NVIDIA---CUDA
http://en.wikipedia.org/wiki/CUDA
CUDA
| Developer(s) | NVIDIA Corporation |
|---|---|
| Stable release | 6.0 / November 14, 2013; 4 days ago |
| Operating system | Windows XP and later, Mac OS X, Linux |
| Platform | Supported GPUs |
| Type | GPGPU |
| License | Freeware |
| Website | www.nvidia.com/object/cuda_home_new.html |
CUDA (aka Compute Unified Device Architecture) is a parallel computing platform and programming model created by NVIDIA and implemented by the graphics processing units (GPUs) that they produce.[1]CUDA gives program developers direct access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs.
Using CUDA, the GPUs can be used for general purpose processing (i.e., not exclusively graphics); this approach is known as GPGPU. Unlike CPUs, however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly.
The CUDA platform is accessible to software developers through CUDA-accelerated libraries, compiler directives (such as OpenACC), and extensions to industry-standard programming languages, including C,C++ and Fortran. C/C++ programmers use 'CUDA C/C++', compiled with "nvcc", NVIDIA's LLVM-based C/C++ compiler,[2] and Fortran programmers can use 'CUDA Fortran', compiled with the PGI CUDA Fortran compiler from The Portland Group.
In addition to libraries, compiler directives, CUDA C/C++ and CUDA Fortran, the CUDA platform supports other computational interfaces, including the Khronos Group's OpenCL,[3] Microsoft's DirectCompute, and C++ AMP.[4] Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, Haskell,MATLAB, IDL, and native support in Mathematica.
In the computer game industry, GPUs are used not only for graphics rendering but also in game physics calculations (physical effects like debris, smoke, fire, fluids); examples include PhysX and Bullet. CUDA has also been used to accelerate non-graphical applications in computational biology, cryptography and other fields by an order of magnitude or more.[5][6][7][8][9]
CUDA provides both a low level API and a higher level API. The initial CUDA SDK was made public on 15 February 2007, for Microsoft Windows and Linux. Mac OS Xsupport was later added in version 2.0,[10] which supersedes the beta released February 14, 2008.[11] CUDA works with all Nvidia GPUs from the G8x series onwards, including GeForce, Quadro and the Tesla line. CUDA is compatible with most standard operating systems. Nvidia states that programs developed for the G8x series will also work without modification on all future Nvidia video cards, due to binary compatibility.
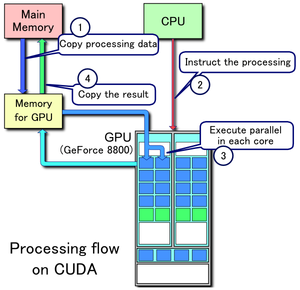

Example of CUDA processing flow
1. Copy data from main mem to GPU mem
2. CPU instructs the process to GPU
3. GPU execute parallel in each core
4. Copy the result from GPU mem to main mem
Contents
[hide]
Background[edit]
The GPU, as a specialized processor, addresses the demands of real-time high-resolution 3D graphics compute-intensive tasks. As of 2012, GPUs have evolved into highly parallel multi-core systems allowing very efficient manipulation of large blocks of data. This design is more effective than general-purpose CPUs for algorithmswhere processing of large blocks of data is done in parallel, such as:
- push-relabel maximum flow algorithm
- fast sort algorithms of large lists
- two-dimensional fast wavelet transform
- molecular dynamics simulations
Advantages[edit]
CUDA has several advantages over traditional general-purpose computation on GPUs (GPGPU) using graphics APIs:
- Scattered reads – code can read from arbitrary addresses in memory
- Shared memory – CUDA exposes a fast shared memory region (up to 48KB per Multi-Processor) that can be shared amongst threads. This can be used as a user-managed cache, enabling higher bandwidth than is possible using texture lookups.[12]
- Faster downloads and readbacks to and from the GPU
- Full support for integer and bitwise operations, including integer texture lookups
Limitations[edit]
- CUDA does not support the full C standard, as it runs host code through a C++ compiler, which makes some valid C (but invalid C++) code fail to compile.[13][14]
- Texture rendering is not supported (CUDA 3.2 and up addresses this by introducing "surface writes" to CUDA arrays, the underlying opaque data structure).
- Copying between host and device memory may incur a performance hit due to system bus bandwidth and latency (this can be partly alleviated with asynchronous memory transfers, handled by the GPU's DMA engine)
- Threads should be running in groups of at least 32 for best performance, with total number of threads numbering in the thousands. Branches in the program code do not affect performance significantly, provided that each of 32 threads takes the same execution path; the SIMD execution model becomes a significant limitation for any inherently divergent task (e.g. traversing a space partitioning data structure during ray tracing).
