张高兴的大模型开发实战:(三)使用 LangGraph 为对话添加历史记录
在构建聊天机器人时,对话历史记录是提升用户体验的核心功能之一,用户希望机器人能够记住之前的对话内容,从而避免重复提问。LangGraph 是 LangChain 生态中一个工具,通过将应用逻辑组织成有向图(Graph)的形式,可以轻松实现对话历史的管理和复杂的对话流程。本文将通过一个示例,展示如何使用 LangGraph 实现这一功能。
在上一篇博客中提到,链(Chain)在 LangChain 中是一种基本的构建块,用于将多个 LLM 调用和工具调用链接在一起。然而,链在处理复杂、动态的对话流程时存在一些局限性,例如,链通常是线性的,这种线性结构只能按照预定义的顺序执行,限制了在对话中进行动态路由和条件分支的能力。LangGraph 的设计目标是提供一个更灵活、更强大的框架来构建复杂的智能体应用。
| LangGraph | LangChain | |
|---|---|---|
| 核心设计 | 循环图结构:支持条件分支、循环和反馈机制,适合复杂多步骤任务。 | 线性流程(DAG):以链式结构为主,适合线性任务(如文档检索、文本生成)。 |
| 控制能力 | 高度可控:通过节点(Node)和边(Edge)精细控制流程,支持条件逻辑和动态修改。 | 中等可控:依赖链式编排,灵活性较低,难以处理复杂循环或动态分支。 |
| 持久化与状态管理 | 内置持久化:支持状态检查点(Checkpoints),可中断/恢复任务,适合长期任务。 | 基础记忆功能:依赖对话历史记录,但无法持久化复杂状态或跨会话共享。 |
| 人在环(Human-in-the-Loop) | 深度支持:可在任意节点插入人工审核、干预,适合医疗、金融等需人工决策的场景。 | 弱支持:需手动集成人工干预逻辑,流程中断后难以恢复。 |
| 多代理(Multi-Agent) | 原生支持:通过共享状态实现多Agent协作,适合复杂任务拆分与协同。 | 较弱:需手动协调多个链,难以实现动态任务分配。 |
| 错误处理 | 容错性强:支持失败节点跳转或重试,流程可恢复。 | 基础重试:依赖单链重试,无法处理复杂流程中的错误传播。 |
| 适用场景 | 复杂多步骤任务、需人工干预的场景(如医疗诊断)、多Agent协作系统、长期任务(如持续对话) | 线性任务(文档检索、文本生成)、快速原型开发、简单对话系统 |
| 开发复杂度 | 中等:需定义节点、边和状态,但提供了灵活的编排能力。 | 低:开箱即用的链式结构,适合快速开发。 |
基础概念
LangGraph 的核心是 State Graph,它通过状态(State)、节点(Node)和边(Edge)的组合,定义对话的流程和逻辑。每个状态可以保存对话的上下文(如历史消息、总结等),节点定义了在不同状态下如何处理输入和生成输出,边定义了处理流程。
- State(状态)
用于存储对话中的临时数据,例如用户消息、模型响应、总结内容等。例如class State(MessagesState): messages: str表示一个状态,其中messages字段用于存储对话的具体信息。 - Node(节点)
定义了对话流程中的具体操作,通常是具体的函数,例如调用模型、判断是否需要总结、生成总结等。 - Edge(边)
用于连接不同的节点,定义了节点之间的关系和流程。边可以包含条件逻辑、循环、分支等,用于控制对话流程的走向。
我们来看一个最简单的示例,下图是一个 LangGraph 实现的聊天机器人。
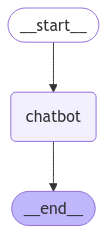
起始节点为 __start__,结束节点为 __end__,chatbot 表示调用大模型处理对话。__start__ 节点存储了应用的 State 数据。节点之间带箭头的线段表示边,实线代表普通边 →,虚线代表条件边 ⇢,条件边根据当前的具体条件而选择哪一条边执行,选择不同的边,则到达的节点不同。
环境搭建与配置
在上一篇博客创建的 Python 虚拟环境中执行以下命令,安装需要的包:
pip install langgraph langgraph-checkpoint-postgres psycopg[binary,pool]
将对话历史存储至内存
在开始之前,先构建一个图,实现一个最简单的聊天机器人。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_ollama import ChatOllama
class State(TypedDict):
"""存储对话状态信息"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
"""调用模型处理对话"""
return {"messages": [llm.invoke(state["messages"])]}
llm = ChatOllama(model="qwen2.5:1.5b")
# 创建图
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot) # 添加节点
graph_builder.add_edge(START, "chatbot") # 添加边
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
使用下面的代码输出图的结构:
png = graph.get_graph().draw_mermaid_png()
with open("chatbot.png", "wb") as f:
f.write(png)
接下来,使用 graph.stream() 方法执行图,即可开始对话。
events = graph.stream({"messages": [{"role": "user", "content": "你可以做些什么?"}]})
for event in events:
last_event = event
print("AI: ", last_event["messages"][-1].content)
