备份文件占用的存储空间
对于DBA来说,备份和刷新简历是最重要的两项工作,如果发生故障后,发现备份也不可用,那么刷新简历的重要性就显现出来,哇咔咔!当然备份是DBA最重要的事情(没有之一),在有条件的情况下,我们应该在多个服务器上保留多份完备和日志备份,甚至某些公司会要求将完备数据保留到磁带或超大存储上,以保证可以恢复很久之前的数据。
于是便有一个艰难的选择:备份空间和备份保存期,磁盘再便宜也是要钱的,尤其某些吝啬的老板宁愿多花几十万招个人也不宁愿在硬件上多投资一丁点,把不得把服务器所有资源都利用起来才高兴,在备份空间有限的情况下,我们如何合理设计备份策略以及“备份验证”策略变得尤为关键。
在很久之前读过一篇文章,描述某DBA为降低数据库完备占用的存储空间,采用如下方式:
1. 采用完整备份和日志备份将数据库还原到特定时间点(如每天凌晨0点)
2. 删除用户数据库上所有非聚集索引,然后压缩备份
3. 将该备份进行归档保存。
从业务角度来说,对于很早之前的数据,即使需要恢复,也不可能将该库恢复到特定时间点并使用恢复的新库进行生产,因此对于很早之前的备份,我们只关心数据而不关心数据上建立的那些索引,即使处于查询需要,也可以重新建立索引后再进行查询。该DBA正是以此为出发点,很多数据库上的非聚集索引能占数据库50%甚至70%的空间(我曾经看过一个表上数十个非聚集索引,部分还是包含索引,占用空间是数据的四五倍以上),删除非聚集索引方式能很有效地降低备份占用的存储空间。
=============================================================
当然上面的废话不是今天的重点,今天的重点是文件组备份。
周末与小伙伴吃饭时,好友paddy提到一个备份策略,将数据和索引拆分到不同文件组(这策略应该很多DBA都会采用),然后只备份“数据”文件组,这样在保证恢复数据的需求的前提下最大限度地降低“数据备份”的占用的存储空间。
演示Demo:
首先创建数据库TestDB1001,并创建两个文件组来分别存放DATA和INDEX
CREATE DATABASE [TestDB1001]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'TestDB1001', FILENAME = N'D:\data files\TestDB1001.mdf' ),
FILEGROUP [FG_DATA]
( NAME = N'TestDB1001_DATA1', FILENAME = N'D:\data files\TestDB1001_DATA1.ndf' ),
FILEGROUP [FG_INDEX]
( NAME = N'TestDB1001_INDEX1', FILENAME = N'D:\data files\TestDB1001_INDEX1.ndf' )
LOG ON
( NAME = N'TestDB1001_log', FILENAME = N'D:\data files\TestDB1001_log.ldf')
GO
PS: 为方便演示,文件增长属性或其他相关信息被移除,演示代码请勿较真
然后创建表和插入数据,注意聚集索引和非聚集索引使用的不同的文件组
USE TestDB1001
GO
CREATE TABLE TB001
(
C1 INT IDENTITY(1,1) NOT NULL,
C2 INT
)
GO
ALTER TABLE TB001
ADD CONSTRAINT PK_TB001
PRIMARY KEY(c1)
ON FG_DATA
GO
CREATE INDEX IDX_C2
ON TB001
(
C2
)
ON FG_INDEX
GO INSERT INTO TB001(C2)
SELECT 1 FROM sys.objects
对数据库进行文件组备份,仅备份PRIMARY和FG_DATA两个文件组:
BACKUP DATABASE TestDB1001 FILEGROUP = N'PRIMARY',FILEGROUP='FG_DATA'
TO DISK = N'D:\SQLDATA\TestDB1001_F1.bak'
对数据库进行第一次日志备份:
BACKUP LOG TestDB1001
