Flume架构与源码分析-整体架构
最近在学习Flume源码,所以想写一份Flume源码学习的笔记供需要的朋友一起学习参考。
1、Flume介绍
Flume是cloudera公司开源的一款分布式、可靠地进行大量日志数据采集、聚合和并转移到存储中;通过事务机制提供了可靠的消息传输支持,自带负载均衡机制来支撑水平扩展;并且提供了一些默认组件供直接使用。
Flume目前常见的应用场景:日志--->Flume--->实时计算(如Kafka+Storm) 、日志--->Flume--->离线计算(如HDFS、HBase)、日志--->Flume--->ElasticSearch。
2、整体架构
Flume主要分为三个组件:Source、Channel、Sink;数据流如下图所示:
1、Source负责日志流入,比如从文件、网络、Kafka等数据源流入数据,数据流入的方式有两种轮训拉取和事件驱动;
2、Channel负责数据聚合/暂存,比如暂存到内存、本地文件、数据库、Kafka等,日志数据不会在管道停留很长时间,很快会被Sink消费掉;
3、Sink负责数据转移到存储,比如从Channel拿到日志后直接存储到HDFS、HBase、Kafka、ElasticSearch等,然后再有如Hadoop、Storm、ElasticSearch之类的进行数据分析或查询。
一个Agent会同时存在这三个组件,Source和Sink都是异步执行的,相互之间不会影响。
假设我们有采集并索引Nginx访问日志,我们可以按照如下方式部署:
1、Agent和Web Server是部署在同一台机器;
2、Source使用ExecSource并使用tail命令采集日志;
3、Channel使用MemoryChannel,因为日志数据丢点也不算什么大问题;
4、Sink使用ElasticSearchSink写入到ElasticSearch,此处可以配置多个ElasticSearch服务器IP:PORT列表以便提升处理能力。
以上介绍了日志是如何流的,对于复杂的日志采集,我们需要对Source日志进行过滤、写到多个Channel、对Sink进行失败处理/负载均衡等处理,这些Flume默认都提供了支持:
1、Source采集的日志会传入ChannelProcessor组件,其首先通过Interceptor进行日志过滤,如果接触过Servlet的话这个概念是类似的,可以参考《Servlet3.1规范翻译——过滤器》 ;过滤器可以过滤掉日志,也可以修改日志内容;
2、过滤完成后接下来会交给ChannelSelector进行处理,默认提供了两种选择器:复制或多路复用选择器;复制即把一个日志复制到多个Channel;而多路复用会根据配置的选择器条件,把符合条件的路由到相应的Channel;在写多个Channel时可能存在存在失败的情况,对于失败的处理有两种:稍后重试或者忽略。重试一般采用指数级时间进行重试。
我们之前说过Source生产日志给Channel、Sink从Channel消费日志;它俩完全是异步的,因此Sink只需要监听自己关系的Channel变化即可。
到此我们可以对Source日志进行过滤/修改,把一个消息复制/路由到多个Channel,对于Sink的话也应该存在写失败的情况,Flume默认提供了如下策略:
默认策略就是一个Sink,失败了则这个事务就失败了,会稍后重试。
Flume还提供了故障转移策略:
Failover策略是给多个Sink定义优先级,假设其中一个失败了,则路由到下一个优先级的Sink;Sink只要抛出一次异常就会被认为是失败了,则从存活Sink中移除,然后指数级时间等待重试,默认是等待1s开始重试,最大等待重试时间是30s。
Flume也提供了负载均衡策略:
负载均衡算法默认提供了两种:轮训和随机;其通过抽象一个类似ChannelSelector的SinkSelector进行选择,失败补偿机制和Failover中的算法类似,但是默认是关闭失败补偿的,需要配置backoff参数为true开启。
到此Flume涉及的一些核心组件就介绍完了,对于Source和Sink如何异步、Channel提供的事务机制等我们后续分析组件时再讲。
假设我们需要采集非常多的客户端日志并对他们进行一些缓冲或集中的处理,就可以部署一个聚合层,整体架构类似于如下:
1、首先是日志采集层,该层的Agent和应用部署在同一台机器上,负责采集如Nginx访问日志;然后通过RPC将日志流入到收集/聚合层;在这一层应该快速的采集到日志然后流入到收集/聚合层;
2、收集/聚合层进行日志的收集或聚合,并且可以进行容错处理,如故障转移或负载均衡,以提升可靠性;另外可以在该层开启文件Channel,做数据缓冲区;
3、收集/聚合层对数据进行过滤或修改然后进行存储或处理;比如存储到HDFS,或者流入Kafka然后通过Storm对数据进行实时处理。
到此从Flume核心组件到一般的部署架构我们就大体了解了,而涉及的一些实现细节在接下来的部分进行详细介绍。
首先所有核心组件都会实现org.apache.flume.lifecycle.LifecycleAware接口:
- public interface LifecycleAware {
- public void start();
- public void stop();
- public LifecycleState getLifecycleState();
- }
start方法在整个Flume启动时或者初始化组件时都会调用start方法进行组件初始化,Flume组件出现异常停止时会调用stop,getLifecycleState返回组件的生命周期状态,有IDLE, START, STOP, ERROR四个状态。
如果开发的组件需要配置,如设置一些属性;可以实现org.apache.flume.conf.Configurable接口:
- public interface Configurable {
- public void configure(Context context);
- }
Flume在启动组件之前会调用configure来初始化组件一些配置。
1、Source
Source用于采集日志数据,有两种实现方式:轮训拉取和事件驱动机制;Source接口如下:
- public interface Source extends LifecycleAware, NamedComponent {
- public void setChannelProcessor(ChannelProcessor channelProcessor);
- public ChannelProcessor getChannelProcessor();
- }
Source接口首先继承了LifecycleAware接口,然后只提供了ChannelProcessor的setter和getter接口,也就是说它的的所有逻辑的实现应该在LifecycleAware接口的start和stop中实现;ChannelProcessor之前介绍过用来进行日志流的过滤和Channel的选择及调度。