- Unlike OpenCL, CUDA-enabled GPUs are only available from Nvidia[15]
- Valid C/C++ may sometimes be flagged and prevent compilation due to optimization techniques the compiler is required to employ to use limited resources.
- CUDA (with compute capability 1.x) uses a recursion-free, function-pointer-free subset of the C language, plus some simple extensions. However, a single process must run spread across multiple disjoint memory spaces, unlike other C language runtime environments.
- CUDA (with compute capability 2.x) allows a subset of C++ class functionality, for example member functions may not be virtual (this restriction will be removed in some future release). [See CUDA C Programming Guide 3.1 – Appendix D.6]
- Double precision floats (CUDA compute capability 1.3 and above)[16] deviate from the IEEE 754 standard: round-to-nearest-even is the only supported rounding mode for reciprocal, division, and square root. In single precision, denormals and signalling NaNs are not supported; only two IEEE rounding modes are supported (chop and round-to-nearest even), and those are specified on a per-instruction basis rather than in a control word; and the precision of division/square root is slightly lower than single precision.
Supported GPUs[edit]
Compute capability table (version of CUDA supported) by GPU and card. Also available directly from Nvidia:
| Compute capability (version) |
GPUs | Cards |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32/370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS290, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/240, FX380 LP, 1800M, 370/380M, NVS300, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF106 GF108,GF114, GF116, GF119 | GeForce 500M series, 610M, GT630M,GTX 670M, GeForce GTX 675M, GT 430, GT 440, GTS 450, GTX 460, GT 545, GTX 550 Ti, GTX 560, GTX 560 Ti, 605,615,620, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 770, GTX 760, GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti BOOST, GTX 650 Ti, GTX 650, GT 640, GT 630, GeForce GTX 780M, GeForce GTX 775M(for Apple OEM only), GeForce GTX 770M, GeForce GTX 765M, GeForce GTX 760M, GeForce GT 755M(for Apple OEM only), GeForce GT 750M, GeForce GT 745M, GeForce GT 740M, GeForce GTX 680MX(for Apple OEM only), GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GTX 660M, GeForce GT 650M, GeForce GT 645M, GeForce GT 640M, Quadro K600, Quadro K2000, Quadro K4000, Quadro K5000, Quadro K2100M,Quadro K4100M,Quadro K5100M |
| 3.5 | GK110, GK208 | Tesla K40, K20X, K20, GeForce GTX TITAN, GTX780Ti, GTX 780, Quadro K510M, Quadro K610M, Quadro K6000, GT 640(Rev.2) |
A table of devices officially supporting CUDA:[15]
GeForce GT 630 |
|
|
Version features and specifications[edit]
| Feature support (unlisted features are supported for all compute capabilities) |
Compute capability (version) | ||||||
|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | 3.0 | 3.5 | |
| Integer atomic functions operating on 32-bit words in global memory |
No | Yes | |||||
| atomicExch() operating on 32-bit floating point values in global memory |
|||||||
| Integer atomic functions operating on 32-bit words in shared memory |
No | Yes | |||||
| atomicExch() operating on 32-bit floating point values in shared memory |
|||||||
| Integer atomic functions operating on 64-bit words in global memory |
|||||||
| Warp vote functions | |||||||
| Double-precision floating-point operations | No | Yes | |||||
| Atomic functions operating on 64-bit integer values in shared memory |
No | Yes | |||||
| Floating-point atomic addition operating on 32-bit words in global and shared memory |
|||||||
| _ballot() | |||||||
| _threadfence_system() | |||||||
| _syncthreads_count(), _syncthreads_and(), _syncthreads_or() |
|||||||
| Surface functions | |||||||
| 3D grid of thread block | |||||||
| Warp shuffle functions | No | Yes | |||||
| Funnel shift | No | Yes | |||||
| Dynamic parallelism | |||||||
| Technical specifications | Compute capability (version) | ||||||
|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | 3.0 | 3.5 | |
| Maximum dimensionality of grid of thread blocks | 2 | 3 | |||||
| Maximum x-, y-, or z-dimension of a grid of thread blocks | 65535 | 231-1 | |||||