TO DISK = N'D:\SQLDATA\TestDB1001_L1.bak'
为演示需要,第二次插入数据:
INSERT INTO TB001(C2)
SELECT 2 FROM sys.objects
然后进行第一次差异备份
BACKUP DATABASE TestDB1001 FILEGROUP = N'PRIMARY',FILEGROUP='FG_DATA'
TO DISK = N'D:\SQLDATA\TestDB1001_D1.bak' WITH DIFFERENTIAL
为演示需要,第三次插入数据:
INSERT INTO TB001(C2)
SELECT 3 FROM sys.objects
然后进行第二次日志备份:
BACKUP LOG TestDB1001
TO DISK = N'D:\SQLDATA\TestDB1001_L2.bak'
备份完成后,我们来验证备份还原的可行性,
首先进行文件组还原,注意在还原时,由于未备份FG_INDEX文件组,因此还原时不需要制定INDEX相关的文件信息
RESTORE DATABASE [TestDB1002]
FILE = N'TestDB1001',
FILE = N'TestDB1001_DATA1'
FROM DISK = N'D:\SQLDATA\TestDB1001_F1.bak'
WITH FILE = 1, MOVE N'TestDB1001' TO N'D:\SQLDATA\TestDB1002.mdf',
MOVE N'TestDB1001_DATA1' TO N'D:\SQLDATA\TestDB1002_DATA1.ndf',
MOVE N'TestDB1001_log' TO N'D:\SQLDATA\TestDB1002_log.ldf',
NOUNLOAD, STATS = 10,NORECOVERY,PARTIAL
然后还原差异备份:
RESTORE DATABASE [TestDB1002] FROM DISK='D:\SQLDATA\TestDB1001_D1.bak' WITH NORECOVERY
最后还原日志备份:
RESTORE DATABASE [TestDB1002] FROM DISK='D:\SQLDATA\TestDB1001_L2.bak' WITH RECOVERY
验证数据是否正常:
SELECT C2,COUNT(1) FROM TB001
GROUP BY C2
数据验证通过,证明该方法的确可行。
========================================================
在进行文件组还原的时候,其中PARTIAL选项非常关键,其直接影响后面日志备份是否可用,如果未指定PARTIAL选项,则:
使用WITH RECOVERY选项还原差异备份,不报错,数据库仍处于“正在还原”模式下,还原信息为:
已为数据库 'TestDB1002',文件 'TestDB1001' (位于文件 1 上)处理了 72 页。
已为数据库 'TestDB1002',文件 'TestDB1001_DATA1' (位于文件 1 上)处理了 16 页。
已为数据库 'TestDB1002',文件 'TestDB1001_log' (位于文件 1 上)处理了 3 页。
通过数据库或文件还原操作,只还原了文件“TestDB1001_INDEX1”的一部分。必须成功还原整个文件后,才能应用此备份集。
此 RESTORE 语句成功地执行了一些操作,但由于需要一个或多个 RESTORE 步骤,无法使数据库在线。以前的消息说明了此时无法进行恢复的原因。
RESTORE DATABASE ... FILE=<name> 成功处理了 91 页,花费 0.059 秒(11.983 MB/秒)。
使用WITH RECOVERY选项还原日志备份,直接报错,错误消息为:
消息 4320,级别 16,状态 13,第 1 行
通过数据库或文件还原操作,只还原了文件“TestDB1001_INDEX1”的一部分。必须成功还原整个文件后,才能应用此备份集。
消息 3119,级别 16,状态 1,第 1 行
在计划 RESTORE 语句时发现了问题。以前的消息提供了详细信息。
