源码阅读之LinkedList(JDK8)
inkedList概述
LinkedList是List和Deque接口的双向链表的实现。实现了所有可选列表操作,并允许包括null值。
LinkedList既然是通过双向链表去实现的,那么它可以被当作堆栈、队列或双端队列进行操作。并且其顺序访问非常高效,而随机访问效率比较低。
注意,此实现不是同步的。 如果多个线程同时访问一个LinkedList实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步。这通常是通过同步那些用来封装列表的 对象来实现的。但如果没有这样的对象存在,则该列表需要运用{@link Collections#synchronizedList Collections.synchronizedList}来进行“包装”,该方法最好是在创建列表对象时完成,为了避免对列表进行突发的非同步操作。
List list = Collections.synchronizedList(new LinkedList(...));
类中的iterator()方法和listIterator()方法返回的iterators迭代器是fail-fast的:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
LinkedList的源码阅读
- 底层结构
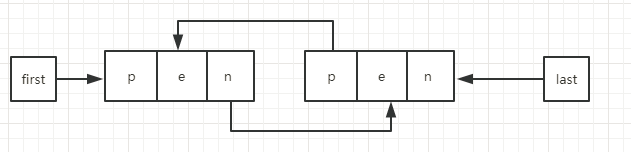
节点Node结构:
private static class Node<E> {
E item; // 当前节点所包含的值
Node<E> next; // 下一个节点
Node<E> prev; // 上一个节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList结构:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//LinkedList包含的元素个数
transient int size = ; /**
* Pointer to first node. 首节点
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/ 首节点和尾节点要么同时为null, 不可能一个为null,一个不为null
transient Node<E> first; /**
* Pointer to last node. 尾节点
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
- 构造函数
LinkedList提供了两种种方式的构造器,构造一个空列表、以及构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回的顺序排列的。
public LinkedList() {
}
// 构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回的顺序排列的
public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
- 添加元素
LinkedList提供了头插入addFirst(E e)、尾插入addLast(E e)、add(E e)、addAll(Collection<? extends E> c)、addAll(int index, Collection<? extends E> c)、add(int index, E element)这些添加元素的方法。
// 添加
public boolean add(E e) {
// 在链表尾部插入
linkLast(e);
return true;
}
// 插入
public void add(int index, E element) {
// 插入范围检查
checkPositionIndex(index);
if (index == size)
// 在链表尾部添加
linkLast(element);
else
// 在链表中间插入
linkBefore(element, node(index));
}
// 头插入
public void addFirst(E e) {
linkFirst(e);
}
// 尾插入
public void addLast(E e) {
linkLast(e);
}
/**
* 按照指定collection的迭代器所返回的元素顺序,将该collection中的所有元素添加到此链表的尾部
* 如果指定的集合添加到链表的尾部的过程中,集合被修改,则该插入过程的后果是不确定的。
* 一般这种情况发生在指定的集合为该链表的一部分,且其非空。
* @throws NullPointerException 指定集合为null
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
//从指定的位置开始,将指定collection中的所有元素插入到此链表中,新元素的顺序为指定collection的迭代器所返回的元素顺序
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); Object[] a = c.toArray();
int numNew = a.length;
if (numNew == )
return false; Node<E> pred, succ; //succ指向当前需要插入节点的位置,pred指向其前一个节点
if (index == size) {//说明在列表尾部插入集合元素
succ = null;
pred = last;
} else {
succ = node(index); //得到索引index所对应的节点
pred = succ.prev;
}
//指定collection中的所有元素依次插入到此链表中指定位置的过程
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//将元素值e,前继节点pred“封装”为一个新节点newNode
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null) //如果原链表为null,则新插入的节点作为链表首节点
first = newNode;
else
pred.next = newNode;
pred = newNode; //pred指针向后移动,指向下一个需插入节点位置的前一个节点
}
//集合元素插入完成后,与原链表index位置后面的子链表链接起来
if (succ == null) { //说明之前是在列表尾部插入的集合元素
last = pred; //pred指向的是最后插入的那个节点
} else {
pred.next = succ;
succ.prev = pred;
} size += numNew;
modCount++;
return true;
}
细读上面的代码linkLast,linkBefore,linkFirst,linkLast
1. linkLast
// 尾插入,即将节点值为e的节点设置为链表的尾节点
void linkLast(E e) {
// 获取当前尾结点引用
final Node<E> l = last;
//构建一个prev值为l,节点值为e,next值为null的新节点newNode
final Node<E> newNode = new Node<>(l, e, null);
//将newNode作为尾节点
last = newNode;
//如果原尾节点为null,即原链表为null,则链表首节点也设置为newNode
if (l == null)