| Maximum dimensionality of thread block | 3 | ||||||
| Maximum x- or y-dimension of a block | 512 | 1024 | |||||
| Maximum z-dimension of a block | 64 | ||||||
| Maximum number of threads per block | 512 | 1024 | |||||
| Warp size | 32 | ||||||
| Maximum number of resident blocks per multiprocessor | 8 | 16 | |||||
| Maximum number of resident warps per multiprocessor | 24 | 32 | 48 | 64 | |||
| Maximum number of resident threads per multiprocessor | 768 | 1024 | 1536 | 2048 | |||
| Number of 32-bit registers per multiprocessor | 8 K | 16 K | 32 K | 64 K | |||
| Maximum number of 32-bit registers per thread | 128 | 63 | 255 | ||||
| Maximum amount of shared memory per multiprocessor | 16 KB | 48 KB | |||||
| Number of shared memory banks | 16 | 32 | |||||
| Amount of local memory per thread | 16 KB | 512 KB | |||||
| Constant memory size | 64 KB | ||||||
| Cache working set per multiprocessor for constant memory | 8 KB | ||||||
| Cache working set per multiprocessor for texture memory | Device dependent, between 6 KB and 8 KB | 12 KB | Between 12 KB and 48 KB |
||||
| Maximum width for 1D texture reference bound to a CUDA array |
8192 | 65536 | |||||
| Maximum width for 1D texture reference bound to linear memory |
227 | ||||||
| Maximum width and number of layers for a 1D layered texture reference |
8192 × 512 | 16384 × 2048 | |||||
| Maximum width and height for 2D texture reference bound to a CUDA array |
65536 × 32768 | 65536 × 65535 | |||||
| Maximum width and height for 2D texture reference bound to a linear memory |
65000 × 65000 | 65000 × 65000 | |||||
| Maximum width and height for 2D texture reference bound to a CUDA array supporting texture gather |
N/A | 16384 × 16384 | |||||
| Maximum width, height, and number of layers for a 2D layered texture reference |
8192 × 8192 × 512 | 16384 × 16384 × 2048 | |||||
| Maximum width, height and depth for a 3D texture reference bound to linear memory or a CUDA array |
2048 × 2048 × 2048 | 4096 × 4096 × 4096 | |||||
| Maximum width (and height) for a cubemap texture reference |
N/A | 16384 | |||||
| Maximum width (and height) and number of layers for a cubemap layered texture reference |
N/A | 16384 × 2046 | |||||
| Maximum number of textures that can be bound to a kernel |
128 | 256 | |||||
| Maximum width for a 1D surface reference bound to a CUDA array |
Not supported |
65536 | |||||
| Maximum width and number of layers for a 1D layered surface reference |
65536 × 2048 | ||||||
| Maximum width and height for a 2D surface reference bound to a CUDA array |
65536 × 32768 | ||||||
| Maximum width, height, and number of layers for a 2D layered surface reference |
65536 × 32768 × 2048 | ||||||
| Maximum width, height, and depth for a 3D surface reference bound to a CUDA array |
65536 × 32768 × 2048 | ||||||
| Maximum width (and height) for a cubemap surface reference bound to a CUDA array |
32768 | ||||||
| Maximum width (and height) and number of layers for a cubemap layered surface reference |
32768 × 2046 | ||||||
| Maximum number of surfaces that can be bound to a kernel |
8 | 16 | |||||
| Maximum number of instructions per kernel |
2 million | 512 million | |||||
| Architecture specifications | Compute capability (version) | |||||||
|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.5 | |
| Number of cores for integer and floating-point arithmetic functions operations | 8[17] | 32 | 48 | 192 | 192 | |||
| Number of special function units for single-precision floating-point transcendental functions | 2 | 4 | 8 | 32 | 32 | |||
| Number of texture filtering units for every texture address unit or render output unit (ROP) | 2 | 4 | 8 | 32 | 32 | |||
| Number of warp schedulers | 1 | 2 | 2 | 4 | 4 | |||
| Number of instructions issued at once by scheduler | 1 | 1 | 2[18] | 2 | 2 | |||
For more information please visit this site: http://www.geeks3d.com/20100606/gpu-computing-nvidia-cuda-compute-capability-comparative-table/ and also read Nvidia CUDA programming guide.[19]
Example[edit]
This example code in C++ loads a texture from an image into an array on the GPU:
texture<float, 2, cudaReadModeElementType> tex; void foo()
{
cudaArray* cu_array; // Allocate array
cudaChannelFormatDesc description = cudaCreateChannelDesc<float>();