下面使用 MemorySaver 将对话历史存储在内存中。
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
# 创建图
# ...
graph = graph_builder.compile(checkpointer=checkpointer)
在对话时要记录对话历史,还需要在 graph.stream() 方法中传入 config 参数,thread_id 用于标识对话的唯一性,不同的对话 thread_id 不同。
import uuid
config = {"configurable": {"thread_id": uuid.uuid4().hex}}
events = graph.stream({"messages": [{"role": "user", "content": "你好,我的名字是张三"}]}, config)
最后,我们将对话的代码封装成 stream_graph_updates() 方法,通过对话检测一下历史信息是否被正确保存。
def stream_graph_updates(user_input: str, config: dict):
"""对话"""
events = graph.stream({"messages": [{"role": "user", "content": user_input}]}, config, stream_mode="values")
for event in events:
last_event = event
print("AI: ", last_event["messages"][-1].content)
if __name__ == "__main__":
config = {"configurable": {"thread_id": uuid.uuid4().hex}}
while True:
user_input = input("User: ") # 用户输入问题进行对话
if user_input.lower() in ["exit", "quit"]:
break
stream_graph_updates(user_input, config)
print("\nHistory: ") # 输出对话历史
for message in graph.get_state(config).values["messages"]:
if isinstance(message, AIMessage):
prefix = "AI"
else:
prefix = "User"
print(f"{prefix}: {message.content}")
User: 你好,我的名字是张三
AI: 你好!很高兴认识你。有什么可以帮忙的吗?
User: 我叫什么名字
AI: 你的名字确实是“张三”。很高兴认识你!有什么问题或需要帮助的地方吗?
将对话历史存储至 PostgreSQL
对话历史存储至内存中,当应用关闭时,对话历史也会消失,有时无法满足持久化的需求。LangGraph 提供了一些数据库持久化方式,支持的数据库有 PostgreSQL、MongoDB、Redis。下面使用 PostgreSQL 数据库为例。在开始之前,执行以下命令创建一个 PostgreSQL 数据库:
psql -U postgres -c "CREATE DATABASE llm"
接着,在代码中替换 MemorySaver 为 PostgresSaver,连接并初始化数据库:
from psycopg import Connection
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:YOUR_PASSW0RD@localhost:5432/llm" # 记得替换数据库密码
conn = Connection.connect(DB_URI) # 连接数据库
checkpointer = PostgresSaver(conn)
checkpointer.setup() # 初始化数据库
使用数据库管理工具查看数据库,可以看到 LangGraph 在数据库初始化时帮我们创建了四张表:checkpoint、checkpoint_blobs、checkpoint_writes、checkpoint_migrations。

完整的程序代码如下:
import uuid
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_ollama import ChatOllama
from langchain_core.messages import AIMessage, HumanMessage
from psycopg import Connection
from langgraph.checkpoint.postgres import PostgresSaver
class State(TypedDict):
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
DB_URI = "postgresql://postgres:%40Passw0rd@localhost:5432/llm"
llm = ChatOllama(model="qwen2.5:1.5b")
conn = Connection.connect(DB_URI)
checkpointer = PostgresSaver(conn)
checkpointer.setup()
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile(checkpointer=checkpointer)
def stream_graph_updates(user_input: str, config: dict):
events = graph.stream({"messages": [{"role": "user", "content": user_input}]}, config, stream_mode="values")
for event in events:
last_event = event
print("AI: ", last_event["messages"][-1].content)
if __name__ == "__main__":
config = {"configurable": {"thread_id": uuid.uuid4().hex}}
while True:
user_input = input("User: ")
if user_input.lower() in ["exit", "quit"]:
break
stream_graph_updates(user_input, config)
print("\nHistory: ")
for message in checkpointer.get(config)["channel_values"]["messages"]:
if isinstance(message, AIMessage):
prefix = "AI"
else:
prefix = "User"
print(f"{prefix}: {message.content}")
conn.close()
张高兴的大模型开发实战:(三)使用 LangGraph 为对话添加历史记录的更多相关文章
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发实战:Storm流计算开发
Storm是一个分布式.高容错.高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义.Hadoop提供了Map和Reduce原语.同样,Storm也对数据的实时处理提供了简单 ...