而Source是通过SourceFactory工厂创建,默认提供了DefaultSourceFactory,其首先通过Enum类型org.apache.flume.conf.source.SourceType查找默认实现,如exec,则找到org.apache.flume.source.ExecSource实现,如果找不到直接Class.forName(className)创建。
Source提供了两种机制: PollableSource(轮训拉取)和EventDrivenSource(事件驱动):
PollableSource默认提供了如下实现:
比如JMSSource实现使用javax.jms.MessageConsumer.receive(pollTimeout)主动去拉取消息。
EventDrivenSource默认提供了如下实现:
比如NetcatSource、HttpSource就是事件驱动,即被动等待;比如HttpSource就是内部启动了一个内嵌的Jetty启动了一个Servlet容器,通过FlumeHTTPServlet去接收消息。
Flume提供了SourceRunner用来启动Source的流转:
- public class EventDrivenSourceRunner extends SourceRunner {
- private LifecycleState lifecycleState;
- public EventDrivenSourceRunner() {
- lifecycleState = LifecycleState.IDLE; //启动之前是空闲状态
- }
- @Override
- public void start() {
- Source source = getSource(); //获取Source
- ChannelProcessor cp = source.getChannelProcessor(); //Channel处理器
- cp.initialize(); //初始化Channel处理器
- source.start(); //启动Source
- lifecycleState = LifecycleState.START; //本组件状态改成启动状态
- }
- @Override
- public void stop() {
- Source source = getSource(); //先停Source
- source.stop();
- ChannelProcessor cp = source.getChannelProcessor();
- cp.close();//再停Channel处理器
- lifecycleState = LifecycleState.STOP; //本组件状态改成停止状态
- }
- }
从本组件也可以看出:1、首先要初始化ChannelProcessor,其实现时初始化过滤器链;2、接着启动Source并更改本组件的状态。
- public class PollableSourceRunner extends SourceRunner {
- @Override
- public void start() {
- PollableSource source = (PollableSource) getSource();
- ChannelProcessor cp = source.getChannelProcessor();
- cp.initialize();
- source.start();
- runner = new PollingRunner();
- runner.source = source;
- runner.counterGroup = counterGroup;
- runner.shouldStop = shouldStop;
- runnerThread = new Thread(runner);
- runnerThread.setName(getClass().getSimpleName() + "-" +
- source.getClass().getSimpleName() + "-" + source.getName());
- runnerThread.start();
- lifecycleState = LifecycleState.START;
- }
- }
而PollingRunner首先初始化组件,但是又启动了一个线程PollingRunner,其作用就是轮训拉取数据:
- @Override
- public void run() {
- while (!shouldStop.get()) { //如果没有停止,则一直在死循环运行
- counterGroup.incrementAndGet("runner.polls");
- try {
- //调用PollableSource的process方法进行轮训拉取,然后判断是否遇到了失败补偿
- if (source.process().equals(PollableSource.Status.BACKOFF)) {/
- counterGroup.incrementAndGet("runner.backoffs");
- //失败补偿时暂停线程处理,等待超时时间之后重试
- Thread.sleep(Math.min(
- counterGroup.incrementAndGet("runner.backoffs.consecutive")
- * source.getBackOffSleepIncrement(), source.getMaxBackOffSleepInterval()));
- } else {
- counterGroup.set("runner.backoffs.consecutive", 0L);
- }
- } catch (InterruptedException e) {
- }
- }
- }
- }
- }
Flume在启动时会判断Source是PollableSource还是EventDrivenSource来选择使用PollableSourceRunner还是EventDrivenSourceRunner。
比如HttpSource实现,其通过FlumeHTTPServlet接收消息然后:
- List<Event> events = Collections.emptyList(); //create empty list
- //首先从请求中获取Event
- events = handler.getEvents(request);
- //然后交给ChannelProcessor进行处理
- getChannelProcessor().processEventBatch(events);
到此基本的Source流程就介绍完了,其作用就是监听日志,采集,然后交给ChannelProcessor进行处理。
2、Channel
Channel用于连接Source和Sink,Source生产日志发送到Channel,Sink从Channel消费日志;也就是说通过Channel实现了Source和Sink的解耦,可以实现多对多的关联,和Source、Sink的异步化。
