Hadoop 之Pig的安装的与配置之遇到的问题---待解决
1. 前提是hadoop集群已经配置完成并且可以正常启动;以下是我的配置方案:
首先配置vim /etc/hosts
192.168.1.64 xuegod64
192.168.1.65 xuegod65
192.168.1.63 xuegod63
(将配置好的文件拷贝到其他两台机器,我是在xuegod64上配置的,使用scp /etc/hosts xuegod63:/etc/进行拷贝,进行该步骤前提是已经配置好SSH免密码登录;关于SSH免密码登录在此就不再详说了)
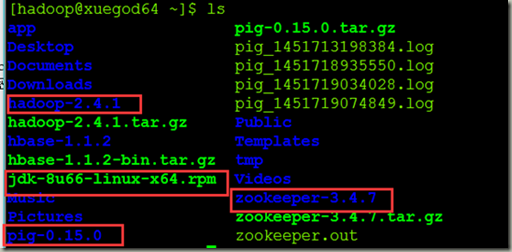
2.准备安装包如下图
[hadoop@xuegod64 ~]$ ls
hadoop-2.4.1.tar.gz
pig-0.15.0.tar.gz
jdk-8u66-linux-x64.rpm
zookeeper-3.4.7.tar.gz(可以不用)
3.配置/etc/profile
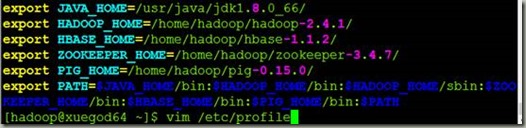
[hadoop@xuegod64 ~]$ vim /etc/profile #前提是使用root用户将编辑此文件的权限赋予hadoop用户
export JAVA_HOME=/usr/java/jdk1.8.0_66/
export HADOOP_HOME=/home/hadoop/hadoop-2.4.1/
export HBASE_HOME=/home/hadoop/hbase-1.1.2/
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.7/
export PIG_HOME=/home/hadoop/pig-0.15.0/
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOO
KEEPER_HOME/bin:$HBASE_HOME/bin:$PIG_HOME/bin:$PATH
4.检验pig是否配置成功
[hadoop@xuegod64 ~]$ pig -help
Apache Pig version 0.15.0 (r1682971)
compiled Jun 01 2015, 11:44:35
USAGE: Pig [options] [-] : Run interactively in grunt shell.
Pig [options] -e[xecute] cmd [cmd ...] : Run cmd(s).
Pig [options] [-f[ile]] file : Run cmds found in file.
。
。
。
。
5.Pig执行模式
Pig有两种执行模式,分别为:
1)本地模式(Local)本地模式下,Pig运行在单一的JVM中,可访问本地文件。该模式适用于处理小规模数据或学习之用。
运行以下命名设置为本地模式:
pig –x local
2)MapReduce模式在MapReduce模式下,Pig将查询转换为MapReduce作业提交给Hadoop(可以说群集 ,也可以说伪分布式)。应该检查当前Pig版本是否支持你当前所用的Hadoop版本。某一版本的Pig仅支持特定版本的Hadoop,你可以通过访问Pig官网获取版本支持信息。
Pig会用到HADOOP_HOME环境变量。如果该变量没有设置,Pig也可以利用自带的Hadoop库,但是这样就无法保证其自带肯定库和你实际使用的HADOOP版本是否兼容,所以建议显式设置HADOOP_HOME变量。且还需要设置如下变量:
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
Pig默认模式是mapreduce,你也可以用以下命令进行设置:
[hadoop@xuegod64 ~]$ pig -x mapreduce
(中间略)
grunt>
下一步,需要告诉Pig它所用Hadoop集群的Namenode和Jobtracker。一般情况下,正确安装配置Hadoop后,这些配置信息就已经可用了,不需要做额外的配置
6.运行Pig程序
Pig程序执行方式有三种
1) 脚本方式
直接运行包含Pig脚本的文件,比如以下命令将运行本地scripts.pig文件中的所有命令:
pig scripts.pig
2)Grunt方式
a) Grunt提供了交互式运行环境,可以在命令行编辑执行命令
b) Grund同时支持命令的历史记录,通过上下方向键访问。
c) Grund支持命令的自动补全功能。比如当你输入a = foreach b g时,按下Tab键,则命令行自动变成a = foreach b generate。你甚至可以自定义命令自动补全功能的详细方式。具体请参阅相关文档。
3) 嵌入式方式
可以在java中运行Pig程序,类似于使用JDBC运行SQL程序
(不熟悉)
6.启动集群
[hadoop@xuegod64 ~]$ start-all.sh
[hadoop@xuegod64 ~]$ jps
4722 DataNode
5062 DFSZKFailoverController
5159 ResourceManager
4905 JournalNode
5321 Jps
4618 NameNode
2428 QuorumPeerMain
5279 NodeManager
[hadoop@xuegod64 ~]$ ssh xuegod63
Last login: Sat Jan 2 23:10:21 2016 from xuegod64
[hadoop@xuegod63 ~]$ jps
2130 QuorumPeerMain
3125 Jps
2982 NodeManager
2886 JournalNode
2795 DataNode
[hadoop@xuegod64 ~]$ ssh xuegod65
Last login: Sat Jan 2 15:11:33 2016 from xuegod64
[hadoop@xuegod65 ~]$ jps
3729 Jps
2401 QuorumPeerMain
3415 JournalNode
3484 DFSZKFailoverController
3325 DataNode
3583 NodeManager
3590 SecondNameNode
7.简单示例
我们以查找最高气温为例,演示如何利用Pig统计每年的最高气温。假设数据文件内容如下(每行一个记录,tab分割)
以local模式进入pig,依次输入以下命令(注意以分号结束语句):
[hadoop@xuegod64 ~]$ pig -x local
grunt> records = load'/home/hadoop/zuigaoqiwen.txt'as(year:chararray,temperature:int);
2016-01-02 16:12:05,700 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2016-01-02 16:12:05,701 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
grunt> dump records;
(1930:28:1,)
(1930:0:1,)
(1930:22:1,)
(1930:22:1,)
(1930:22:1,)
(1930:22:1,)
(1930:28:1,)
(1930:0:1,)
(1930:0:1,)
(1930:0:1,)
(1930:11:1,)
(1930:0:1,)
。
。
。
(过程略)
grunt> describe records;
records: {year: chararray,temperature: int}
grunt> valid_records = filter records by temperature!=999;
grunt> grouped_records = group valid_records by year;
grunt> dump grouped_records;
grunt> describe grouped_records;
grouped_records: {group: chararray,valid_records: {(year: chararray,temperature: int)}}
