Flink(一) —— 启动与基本使用
一、介绍
Apache Flink is an open source platform for distributed stream and batch data processing.
Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.
Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
批处理与实时处理的优缺点
批处理,吞吐量大,但延时高。
实时处理,延时低,但吞吐量小。
以聊天做比喻,实时处理,来一条回一条,批处理,别人说十句,你最后一起回。
Flink的目标
- 低延迟
- 高吞吐
- 容错率高,计算正确率高
流数据处理的应用场景
- 电商、市场营销
- 数据报表
- 金融、银行
- 实时监测异常行为
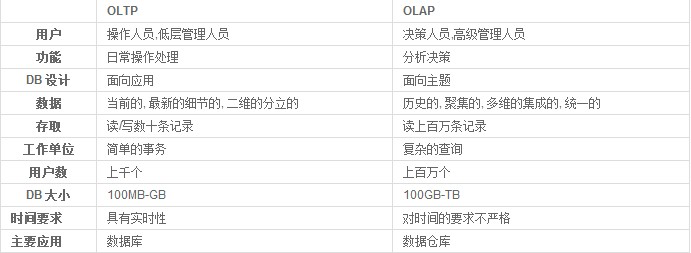
OLTP和OLAP
OLTP(on-line transaction processing)联机事务处理,面向的是事务,处理几条数据。
OLAP(on-line analytical processing)面向的是一堆数据的数据分析。