first = newNode;
else //否则,原尾节点的next设置为newNode
l.next = newNode;
size++;
modCount++;
}
当last==null时, fisrt 和 last 都是同一个node,该弄得的p和n都为null,不指向任何节点

当last != null时,第一步,构建newNode的时候把newNode的p指向了原先的lastNode,第二步,把newNode复制给lastNode,第三步,把原先的lastNode的n指向newNode

2. linkBefore
//中间插入,在非空节点succ之前插入节点值e
void linkBefore(E e, Node<E> succ) {
//获取给定结点的上一个结点引用
final Node<E> pred = succ.prev;
//创建新结点, 新结点的上一个结点引用指向给定结点的上一个结点
//新结点的下一个结点的引用指向给定的结点
final Node<E> newNode = new Node<>(pred, e, succ);
//将给定结点的上一个结点引用指向新结点
succ.prev = newNode;
//如果给定结点的上一个结点为空, 表明给定结点为头结点 if (pred == null)
//将头结点引用指向新结点
first = newNode;
else
//否则, 将给定结点的上一个结点的下一个结点引用指向新结点
pred.next = newNode;
/集合元素个数加一
size++;
//修改次数加一
modCount++;
}
当succ.pred != null时,开始的数据结构如下:
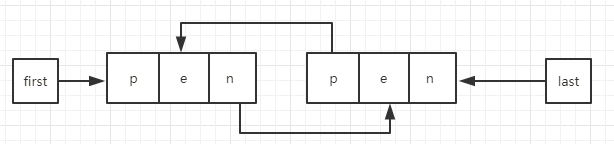
第一步,新构建一个newNode,把newNode的p指向succ的前一个节点,把newNode的n指向succ。
第二步,将succ节点的p指向 从succ.prev转移到newNode上。
第三步,将succ的前一个节点的n指向 从succ转移到newNode上。

当succ.pred == null时,和上面差不多,只是第三步的时候直接把newNode设置为首节点。
3. linkFirst
//头插入,即将节点值为e的节点设置为链表首节点
private void linkFirst(E e) {
final Node<E> f = first;
//构建一个prev值为null,节点值为e,next值为f的新节点newNode
final Node<E> newNode = new Node<>(null, e, f);
//将newNode作为首节点
first = newNode;
//如果原首节点为null,即原链表为null,则链表尾节点也设置为newNode
if (f == null)
last = newNode;
else //否则,原首节点的prev设置为newNode
f.prev = newNode;
size++;
modCount++;
}
linkLast
// 尾插入,即将节点值为e的节点设置为链表的尾节点
void linkLast(E e) {
// 获取当前尾结点引用
final Node<E> l = last;
//构建一个prev值为l,节点值为e,next值为null的新节点newNode
final Node<E> newNode = new Node<>(l, e, null);
//将newNode作为尾节点
last = newNode;
//如果原尾节点为null,即原链表为null,则链表首节点也设置为newNode
if (l == null)
first = newNode;
else //否则,原尾节点的next设置为newNode
l.next = newNode;
size++;
modCount++;
}
- 删除元素
LinkedList提供了头删除removeFirst()、尾删除removeLast()、remove(int index)、remove(Object o)、clear()这些删除元素的方法。
// 删除首结点,返回存储的元素
public E removeFirst() {
// 获取首结点引用
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
// 删除首结点,返回存储的元素
return unlinkFirst(f);
}
// 删除尾结点,返回存储的元素
public E removeLast() {
// 获取尾结点引用
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
// 删除尾结点,返回存储的元素
return unlinkLast(l);
}
//删除指定元素,默认从first节点开始,删除第一次出现的那个元素
public boolean remove(Object o) {
//会根据是否为null分开处理。若值不是null,会用到对象的equals()方法
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 删除指定位置的元素,返回之前元素
public E remove(int index) {
// 判断指定位置是否合法
checkElementIndex(index);
// 删除指定位置的结点,返回之前元素
return unlink(node(index));
}
// 删除所有元素
public void clear() {
//遍历链表,删除所有结点,方便gc回收垃圾
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
// 首尾结点置空
first = last = null;
// 元素数量置0
size = ;
modCount++;
}
细读remove里面的代码unlink,unlinkFirst,unlinkLast
1. unlink
// 删除指定非空结点,返回存储的元素
E unlink(Node<E> x) {
// assert x != null;
// 获取指定非空结点存储的元素
final E element = x.item;
// 获取指定非空结点的后一个结点
final Node<E> next = x.next;
// 获取指定非空结点的前一个结点
final Node<E> prev = x.prev;
// 如果前一个节点为空,则说明指定节点为首节点,只需将指定节点的后一个节点设置为首节点即可
if (prev == null) {
first = next;
} else {
// 将前一个节点的next指向指定节点的后一个节点,并把指定节点的prev清空
prev.next = next;
x.prev = null;
}
// 如果后一个节点为空,说明指定节点为尾节点,只需将指定节点的前一个节点设置为尾节点即可
if (next == null) {
last = prev;
} else {
// 将后一个节点的prev指向指定节点的前一个节点,并把指定节点的next清空
next.prev = prev;
x.next = null;
}
// 指定节点的存储元素清空
x.item = null;
// 元素数量-1
size--;
modCount++;
return element;
}
初始状态:

第一步,将指定节点的前一个节点的next指向指定节点的后一个节点,然后将指定节点的prev清空。
第二步,将指定节点的后一个接的的prev指向指定节点的前一个节点,然后将指定节点的next清空。
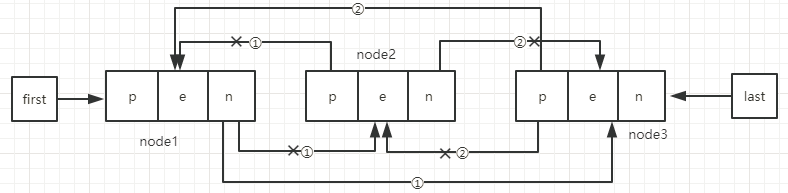
最后的效果