cudaMallocArray(&cu_array, &description, width, height); // Copy image data to array
cudaMemcpyToArray(cu_array, image, width*height*sizeof(float), cudaMemcpyHostToDevice); // Set texture parameters (default)
tex.addressMode[0] = cudaAddressModeClamp;
tex.addressMode[1] = cudaAddressModeClamp;
tex.filterMode = cudaFilterModePoint;
tex.normalized = false; // do not normalize coordinates // Bind the array to the texture
cudaBindTextureToArray(tex, cu_array); // Run kernel
dim3 blockDim(16, 16, 1);
dim3 gridDim((width + blockDim.x - 1)/ blockDim.x, (height + blockDim.y - 1) / blockDim.y, 1);
kernel<<< gridDim, blockDim, 0 >>>(d_data, height, width); // Unbind the array from the texture
cudaUnbindTexture(tex);
} //end foo() __global__ void kernel(float* odata, int height, int width)
{
unsigned int x = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y*blockDim.y + threadIdx.y;
if (x < width && y < height) {
float c = tex2D(tex, x, y);
odata[y*width+x] = c;
}
}
Below is an example given in Python that computes the product of two arrays on the GPU. The unofficial Python language bindings can be obtained from PyCUDA.[20]
import pycuda.compiler as comp
import pycuda.driver as drv
import numpy
import pycuda.autoinit mod = comp.SourceModule("""
__global__ void multiply_them(float *dest, float *a, float *b)
{
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
""") multiply_them = mod.get_function("multiply_them") a = numpy.random.randn(400).astype(numpy.float32)
b = numpy.random.randn(400).astype(numpy.float32) dest = numpy.zeros_like(a)
multiply_them(
drv.Out(dest), drv.In(a), drv.In(b),
block=(400,1,1)) print dest-a*b
Additional Python bindings to simplify matrix multiplication operations can be found in the program pycublas.[21]
import numpy
from pycublas import CUBLASMatrix
A = CUBLASMatrix( numpy.mat([[1,2,3]],[[4,5,6]],numpy.float32) )
B = CUBLASMatrix( numpy.mat([[2,3]],[4,5],[[6,7]],numpy.float32) )
C = A*B
print C.np_mat()
Language bindings[edit]
- Fortran – FORTRAN CUDA, PGI CUDA Fortran Compiler
- Haskell – Data.Array.Accelerate
- IDL – GPULib
- Java – jCUDA, JCuda, JCublas, JCufft
- Lua – KappaCUDA
- Mathematica – CUDALink
- MATLAB – Parallel Computing Toolbox, Distributed Computing Server,[22] and 3rd party packages like Jacket.
- .NET – CUDA.NET; CUDAfy.NET .NET kernel and host code, CURAND, CUBLAS, CUFFT
- Perl – KappaCUDA, CUDA::Minimal
- Python – PyCUDA, KappaCUDA
- Ruby – KappaCUDA
Current CUDA architectures[edit]
The current generation CUDA architecture (codename: Fermi) which is standard on Nvidia's released (GeForce 400 Series [GF100] (GPU) 2010-03-27)[23] GPU is designed from the ground up to natively support more programming languages such as C++. It has significantly increased the peak double-precision floating-point performance compared to Nvidia's prior-generation Tesla GPU. It also introduced several new features[24] including:
- up to 1024 CUDA cores and 6.0 billion transistors on the GTX 590
- Nvidia Parallel DataCache technology
- Nvidia GigaThread engine
- ECC memory support
- Native support for Visual Studio
Current and future usages of CUDA architecture[edit]
- Accelerated rendering of 3D graphics
- Accelerated interconversion of video file formats
- Accelerated encryption, decryption and compression
- Distributed calculations, such as predicting the native conformation of proteins
- Medical analysis simulations, for example virtual reality based on CT and MRI scan images.
- Physical simulations, in particular in fluid dynamics.
- Distributed computing
See also[edit]
- GPGPU – general purpose computation on GPUs
- OpenCL – The cross-platform standard supported by both NVidia and AMD/ATI
- DirectCompute – Microsoft API for GPU Computing in Windows Vista and Windows 7
- BrookGPU – the Stanford University graphics group's compiler
- Vectorization (parallel computing)
- Stream processing
- rCUDA – An API for computing on remote computers
- Molecular modeling on GPU
External links[edit]
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||

NVIDIA---CUDA的更多相关文章
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程
基于NVidia开源的nvidia/cuda image,构建适用于DeepLearning的基础image. 思路就是先把常用的东西都塞进去,再装某个框架就省事儿了. 为了体验重装系统的乐趣,所以采 ...