grunt> grouped_records = group valid_records by year;
grunt> dump grouped_records;
.
.
2016-01-02 16:16:02,974 [LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.MapTask - Processing split: Number of splits :1
Total Length = 7347344
Input split[0]:
Length = 7347344
ClassName: org.apache.hadoop.mapreduce.lib.input.FileSplit
Locations:
2016-01-02 16:16:08,011 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2016-01-02 16:16:08,012 [main] INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAFeatures
2.4.1 0.15.0 hadoop 2016-01-02 16:16:02 2016-01-02 16:16:08 GROUP_BY,FILTER
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTime AvgMapTimMedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_local798558500_0002 1 1 n/a n/a n/a n/a n/a n/a n/a n/a grouped_records,records,valid_records GROUP_BY file:/tmp/temp-206603117/tmp-1002834084,
Input(s):
Successfully read 642291 records from: "/home/hadoop/zuigaoqiwen.txt"
Output(s):
Successfully stored 0 records in: "file:/tmp/temp-206603117/tmp-1002834084"
Counters:
Total records written : 0
Total bytes written : 0
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_local798558500_0002
grunt> describe grouped_records;
grouped_records: {group: chararray,valid_records: {(year: chararray,temperature: int)}}
grunt> max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature);
grunt> dump max_temperature;
(1990,23)
(1991,21)
(1992,30)
grunt> quit
2016-01-02 16:24:25,303 [main] INFO org.apache.pig.Main - Pig script completed in 14 minutes, 27 seconds and 123 milliseconds (867123 ms)
中间有些问题,搞不定:
错误提示:
2016-01-02 16:18:28,049 [main] INFO org.apache.hadoop.metrics.jvm.JvmMetrics - Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
2016-01-02 16:18:28,050 [main] INFO org.apache.hadoop.metrics.jvm.JvmMetrics - Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
2016-01-02 16:18:28,050 [main] INFO org.apache.hadoop.metrics.jvm.JvmMetrics - Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
2016-01-02 16:18:28,055 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Encountered Warning ACCESSING_NON_EXISTENT_FIELD 642291 time(s).
2016-01-02 16:18:28,055 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
2016-01-02 16:18:28,055 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2016-01-02 16:18:28,056 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2016-01-02 16:18:28,056 [main] WARN org.apache.pig.data.SchemaTupleBackend - SchemaTupleBackend has already been initialized
2016-01-02 16:18:28,246 [main] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1
2016-01-02 16:18:28,246 [main] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1
错误日志:
at java.lang.reflect.Method.invoke(Method.java:497)
Pig Stack Trace
at org.apache.pig.tools.grunt.GruntParser.processPig(Grunt
Parser.java:1082)
at org.apache.pig.tools.pigscript.parser.PigScriptParser.p
arse(PigScriptParser.java:505)
at org.apache.pig.tools.grunt.GruntParser.parseStopOnError
(GruntParser.java:230)
at org.apache.pig.tools.grunt.GruntParser.parseStopOnError
(GruntParser.java:205)
at org.apache.pig.tools.grunt.Grunt.run(Grunt.java:66)
at org.apache.pig.Main.run(Main.java:565)
at org.apache.pig.Main.main(Main.java:177)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Met
hod)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMetho
dAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Delegat
ingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
==============
Hadoop 之Pig的安装的与配置之遇到的问题---待解决的更多相关文章
- 大数据笔记(十七)——Pig的安装及环境配置、数据模型
一.Pig简介和Pig的安装配置 1.最早是由Yahoo开发,后来给了Apache 2.支持语言:PigLatin 类似SQL 3.翻译器 PigLatin ---> MapReduce(Spa ...