- 大数据开发实战:MapReduce内部原理实践
下面结合具体的例子详述MapReduce的工作原理和过程. 以统计一个大文件中各个单词的出现次数为例来讲述,假设本文用到输入文件有以下两个: 文件1: big data offline data on ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 大数据开发实战:Hadoop数据仓库开发实战
1.Hadoop数据仓库架构设计 如上图. ODS(Operation Data Store)层:ODS层通常也被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
随机推荐
- 开源即时通讯IM框架MobileIMSDK的微信小程序端开发快速入门
一.理论知识准备 您需要对微信小程序开发有所了解: 1)真正零基础入门学习笔记系列 2)从零开始的微信小程序入门教程 3)最全教程:微信小程序开发入门详解 您需要对WebSocket技术有所了解: 1 ...
- 第三章 (Nginx+Lua)Redis/SSDB安装与使用
目前对于互联网公司不使用Redis的很少,Redis不仅仅可以作为key-value缓存,而且提供了丰富的数据结果如set.list.map等,可以实现很多复杂的功能:但是Redis本身主要用作内存缓 ...
- pytest基础
pytest断言 1. == 直接对两端的值进行判断是否一致 1==1 2.assert in 判断值是否在正确范围 def test_jia(self): a='hello' b='a' ass ...
- 九集代码深度解析SpringBoot原理:笔记整理
手动注册Tomcat中的servlet容器 子父容器概念
- Prometheus修改默认数据存储时间
Prometheus修改默认数据存储时间 Prometheus 的数据存储时间是通过命令行参数 --storage.tsdb.retention.time 来设置的.这个参数指定了 Prometheu ...
- [记录点滴]编译安装luarocks、luacheck、luautf8
[记录点滴]编译安装luarocks.luacheck.luautf8 0x00 摘要 记录一次安装luarocks&第三方库的过程. 0x01 luarocks 如今每个语言体系中都有一个包 ...
- LINUX手动安装万里开源单实例
下载安装包 https://gitee.com/GreatSQL/GreatSQL/releases/ 关闭 selinux 和防火墙 #关闭selinux $ setenforce=0 $ sed ...
- Core WebAPI配置Swagger
1.配置Swagger: Swagger是一套接口文档的规范,通过这套规范,你只需要按照它的规范去定义接口以及接口相关的信息.再通过Swagger衍生出来的一系列项目和工具,就可以做到生成各种格式的接 ...
- [PA2021] Od deski do deski 题解
好题好题,难者不会会者不难,我是前者. 实际上加入就可以合法的数是很好计算的.考虑现在所有前缀合法串后的字符实际上都可以满足条件. 容易想到根据是否合法设置状态.设 \(f_{i,j}/g_{i,j} ...
- [AHOI2013] 差异 题解
后缀自动机维护子串公共后缀方便一点,所以直接倒序插入字符串即可. 我们给所有前缀打上标记,然后跑树形 \(dp\),设 \(sum_i\) 表示第 \(i\) 个点的子树内有多少个前缀,\(ans\) ...