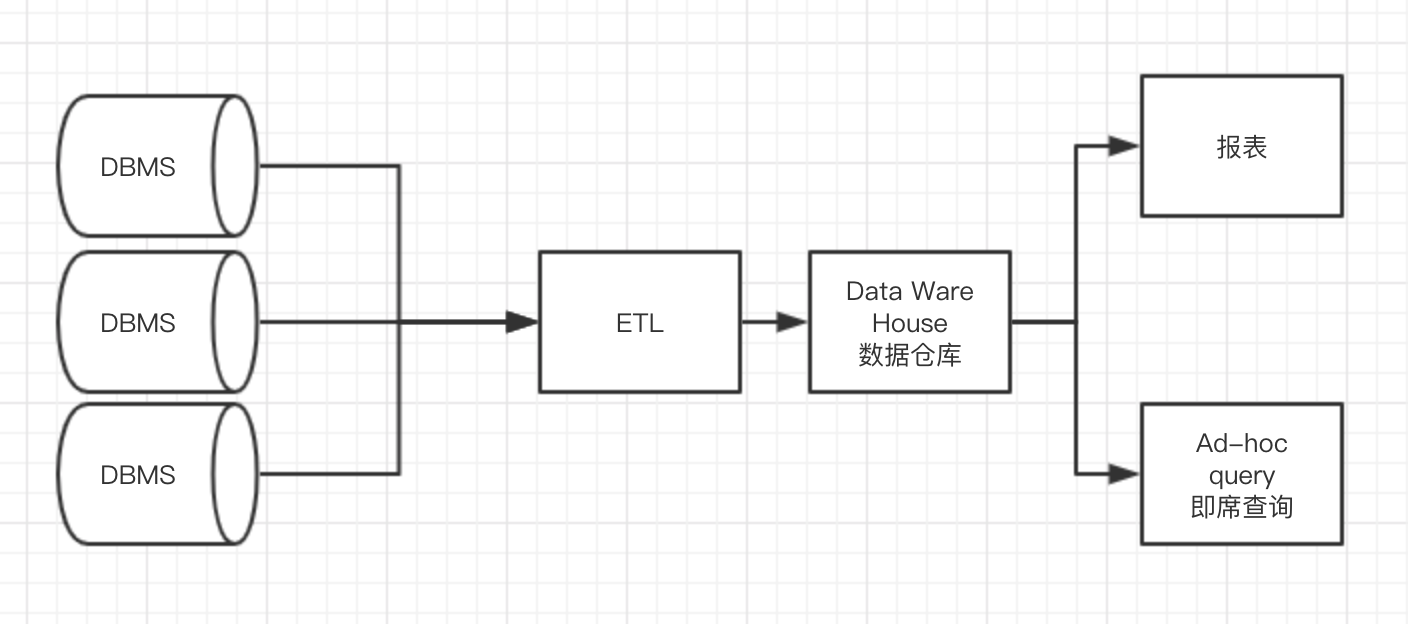
Ad-hoc
即席查询,用户根据自己的需求、灵活地选择查询条件,可以理解为需求不太明确的查询,由用户自定义的查询。
流处理的演变
从起初单纯的流处理,转变为后来的流处理和批处理结合的lambda架构。
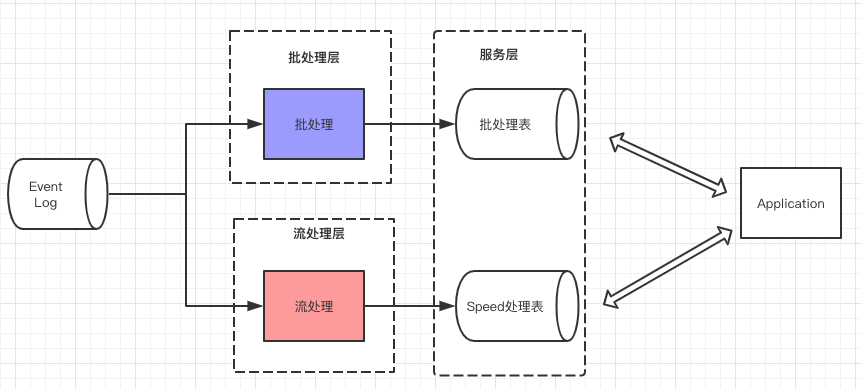
特点就是流处理的数据可能不准确,但延迟低,批处理的数据准确性高,但延迟高,将将两者结合起来。
这就好比是两个人做同一件事,一个人是慢性子做事非常仔细,另一个人是急性子,做事快。急性子的人提前把事情做好,例如得出100,200,300的结果。慢性子也去做同样的事,得出100,250,300,等慢性子把事情做好,最终的结果就会由100,200,300,变为100,250,300。
第一性思考:本质就是优劣势互补。
第三代流式处理,Flink,在lambda架构上又做了改进。
Flink整合了Storm与SparkStreaming的优点。SparkStreaming的逻辑是,将批拆分成更小的批处理,在保证低延时的情况下,还能保证高吞吐。
特点
事件驱动
基于流的世界观,所有东西都是流,批就是有界的流,实时数据就是无界的流。而Spark呢,则是所有东西都是批,SparkStreaming处理的则是更小的批。