2. unlinkFirst
// 删除首结点,返回存储的元素,内部使用
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
//获取首结点存储的元素
final E element = f.item;
// 获取首结点的后一个结点
final Node<E> next = f.next;
// 删除首结点
f.item = null;
f.next = null; // help GC
// 原来首结点的后一个结点设为首结点
first = next;
// 如果首节点的后一个节点为空,说明容器里只有一个节点,所以删除了首节点,容器为空,首节点和尾节点都设置为null
if (next == null)
last = null;
else
// 把新的首节点的prev清空
next.prev = null;
size--;
modCount++;
return element;
}
3. unlinkLast
// 删除尾结点,返回存储的元素,内部使用
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
// 获取尾结点存储的元素
final E element = l.item;
// 获取尾结点的前一个结点
final Node<E> prev = l.prev;
// 删除尾结点
l.item = null;
l.prev = null; // help GC
// 原来尾结点的前一个结点设为尾结点
last = prev;
// 如果尾节点的前一个节点为空,则说明容器里只有一个元素,所以删除后,把首节点和尾节点都设置为空
if (prev == null)
first = null;
else
// 把新的尾节点的next清空
prev.next = null;
size--;
modCount++;
return element;
}
- 修改元素
// 修改指定位置的元素,返回之前元素
public E set(int index, E element) {
// 判断指定位置是否合法
checkElementIndex(index);
// 获取指定位置的结点
Node<E> x = node(index);
// 获取该结点存储的元素
E oldVal = x.item;
// 修改该结点存储的元素
x.item = element;
// 返回该结点存储的之前的元素
return oldVal;
}
- 查询元素
LinkedList提供了getFirst()、getLast()、contains(Object o)、get(int index)、indexOf(Object o)、lastIndexOf(Object o)这些查找元素的方法。
//返回列表首节点元素值
public E getFirst() {
final Node<E> f = first;
if (f == null) //如果首节点为null
throw new NoSuchElementException();
return f.item;
} //返回列表尾节点元素值
public E getLast() {
final Node<E> l = last;
if (l == null) //如果尾节点为null
throw new NoSuchElementException();
return l.item;
} //判断列表中是否包含有元素值o,返回true当列表中至少存在一个元素值e,使得(o==null?e==null:o.equals(e))
public boolean contains(Object o) {
return indexOf(o) != -;
} //返回指定索引处的元素值
public E get(int index) {
checkElementIndex(index); //index >= 0 && index < size
return node(index).item; //node(index)返回指定索引位置index处的节点
}
//正向查找,返回LinkedList中元素值Object o第一次出现的位置,如果元素不存在,则返回-1
public int indexOf(Object o) {
int index = ;
//由于LinkedList中允许存放null,因此下面通过两种情况来分别处理
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) { //顺序向后
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -;
} //逆向查找,返回LinkedList中元素值Object o最后一次出现的位置,如果元素不存在,则返回-1
public int lastIndexOf(Object o) {
int index = size;
//由于LinkedList中允许存放null,因此下面通过两种情况来分别处理
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) { //逆向向前
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -;
}
细看里面的一个node()方法,通过下标定位时先判断是在链表的上半部分还是下半部分,如果是在上半部分就从头开始找起,如果是下半部分就从尾开始找起,因此通过下标的查找和修改操作的时间复杂度是O(n/2)。
//返回指定索引位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
//折半思想,当index < size/2时,从列表首节点向后查找
if (index < (size >> )) {
Node<E> x = first;
for (int i = ; i < index; i++)
x = x.next;
return x;
} else { //当index >= size/2时,从列表尾节点向前查找
Node<E> x = last;
for (int i = size - ; i > index; i--)
x = x.prev;
return x;
}
}
- Fail-Fast机制
LinkedList也采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
- 遍历方式
LinkedList不提倡运用随机访问的方式进行元素遍历。
1)通过迭代器Iterator遍历:
Iterator iter = list.iterator();
while (iter.hasNext())
{
System.out.println(iter.next());
}
2)通过迭代器ListIterator遍历:
ListIterator<String> lIter = list.listIterator();
//顺向遍历
while(lIter.hasNext()){
System.out.println(lIter.next());
}
//逆向遍历
while(lIter.hasPrevious()){
System.out.println(lIter.previous());
}
3)foreach循环遍历
for(String str:list)
{
System.out.println(str);
}
源码阅读之LinkedList(JDK8)的更多相关文章
- 源码阅读之HashMap(JDK8)
概述 HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的. HashMap最多只允许一条记录的键为null,允许多条记录 ...