消息 3013,级别 16,状态 1,第 1 行
RESTORE DATABASE 正在异常终止。
因此在还原文件组备份时,请务必确保使用PARTIAL选项。
详细步骤参考:
--创建测试数据库,使用的是邹老大的代码
CREATE DATABASE db
ON PRIMARY(
NAME='db_data',
FILENAME= 'c:\db_data.mdf'),
FILEGROUP db_fg1(
NAME = 'db_fg1_data',
FILENAME = 'c:\db_fg1_data.ndf'),
FILEGROUP db_fg2(
NAME = 'db_fg2_data',
FILENAME = 'c:\db_fg2_data.ndf')
LOG ON(
NAME='db_log',
FILENAME ='c:\db.ldf')
GO --在文件组db_fg1上创建表,并单独创建该文件组的备份
CREATE TABLE db.dbo.tb(id int) ON db_fg1
BACKUP DATABASE db FILEGROUP='db_fg1' TO DISK='c:\db_fg1.bak' WITH FORMAT
GO --在其他文件组上创建表
CREATE TABLE db.dbo.ta(id int) ON [PRIMARY]
CREATE TABLE db.dbo.tc(id int) ON db_fg2
INSERT db.dbo.tb SELECT id FROM sysobjects
--备份每个文件组,并且备份事务日志
BACKUP DATABASE db FILEGROUP='PRIMARY' TO DISK='c:\db_primary.bak' WITH FORMAT
BACKUP DATABASE db FILEGROUP='db_fg1' TO DISK='c:\db_fg1_new.bak' WITH FORMAT
BACKUP DATABASE db FILEGROUP='db_fg2' TO DISK='c:\db_fg2.bak' WITH FORMAT
BACKUP LOG db TO DISK='c:\db_log.bak' WITH FORMAT
GO --删除数据库
DROP DATABASE db
GO --从文件组备份中恢复数据
RESTORE DATABASE db FILEGROUP='PRIMARY' FROM DISK='c:\db_primary.bak' WITH NORECOVERY,REPLACE
RESTORE DATABASE db FILEGROUP='db_fg1' FROM DISK='c:\db_fg1.bak' WITH NORECOVERY
RESTORE DATABASE db FILEGROUP='db_fg2' FROM DISK='c:\db_fg2.bak' WITH NORECOVERY
RESTORE LOG db FROM DISK='c:\db_log.bak' WITH RECOVERY
SELECT COUNT(*) FROM db.dbo.tb
GO --删除测试数据库
DROP DATABASE db
注: 如果有多个文件组, 只备份主文件组并且还原,还原的数据库中包括其他文件组及表,只是不可用。查询报以下错误

查看文件组状态, 处于恢复中
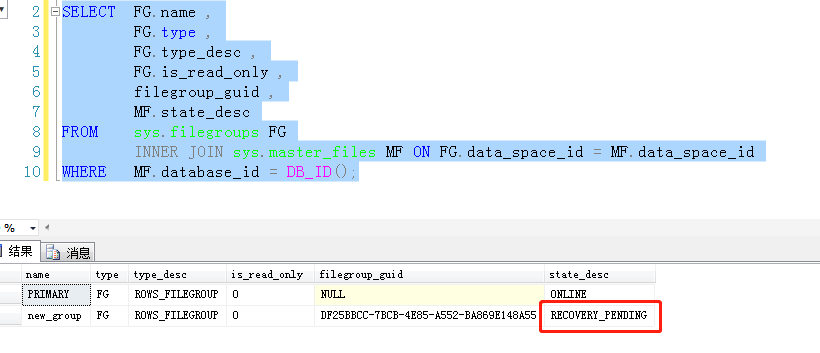
如果需要,还需备份文件组,然后还原过来。
SQL Server 使用文件组备份降低备份文件占用的存储空间的更多相关文章
- SQL Server使用文件组备份降低备份文件占用的存储空间
对于DBA来说,备份和刷新简历是最重要的两项工作,如果发生故障后,发现备份也不可用,那么刷新简历的重要性就显现出来,哇咔咔!当然备份是DBA最重要的事情(没有之一),在有条件的情况下,我们应该在多个服 ...
- sql server 创建文件组,文件
添加文件组: --ADD FILEGROUP 增加文件组 ALTER DATABASE TestHekaton ADD FILEGROUP [Report] ALTER DATABASE TestH ...