- [hadoop系列]Pig的安装和简单演示样例
inkfish原创,请勿商业性质转载,转载请注明来源(http://blog.csdn.net/inkfish ).(来源:http://blog.csdn.net/inkfish) Pig是Yaho ...
- my SQL下载安装,环境配置,以及密码忘记的解决,以及navicat for mysql下载,安装,测试连接
一.下载 在百度上搜索"mysql-5.6.24-winx64下载" 二.安装 选择安装路径,我的路径“C:\Soft\mysql-5.6.24-winx64” 三.环境配置 计算 ...
- Hadoop之Pig安装
Pig可以看做是Hadoop的客户端软件,使用Pig Latin语言可以实现排序.过滤.求和.分组等操作. Pig的安装步骤: 一.去Pig的官方网站下载.http://pig.apache.org/ ...
- Linux云主机安装JDK,配置hadoop的详细方式
云主机我使用的是青云的,还有好多其他品牌,比如阿里云 unitedstack 等等. 注册完青云后,会有试用券发到账户,可以利用此券试用其服务. 1 首先创建好一个主机,按照提示选择好系统,创建好一个 ...
- Hadoop HDFS安装、环境配置
hadoop安装 进入Xftp将hadoop-2.7.3.tar.gz 复制到自己的虚拟机系统下的放软件的地方,我的是/soft/software 在虚拟机系统装软件文件里,进行解压缩并重命名 进入p ...
- Hadoop 2.2.0安装和配置lzo
转自:http://www.iteblog.com/archives/992 Hadoop经常用于处理大量的数据,如果期间的输出数据.中间数据能压缩存储,对系统的I/O性能会有提升.综合考虑压缩.解压 ...
- Hadoop集群_Hadoop安装配置
1.集群部署介绍 1.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesy ...
- hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备 1. 准备4台机器.或虚拟机 4台机器的名称和IP对应如下 master:192.168.199.128 slave1:192.168.199.129 slave2:192.168.19 ...
随机推荐
- Linux VPS/server上用Crontab来实现VPS自己主动化
VPS或者server上常常会须要VPS或者server上常常会须要定时备份数据.定时运行重新启动某个服务或定时运行某个程序等等,一般在Linux使用Crontab,Windows以下是用计划任务(W ...
- pat(A)1041. Be Unique(哈希)
1.链接:点击打开链接 2.代码: #include<cstdio> #include<iostream> #include<cstring> using name ...
- Windows Server 2012 R2 安装.NET Framework 3.5报错
简单记录一下,Windows Server 2012 R2 安装.NET Framework 3.5报错,下面是解决方法 载入ISO文件Windows Server 2012 R2,而且在安装的过程中 ...
- NS3网络仿真(9): 构建以太网帧
快乐虾 http://blog.csdn.net/lights_joy/ 欢迎转载,但请保留作者信息 在NS3使用了一个叫Packet的类来表示一个数据帧,本节尝试用它构造一个以太网帧. 以下是一个典 ...
- 2016/3/16 45道MySQL 查询练习题
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- rip是典型的距离矢量动态路由协议。Ospf是链路状态型的协议
网络工程师十个常见面试问题-看准网 https://m.kanzhun.com/k-mianshiwenti/1465113.html 两者都属于IGP协议,rip是典型的距离矢量动态路由协议.Osp ...
- 滑动窗体的最大值(STL的应用+剑指offer)
滑动窗体的最大值 參与人数:767时间限制:1秒空间限制:32768K 通过比例:21.61% 最佳记录:0 ms|8552K(来自 ) 题目描写叙述 给定一个数组和滑动窗体的大小.找出全部滑动窗体里 ...
- Android 网络调试 adb tcpip 开启方法
查看ip地址:adb shell ifconfig 1.连接USB数据线,打开usb调试,使用windows的“运行”命令行方式:(此方法需配置adb环境变量,也可直接进入adb工具目录执行\andr ...
- Windows7 配置匿名Samba文件共享
1.环境 系统:Windows 7 SP1 IP:192.168.118.151 2.配置 计算机|管理|本地用户和组|用户|Guest-->去掉账户已禁用 cmd|gpedit.msc|本地计 ...
- SQLite数据库框架--FMDB简单介绍
1.什么是FMDB FMDB是iOS平台的SQLite数据库框架 FMDB以OC的方式封装了SQLite的C语言API 2.FMDB的优点 使用起来更加面向对象,省去了很多麻烦.冗余的C语言代码 对比 ...