- jdk源码阅读笔记-LinkedList
一.LinkedList概述 LinkedList的底层数据结构为双向链表结构,与ArrayList相同的是LinkedList也可以存储相同或null的元素.相对于ArrayList来说,Linke ...
- java1.7集合源码阅读:LinkedList
先看看类定义: public class LinkedList<E> extends AbstractSequentialList<E> implements List< ...
- OpenJDK 源码阅读之 LinkedList
概要 类继承关系 java.lang.Object java.util.AbstractCollection<E> java.util.AbstractList<E> java ...
- 【JDK1.8】JDK1.8集合源码阅读——LinkedList
一.前言 这次我们来看一下常见的List中的第二个--LinkedList,在前面分析ArrayList的时候,我们提到,LinkedList是链表的结构,其实它跟我们在分析map的时候讲到的Link ...
- 【源码阅读】Java集合之二 - LinkedList源码深度解读
Java 源码阅读的第一步是Collection框架源码,这也是面试基础中的基础: 针对Collection的源码阅读写一个系列的文章; 本文是第二篇LinkedList. ---@pdai JDK版 ...
- 源码阅读之ArrayList(JDK8)
ArrayList概述 ArrayList是一个的可变数组的实现,实现了所有可选列表操作,并允许包括 null 在内的所有元素.每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组 ...
- java8 ArrayList源码阅读
转载自 java8 ArrayList源码阅读 本文基于jdk1.8 JavaCollection库中有三类:List,Queue,Set 其中List,有三个子实现类:ArrayList,Vecto ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
随机推荐
- Linux学习笔记01
1.Linux不靠扩展名区分文件类型2.存储设备必须先挂载才能使用3.Windows下的程序不能直接在Linux中安装和运行 一.服务器的管理预配置Linux的目录的作用:/bin/存放系统命令的目录 ...
- Happy Three Friends
Happy Three Friends Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Othe ...
- hihoCoder#1077 RMQ问题再临-线段树
原题地址 终于做到线段树的题了,因为建树.更新.查询都是递归操作,所以其实挺好写的. 用数组存的树,记得MAX_NODE开成两倍叶节点数大小,否则RE啊..不要问我是怎么知道的. 代码: #inclu ...
- POJ 3281_Dining
题意: FJ准备了F种食物和D种饮料,每头牛都有喜欢的食物和饮料,并且每头牛都只能分配一种食物和饮料.问如何分配使得同时得到喜欢的食物和饮料的牛数量最多. 分析: 首先想到将牛与其对应的食物和饮料匹配 ...
- POJ 3320_Jessica's Reading Problem
题意: 每页书都对应一个知识点,问最少看连续的多少页,才能把所有知识点都看完? 分析: <挑战程序设计竞赛>介绍的尺取法,反复推进区间的开头和结尾,来求取满足条件的最小区间,先确定好一个满 ...
- Java内存分配与参数传递
JAVA中方法的参数传递方式只有一种:值传递. JAVA内存分配: 1.栈:存放 基本类型的数据.对象的引用(类似于C语言中的指针) 2.堆:存放用new产生的数据 3.静态域:存放在对象中用stat ...
- day1--大数据概念,hadoop介绍,hdfs整体运行机制
1.什么是大数据 基本概念 在互联网技术发展到现今阶段,大量日常.工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用 ...
- gcc 5.2.0 编译安装笔记-20151110
**转载请注明出处** by.haunying3 系统版本号 CentOS-6.6-x86_64-minimal 编译器 gcc-4.4.7通过yum安装 rpm -qa | grep gcc gcc ...
- SQLServer时间分段查询
统计连续时间段数据 if OBJECT_ID(N'Test',N'U') is not null drop table Test go create table Test( pscode decima ...
- powerShell赋权限
1.给网站赋权限 Set-SPUser –Identity “用户名” –AddPermissionLevel “参与讨论” –web “http://url” 2.给列表赋权限 $web = Get ...