分层的API
架构
Apache Flink is a framework and distributed processing engine for stateful computations (状态计算) over unbounded and bounded data streams.
Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
lambda架构
将离线计算和实时计算结合在一起,发挥离线计算准确率高、实时计算响应速度快的优势。缺点是,同一套逻辑要分别在两个模式下实现,存在代码冗余的问题。
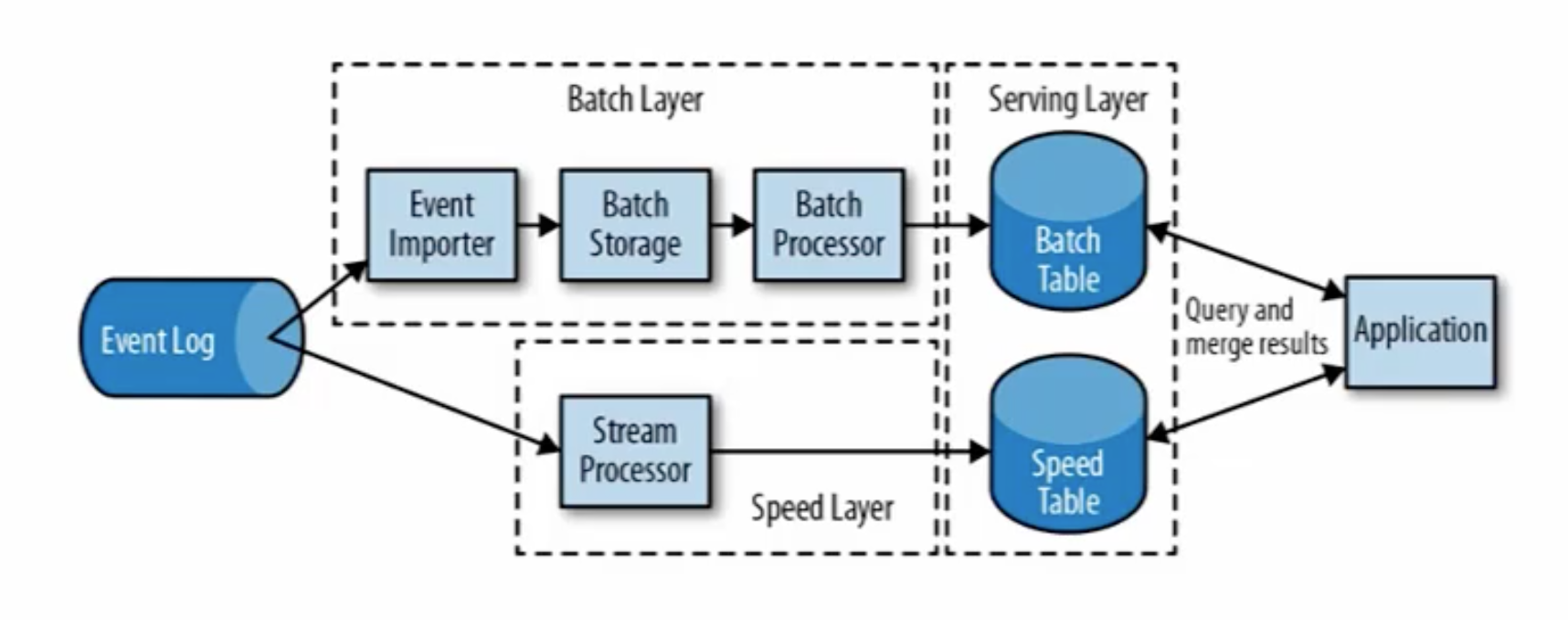
Flink特点
(1)批流一体化
Flink中的思想是,一切都是流。离线计算是有界限的流,实时计算是无界限的流。
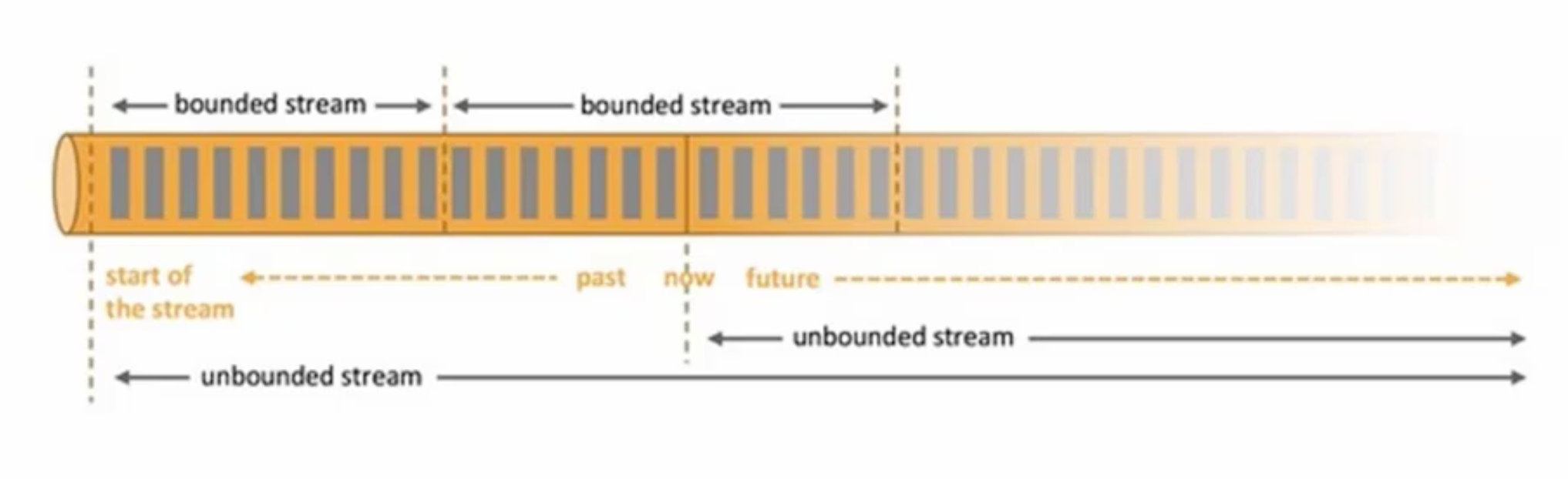
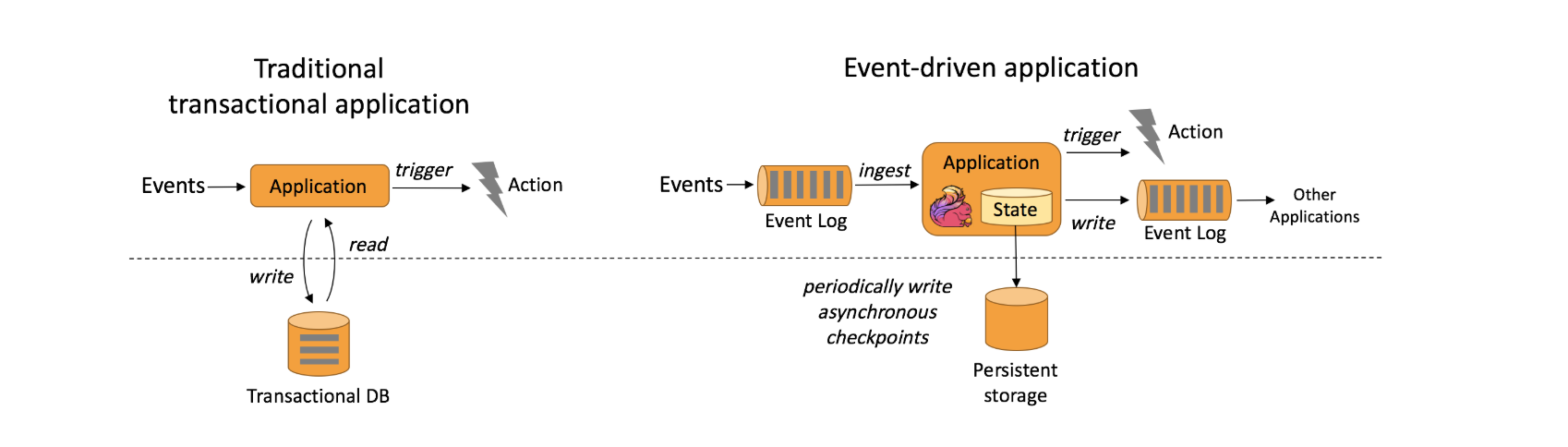
(2)事件驱动型应用
二、基本使用
WordCount
(1)引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
