Boosting and AdaBoost
Boosting是一种从一些弱分类器中创建一个强分类器的集成技术(提升算法)。
它先由训练数据构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误。不断添加模型,直到训练集完美预测或已经添加到数量上限。
Bagging与Boosting的区别:取样方式不同。Bagging采用均匀取样,而Boosting根据错误率取样。Bagging的各个预测函数没有权重,而Boosting是由权重的,Bagging的各个预测函数可以并行生成,而Boosing的哥哥预测函数只能顺序生成。
AdaBoost算法的全称是自适应boosting(Adaptive Boosting),是一种用于二分类问题的算法,它用弱分类器的线性组合来构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。
AdaBoost是为二分类开发的第一个真正成功的Boosting算法,同时也是理解Boosting的最佳起点。目前基于AdaBoost而构建的算法中最著名的就是随机梯度boosting。
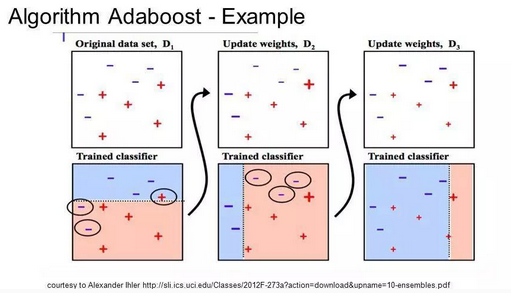
AdaBoost常与短决策树一起使用。
在创建第一棵树之后,每个训练实例在树上的性能都决定了下一棵树需要在这个训练实例上投入多少关注。
难以预测的训练数据会被赋予更多的权重,而易于预测的实例被赋予更少的权重。
模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习效果。
在建完所有树之后,算法对新数据进行预测,并且通过训练数据的准确程度来加权每棵树的性能。
因为算法极为注重错误纠正,所以一个没有异常值的整洁数据十分重要。
AdaBoost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权取和(weighted sum)的方式把这个新分类器结合进已有的分类器中。
它的好处是自带了特征选择(feature selection),只使用在训练集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题。
最经典的AdaBoost实现中,它的每一个弱分类器其实就是一个决策树。这就是之前为什么说决策树是各种算法的基石。
集成学习
AdaBoost算法是一种集成学习(ensemble learning)方法。集成学习是机器学习中的一类方法,它对多个机器学习模型进行组合形成一个精度更高的模型,参与组合的模型称为弱学习器(weak learner)。在预测时使用这些弱学习器模型联合起来进行预测;训练时需要用训练样本集依次训练出这些弱学习器。典型的集成学习算法是随机森林和boosting算法,而AdaBoost算法是boosting算法的一种实现版本。
Boosting and AdaBoost的更多相关文章
- boosting、adaboost
1.boosting Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数.他是一种框架算法,主要是通过对样本集的操作获 ...
- PRML读书会第十四章 Combining Models(committees,Boosting,AdaBoost,决策树,条件混合模型)
主讲人 网神 (新浪微博: @豆角茄子麻酱凉面) 网神(66707180) 18:57:18 大家好,今天我们讲一下第14章combining models,这一章是联合模型,通过将多个模型以某种形式 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- bagging,random forest,boosting(adaboost、GBDT),XGBoost小结
Bagging 从原始样本集中抽取训练集.每轮从原始样本集中使用Bootstraping(有放回)的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中).共进行 ...
- aggregation(2):adaptive Boosting (AdaBoost)
给你这些水果图片,告诉你哪些是苹果.那么现在,让你总结一下哪些是苹果? 1)苹果都是圆的.我们发现,有些苹果不是圆的.有些水果是圆的但不是苹果, 2)其中到这些违反"苹果都是圆的" ...
- adaboost原理与实践
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器).其算法本身是通过改变数据分布来实现的,它根据 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- adaboost原理和实现
上两篇说了决策树到集成学习的大概,这节我们通过adaboost来具体了解一下集成学习的简单做法. 集成学习有bagging和boosting两种不同的思路,bagging的代表是随机森林,boosti ...
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning
A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning by Jason Brownlee on S ...
随机推荐
- Django中ORM过滤时objects.filter()无法对月份过滤
django中的filter日期查询属性有:year.month.day.week_day.hour.minute.second 在做复习博客项目时,我把项目从linux移到了windows,然后博客 ...
- 【1】volatile关键字解析
volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果.在Java 5之后,volatile关键字才得以 ...
- httpd服务的配置及应用
一.httpd服务的配置文件 httpd服务的主配置文件通常为httpd根目录下的conf/httpd.conf文件,通过yum安装的httpd服务的主配置路径通常如下: httpd-2.2:/etc ...
- java之spring mvc之文件上传
目录结构如下: 注意,下面说的配置文件,一般都是值的src下的配置文件,即mvc.xml.如果是web.xml,则直接说 web.xml 1. 文件上传的注意点 表单必须是post提交,必须将 enc ...
- C#设计模式之12:中介者模式
中介者模式 在asp.net core中实现进程内的CQRS时用mediatR是非常方便的,定义command,然后定义commandhandler,或者notification和notificati ...
- 玩转dockerfile
镜像的缓存特性 Docker 会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无需重新创建. 举例说明.在前面的 Dockerfile 中添加一点新内容,往镜像中复制一个文件: ...
- 网页调用文件另存为js
查看引用是否正常,页面添加html代码. <a id="downLoad" onclick="oDownLoad('downLoad')">下载&l ...
- P2711 小行星 (最大流)
题目 P2711 小行星 解析 这道题挺巧妙的,乍一看是空间上的,无从下手,稍微转换一下就可以了. 看到题目,求消除这些行星的最少次数,就是求最小割,也就是求最大流,考虑怎样建图. 考虑当我们消去一个 ...
- springCloud学习4(Zuul服务路由)
镇博图 springcloud 总集:https://www.tapme.top/blog/detail/2019-02-28-11-33 本篇中 Zuul 版本为 1.x,目前最新的是 2.x,二者 ...
- CentOS 7 - 修改时区为上海时区
1.查看时间各种状态: timedatectl Local time: 四 2014-12-25 10:52:10 CSTUniversal time: 四 2014-12-25 02:52:10 U ...