之前Source采集到日志后会交给ChannelProcessor处理,那么接下来我们先从ChannelProcessor入手,其依赖三个组件:
- private final ChannelSelector selector; //Channel选择器
- private final InterceptorChain interceptorChain; //拦截器链
- private ExecutorService execService; //用于实现可选Channel的ExecutorService,默认是单线程实现
接下来看下其是如何处理Event的:
- public void processEvent(Event event) {
- event = interceptorChain.intercept(event); //首先进行拦截器链过滤
- if (event == null) {
- return;
- }
- List<Event> events = new ArrayList<Event>(1);
- events.add(event);
- //通过Channel选择器获取必须成功处理的Channel,然后事务中执行
- List<Channel> requiredChannels = selector.getRequiredChannels(event);
- for (Channel reqChannel : requiredChannels) {
- executeChannelTransaction(reqChannel, events, false);
- }
- //通过Channel选择器获取可选的Channel,这些Channel失败是可以忽略,不影响其他Channel的处理
- List<Channel> optionalChannels = selector.getOptionalChannels(event);
- for (Channel optChannel : optionalChannels) {
- execService.submit(new OptionalChannelTransactionRunnable(optChannel, events));
- }
- }
另外内部还提供了批处理实现方法processEventBatch;对于内部事务实现的话可以参考executeChannelTransaction方法,整体事务机制类似于JDBC:
- private static void executeChannelTransaction(Channel channel, List<Event> batch, boolean isOptional) {
- //1、获取Channel上的事务
- Transaction tx = channel.getTransaction();
- Preconditions.checkNotNull(tx, "Transaction object must not be null");
- try {
- //2、开启事务
- tx.begin();
- //3、在Channel上执行批量put操作
- for (Event event : batch) {
- channel.put(event);
- }
- //4、成功后提交事务
- tx.commit();
- } catch (Throwable t) {
- //5、异常后回滚事务
- tx.rollback();
- if (t instanceof Error) {
- LOG.error("Error while writing to channel: " +
- channel, t);
- throw (Error) t;
- } else if(!isOptional) {//如果是可选的Channel,异常忽略
- throw new ChannelException("Unable to put batch on required " +
- "channel: " + channel, t);
- }
- } finally {
- //最后关闭事务
- tx.close();
- }
- }
Interceptor用于过滤Event,即传入一个Event然后进行过滤加工,然后返回一个新的Event,接口如下:
- public interface Interceptor {
- public void initialize();
- public Event intercept(Event event);
- public List<Event> intercept(List<Event> events);
- public void close();
- }
可以看到其提供了initialize和close方法用于启动和关闭;intercept方法用于过滤或加工Event。比如HostInterceptor拦截器用于获取本机IP然后默认添加到Event的字段为host的Header中。
接下来就是ChannelSelector选择器了,其通过如下方式创建:
- //获取ChannelSelector配置,比如agent.sources.s1.selector.type = replicating
- ChannelSelectorConfiguration selectorConfig = config.getSelectorConfiguration();
- //使用Source关联的Channel创建,比如agent.sources.s1.channels = c1 c2
- ChannelSelector selector = ChannelSelectorFactory.create(sourceChannels, selectorConfig);
ChannelSelector默认提供了两种实现:复制和多路复用:
默认实现是复制选择器ReplicatingChannelSelector,即把接收到的消息复制到每一个Channel;多路复用选择器MultiplexingChannelSelector会根据Event Header中的参数进行选择,以此来选择使用哪个Channel。
而Channel是Event中转的地方,Source发布Event到Channel,Sink消费Channel的Event;Channel接口提供了如下接口用来实现Event流转:
- public interface Channel extends LifecycleAware, NamedComponent {
- public void put(Event event) throws ChannelException;
- public Event take() throws ChannelException;
- public Transaction getTransaction();
- }
put用于发布Event,take用于消费Event,getTransaction用于事务支持。默认提供了如下Channel的实现:
对于Channel的实现我们后续单独章节介绍。
3、Sink
Sink从Channel消费Event,然后进行转移到收集/聚合层或存储层。Sink接口如下所示:
- public interface Sink extends LifecycleAware, NamedComponent {
- public void setChannel(Channel channel);
- public Channel getChannel();
- public Status process() throws EventDeliveryException;
- public static enum Status {
- READY, BACKOFF
- }
- }
类似于Source,其首先继承了LifecycleAware,然后提供了Channel的getter/setter方法,并提供了process方法进行消费,此方法会返回消费的状态,READY或BACKOFF。
Sink也是通过SinkFactory工厂来创建,其也提供了DefaultSinkFactory默认工厂,比如传入hdfs,会先查找Enum org.apache.flume.conf.sink.SinkType,然后找到相应的默认处理类org.apache.flume.sink.hdfs.HDFSEventSink,如果没找到默认处理类,直接通过Class.forName(className)进行反射创建。
我们知道Sink还提供了分组功能,用于把多个Sink聚合为一组进行使用,内部提供了SinkGroup用来完成这个事情。此时问题来了,如何去调度多个Sink,其内部使用了SinkProcessor来完成这个事情,默认提供了故障转移和负载均衡两个策略。
首先SinkGroup就是聚合多个Sink为一组,然后将多个Sink传给SinkProcessorFactory进行创建SinkProcessor,而策略是根据配置文件中配置的如agent.sinkgroups.g1.processor.type = load_balance来选择的。
SinkProcessor提供了如下实现:
DefaultSinkProcessor:默认实现,用于单个Sink的场景使用。
FailoverSinkProcessor:故障转移实现:
- public Status process() throws EventDeliveryException {
- Long now = System.currentTimeMillis();
- //1、首先检查失败队列的头部的Sink是否已经过了失败补偿等待时间了
- while(!failedSinks.isEmpty() && failedSinks.peek().getRefresh() < now) {
- //2、如果可以使用了,则从失败Sink队列获取队列第一个Sink
- FailedSink cur = failedSinks.poll();
- Status s;
- try {
- s = cur.getSink().process(); //3、使用此Sink进行处理
- if (s == Status.READY) { //4、如果处理成功
- liveSinks.put(cur.getPriority(), cur.getSink()); //4.1、放回存活Sink队列
- activeSink = liveSinks.get(liveSinks.lastKey());
- } else {
- failedSinks.add(cur); //4.2、如果此时不是READY,即BACKOFF期间,再次放回失败队列
- }
- return s;
- } catch (Exception e) {
- cur.incFails(); //5、如果遇到异常了,则增加失败次数,并放回失败队列
- failedSinks.add(cur);
- }
- }
- Status ret = null;
- while(activeSink != null) { //6、此时失败队列中没有Sink能处理了,那么需要使用存活Sink队列进行处理
- try {
- ret = activeSink.process();
- return ret;
- } catch (Exception e) { //7、处理失败进行转移到失败队列
- activeSink = moveActiveToDeadAndGetNext();
- }
- }
- throw new EventDeliveryException("All sinks failed to process, " +
- "nothing left to failover to");
- }
失败队列是一个优先级队列,使用refresh属性排序,而refresh是通过如下机制计算的:
- refresh = System.currentTimeMillis()
- + Math.min(maxPenalty, (1 << sequentialFailures) * FAILURE_PENALTY);
其中maxPenalty是最大等待时间,默认30s,而(1 << sequentialFailures) * FAILURE_PENALTY)用于实现指数级等待时间递增, FAILURE_PENALTY是1s。
LoadBalanceSinkProcessor:用于实现Sink的负载均衡,其通过SinkSelector进行实现,类似于ChannelSelector。LoadBalanceSinkProcessor在启动时会根据配置,如agent.sinkgroups.g1.processor.selector = random进行选择,默认提供了两种选择器:
LoadBalanceSinkProcessor使用如下机制进行负载均衡:
- public Status process() throws EventDeliveryException {
- Status status = null;
- //1、使用选择器创建相应的迭代器,也就是用来选择Sink的迭代器
- Iterator<Sink> sinkIterator = selector.createSinkIterator();
- while (sinkIterator.hasNext()) {
- Sink sink = sinkIterator.next();
- try {
- //2、选择器迭代Sink进行处理,如果成功直接break掉这次处理,此次负载均衡就算完成了
- status = sink.process();
- break;
- } catch (Exception ex) {
- //3、失败后会通知选择器,采取相应的失败退避补偿算法进行处理
- selector.informSinkFailed(sink);
- LOGGER.warn("Sink failed to consume event. "
- + "Attempting next sink if available.", ex);