(2)准备数据
hello kafka
hello bigdata
hello flink
hello hbase
hbase
kafka
(3)Flink批处理实现
package flink
import org.apache.flink.api.scala._
object wordcount {
def main(args: Array[String]): Unit = {
//创建一个执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
val inputPath = "word.txt";
val inputDataSet = env.readTextFile(inputPath)
//切分数据,得到word
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
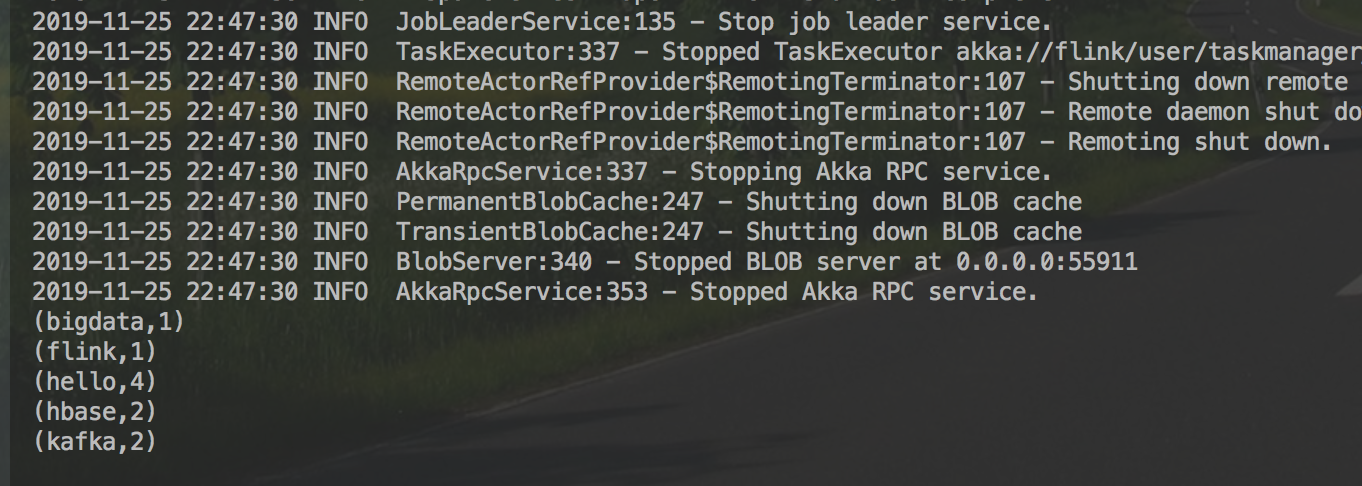
wordCountDataSet.print()
}
}
运行结果
(4)Flink流处理实现
/**
* 流式 WordCount程序
*/
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建一个文本socket