- SQL Server数据库文件与文件组总结
文件和文件组概念 关于文件与文件组,简单概括如下,详情请参考官方文档"数据库文件和文件组Database Files and Filegroups"或更多相关资料: 数据文件概念: ...
- SQL Server 2008文件与文件组的关系
此文章主要向大家讲述的是SQL Server 2008文件与文件组,其中包括文件和文件组的含义与关系,文件.文件组在实践应用中经常出现的问题,查询文件组和文件语句与MSDN官方解释等相关内容的介绍. ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- sql server 备份与恢复系列六 文件组备份与还原
一. 概述 文件备份是指备份一个或多个文件或文件组中的所有数据.使用文件备份能够只还原损坏的文件,而不用还原数据库的其余部份,从而加快恢复速度.例如,如果数据库由位于不同磁盘上的若干文件组成,在其中一 ...
- SQL Server 批量主分区备份(Multiple Jobs)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 方案一(Solution One) 方案二(Solution Two) ...
- SQL Server 批量主分区备份(One Job)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 实现代码(SQL Codes) 主分区完整.差异还原(Primary B ...
- [SQL SERVER 2005]数据库差异备份及还原
因为之前遇到还原差异备份,最开始遇到SQLServer报错:”无法还原日志备份或差异备份,因为没有文件可用于前滚“.查阅很多资料后,终于得到解决.收集整理成这篇随笔. 问题原因:出现这种错误绝大多数是 ...
随机推荐
- python--面向对象编程之学生选课系统练习
1.系统目录结构 文件夹注解: bin--系统管理员和学生的主程序代码 config--系统的配置文件 db--系统的数据文件 admin--管理员的数据文件 student--学生的数据文件 lib ...
- 一种动态的样式语言--Less 之 导引混合
.mixin (@a) when (lightness(@a) >= 50%){ background-color: black; } .mixin (@a) when (lightness(@ ...
- arduino 开发视频
http://blog.uctronics.com/downloads/shields/ArduCAM_Camera_Shield_V2_DS.pdf http://www.arducam.com/k ...
- LeetCode 422. Valid Word Square
原题链接在这里:https://leetcode.com/problems/valid-word-square/ 题目: Given a sequence of words, check whethe ...
- 如何查看WinDbg扩展有哪些命令
如果您想查看任何windbg扩展所支持的命令,可以采用各种方法. 你可以用!<ext_name>.help命令查看该扩展支持的所有命令.用扩展模块名替换<ext_name>.( ...
- JAVA基础--MySQL(二)
数据库约束 1.基础限制 ① 单一表内字节量总和不能超过65535,null 占用一个字节空间 ② varchar存储255 以内字节占用一个字节表示长度,255以上自己则占用两个字节表示长度 ③ ...
- nginx之系统参数优化
系统参数优化 默认的Linux内核参数考虑的是最通用场景,不符合用于支持高并发访问的Web服务器的定义,根据业务特点来进行调整,当Nginx作为静态web内容服务器.反向代理或者提供压缩服务器的服务器 ...
- Codeforces1254B2 Send Boxes to Alice (Hard Version)(贪心)
题意 n个数字的序列a,将i位置向j位置转移x个(a[i]-x,a[j]+x)的花费为\(x\times |i-j|\),最终状态可行的条件为所有a[i]均被K整除(K>1),求最小花费 做法 ...
- Linux-Centos学习笔记
Linux目录结构: 只有1个目录,根目录 usr:相当于program files etc:存放系统配置文件 root:系统管理员默认目录 home:存放其他用户的目录 pwd: 打印当前目录 cd ...
- C-Store: A Column-oriented DBMS Mike
这篇paper比较老,是列存比较基础的论文 几乎所有列存,或olap的论文都会引用这篇 行存面向写,支持OLTP 列存面向读,支持OLAP 基于磁盘的DBMS,瓶颈基本在磁盘IO,所有做的工作都是用多 ...