- CentOS 7 配置OpenCL环境(安装NVIDIA cuda sdk、Cmake、Eclipse CDT)
序 最近需要在Linux下进行一个OpenCL开发的项目,现将开发环境的配置过程记录如下,方便查阅. 完整的环境配置需要以下几个部分: 安装一个OpenCL实现,基于硬件,选择NVIDIA CUDA ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 容器内安装nvidia,cuda,cudnn
/var/lib/docker/overlay2 占用很大,清理Docker占用的磁盘空间,迁移 /var/lib/docker 目录 du -hs /var/lib/docker/ 命令查看磁盘使用 ...
- Nvidia CUDA 6 Installed In Ubuntu 12.04
环境:ubuntu 12.04 (x64) 如果不能够 service lightdm stop,显示:unknown service 或者其他的 sudo /etc/init.d/lightdm r ...
- 【软件安装与环境配置】ubuntu16.04+caffe+nvidia+CUDA+cuDNN安装配置
前言 博主想使用caffe框架进行深度学习相关网络的训练和测试,刚开始做,特此记录学习过程. 环境配置方面,博主以为最容易卡壳的是GPU的NVIDIA驱动的安装和CUDA的安装,前者尝试的都要吐了,可 ...
- 联想笔记本Y7000P安装nvidia,cuda,tensorflow,pytorch
Y7000P电脑环境i7处理器,1060显卡,16g内存,win10家庭版(系统版本号1809),在联想官网升级过bios,所有驱动都是最新.(截止时间点2019年3月1日) python3.5 安装 ...
- NVIDIA CUDA Library Documentation
http://developer.download.nvidia.com/compute/cuda/4_1/rel/toolkit/docs/online/index.html 英伟达CUDA库说明文 ...
- Ubuntu16.0 GTX1660Ti 安装NVIDIA CUDA cuDNN Tensflow
主要参考这篇文章Ubuntu16.04(GTX1660ti)cuda10.0和cudnn7.6环境配置 (环境乃一生之敌!!!). 容易错的点: 安装NVIDIA驱动的时候选择run版本,不要选择de ...
- 【AI】Ubuntu NVIDIA CUDA CUDNN安装配置
https://blog.csdn.net/qq_33200967/article/details/80689543 https://blog.csdn.net/sinat_29963957/arti ...
随机推荐
- UVa 11987 并查集 Almost Union-Find
原文戳这 与以往的并查集不同,这次需要一个删除操作.如果是叶子节点还好,直接修改父亲指针就好. 但是如果要是移动根节点,指向它的所有子节点也会跟着变化. 所以要增加一个永远不会被修改的虚拟根节点,这样 ...
- 对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App)
对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App) 实验目的:对比使用Charles和Fiddler两个工具 实验对象:车易通App,易销通App 实验结果 ...
- 大数据学习——本地安装redis
下载安装包 https://github.com/MicrosoftArchive/redis 下载后解压 运行cmd 然后到redis路径 运行命令: redis-server redis.wind ...
- 大数据学习——sql练习
1. 现有如下的建表语句和数据: 建表语句 create table student(Sno int,Sname string,Sex string,Sage int,Sdept string)row ...
- 对于一棵二叉树,请设计一个算法,创建含有某一深度上所有结点的链表。 给定二叉树的根结点指针TreeNode* root,以及链表上结点的深度,请返回一个链表ListNode,代表该深度上所有结点的值,请按树上从左往右的顺序链接,保证深度不超过树的高度,树上结点的值为非负整数且不超过100000。
/* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x ...
- 【LeetCode】Combination Sum(组合总和)
这道题是LeetCode里的第39道题. 题目描述: 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组 ...
- apr的使用
APR(Apache Portable Runtime),即Apache可移植运行库,正如官网所言,APR的使命是创建和维护一套软件库,以便在不同操作系统(Windows.Linux等)底层实现的基础 ...
- 【Luogu】P1607庙会班车Fair Shuttle(线段树+贪心)
我不会做贪心题啊……贪心题啊……题啊……啊…… 我真TM菜爆了啊…… 这题就像凌乱的yyy一样,把终点排序,终点相同的按起点排序.然后维护一个查询最大值的线段树.对于一个区间[l,r],如果这个区间已 ...
- NIO Channel的学习笔记总结
摘自:http://blog.csdn.net/tsyj810883979/article/details/6876603 1.1 非阻塞模式 Java NIO非堵塞应用通常适用用在I/O读写等方 ...
- 关于Boot应用中集成Spring Security你必须了解的那些事
Spring Security Spring Security是Spring社区的一个顶级项目,也是Spring Boot官方推荐使用的Security框架.除了常规的Authentication和A ...