val dataStream = env.socketTextStream("localhost",7777)
val wordCountDataStream = dataStream.flatMap(_.split(" "))
.map((_,1))
.keyBy(0)
.sum(1)
wordCountDataStream.print()
// 启动executor
env.execute("stream word count")
}
}
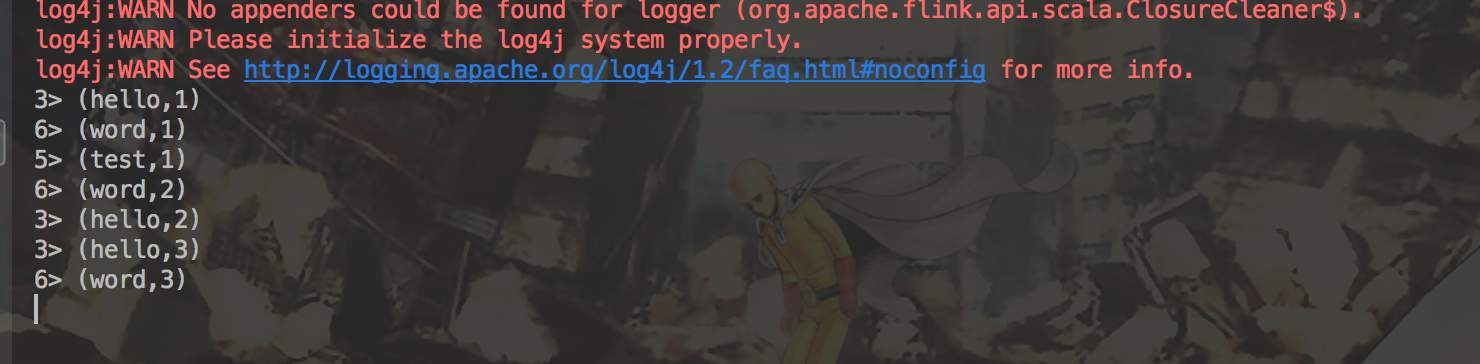
在终端使用nc -lk 7777打开一个socket连接,运行程序,得到结果
参考文档
Flink官方文档
Flink 实时数仓的应用
Apache Flink 零基础入门(一&二):基础概念解析
企业级数据仓库
大数据工程师 Flink技术与实战
Flink(一) —— 启动与基本使用的更多相关文章
- Flink安装启动
1.下载安装包并解压 下载网址:https://flink.apache.org/ 版本选择可以根据安装的hadoop版本和Scala版本进行选择 我用的是:flink-1.3.3-bin-hadoo ...
- flink安装启动(docker)
参考https://hub.docker.com/_/flink/ 相关端口The Web Client is on port 8081JobManager RPC port 6123TaskMana ...
- 一张图轻松掌握 Flink on YARN 应用启动全流程(上)
Flink 支持 Standalone 独立部署和 YARN.Kubernetes.Mesos 等集群部署模式,其中 YARN 集群部署模式在国内的应用越来越广泛.Flink 社区将推出 Flink ...
- Flink集群部署
部署方式 一般来讲有三种方式: Local Standalone Flink On Yarn/Mesos/K8s… 单机模式 参考上一篇Flink从入门到放弃(入门篇2)-本地环境搭建&构建第 ...
- Flink知识点
1. Flink.Storm.Sparkstreaming对比 Storm只支持流处理任务,数据是一条一条的源源不断地处理,而MapReduce.spark只支持批处理任务,spark-streami ...
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- Flink HA
standalone 模式的高可用 部署 flink 使用zookeeper协调多个运行的jobmanager,所以要启用flink HA 你需要把高可用模式设置成zookeeper,配置zookee ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink之DataStreamAPI入门
目录 Types Transformations Defining UDFs 本文API基于Flink 1.4 def main(args: Array[String]) { // 第一种会自动判断用 ...
随机推荐
- iPhone的xib与iPad的xib相互转换
1. xib转换 iPhone版本APP开发完成后需要再开发iPad版本的APP,需要把iPhone版本的xib文件添加到iPad项目中去,但是Xcode中iPhone和iPad使用的xib格式不能完 ...
- js 判断数组中是否包含某个元素(转载)
来源:https://www.cnblogs.com/yunshangwuyou/p/10539090.html 方法一:array.indexOf(item,start):元素在数组中的位置,如果没 ...
- SpringBoot使用MockMVC单元测试Controller
对模块进行集成测试时,希望能够通过输入URL对Controller进行测试,如果通过启动服务器,建立http client进行测试,这样会使得测试变得很麻烦,比如,启动速度慢,测试验证不方便,依赖网络 ...
- DELL R730 做raid10
1.服务器开机,在出现下图提示时,同时按着<ctrl >+ < R >键,即可进入配置界面 2.会进入下图 3.按上下键到第一项PERC H730P MINI ,按F2,选择c ...
- edgex简述
一.概述 Edgex foundry是一个Linux 基金会运营的开源边缘计算物联网软件框架项目,该项目的核心是基于与硬件和操作系统完全无关的参考软件平台建立的互操作框架,使能即插即用的组件生态系统, ...
- mysql 5.7 my.cnf配置
此为配置上生产环境的参数,后续补充参数说明 [client] port=3306 socket = /data/mysql/tmp/mysql.sock # default-character-set ...
- 转载-企业环境下MySQL5.5调优
转载-企业环境下MySQL5.5调优 参照 腾讯云 和ucloud my.cnf 以及网上找的资料 整理出来的 my.cnf , 以后修改任何参数都会继续更新,目前是在测试阶段; 物理机 : ubun ...
- Navicat连接MySQL数据库出现 ERROR 2059 (HY000): Authentication plugin 'caching_sha2_password' cannot be loaded
装了mysql 8之后因为mysql8采用了新的加密方式,很多软件还不支持, 解决方法如下: 1. 管理员权限运行命令提示符,登陆MySQL mysql -u root -p 2. 修改账户密码加密规 ...
- java.lang.IllegalArgumentException: No enum constant org.apache.ibatis.type.JdbcType.Integer
mybatis配置的jdbaType类型要是大写的,否则就会出现此种异常 原因是在xml中配置的 jdbcType中有小写字母
- Docker初识笔记
Docker docker说白了就是:环境打包 我们能用docker什么? 1.如果配置好本地的linux环境交接给其他人,很麻烦,交接时要告诉他,装这个装那个,还可能出现问题,那我直接把这个环境放到 ...