- }
- }
- if (status == null) {
- throw new EventDeliveryException("All configured sinks have failed");
- }
- return status;
- }
如上的核心就是怎么创建迭代器,如何进行失败退避补偿处理,首先我们看下RoundRobinSinkSelector实现,其内部是通过通用的RoundRobinOrderSelector选择器实现:
- public Iterator<T> createIterator() {
- //1、获取存活的Sink索引,
- List<Integer> activeIndices = getIndexList();
- int size = activeIndices.size();
- //2、如果上次记录的下一个存活Sink的位置超过了size,那么从队列头重新开始计数
- if (nextHead >= size) {
- nextHead = 0;
- }
- //3、获取本次使用的起始位置
- int begin = nextHead++;
- if (nextHead == activeIndices.size()) {
- nextHead = 0;
- }
- //4、从该位置开始迭代,其实现类似于环形队列,比如整个队列是5,起始位置是3,则按照 3、4、0、1、2的顺序进行轮训,实现了轮训算法
- int[] indexOrder = new int[size];
- for (int i = 0; i < size; i++) {
- indexOrder[i] = activeIndices.get((begin + i) % size);
- }
- //indexOrder是迭代顺序,getObjects返回相关的Sinks;
- return new SpecificOrderIterator<T>(indexOrder, getObjects());
- }
getIndexList实现如下:
- protected List<Integer> getIndexList() {
- long now = System.currentTimeMillis();
- List<Integer> indexList = new ArrayList<Integer>();
- int i = 0;
- for (T obj : stateMap.keySet()) {
- if (!isShouldBackOff() || stateMap.get(obj).restoreTime < now) {
- indexList.add(i);
- }
- i++;
- }
- return indexList;
- }
isShouldBackOff()表示是否开启退避算法支持,如果不开启,则认为每个Sink都是存活的,每次都会重试,通过agent.sinkgroups.g1.processor.backoff = true配置开启,默认false;restoreTime和之前介绍的refresh一样,是退避补偿等待时间,算法类似,就不多介绍了。
那么什么时候调用Sink进行消费呢?其类似于SourceRunner,Sink提供了SinkRunner进行轮训拉取处理,SinkRunner会轮训调度SinkProcessor消费Channel的消息,然后调用Sink进行转移。SinkProcessor之前介绍过,其负责消息复制/路由。
SinkRunner实现如下:
- public void start() {
- SinkProcessor policy = getPolicy();
- policy.start();
- runner = new PollingRunner();
- runner.policy = policy;
- runner.counterGroup = counterGroup;
- runner.shouldStop = new AtomicBoolean();
- runnerThread = new Thread(runner);
- runnerThread.setName("SinkRunner-PollingRunner-" +
- policy.getClass().getSimpleName());
- runnerThread.start();
- lifecycleState = LifecycleState.START;
- }
即获取SinkProcessor然后启动它,接着启动轮训线程去处理。PollingRunner线程负责轮训消息,核心实现如下:
- public void run() {
- while (!shouldStop.get()) { //如果没有停止
- try {
- if (policy.process().equals(Sink.Status.BACKOFF)) {//如果处理失败了,进行退避补偿处理
- counterGroup.incrementAndGet("runner.backoffs");
- Thread.sleep(Math.min(
- counterGroup.incrementAndGet("runner.backoffs.consecutive")
- * backoffSleepIncrement, maxBackoffSleep)); //暂停退避补偿设定的超时时间
- } else {
- counterGroup.set("runner.backoffs.consecutive", 0L);
- }
- } catch (Exception e) {
- try {
- Thread.sleep(maxBackoffSleep); //如果遇到异常则等待最大退避时间
- } catch (InterruptedException ex) {
- Thread.currentThread().interrupt();
- }
- }
- }
- }
整体实现类似于PollableSourceRunner实现,整体处理都是交给SinkProcessor完成的。SinkProcessor会轮训Sink的process方法进行处理;此处以LoggerSink为例:
- @Override
- public Status process() throws EventDeliveryException {
- Status result = Status.READY;
- Channel channel = getChannel();
- //1、获取事务
- Transaction transaction = channel.getTransaction();
- Event event = null;
- try {
- //2、开启事务
- transaction.begin();
- //3、从Channel获取Event
- event = channel.take();
- if (event != null) {
- if (logger.isInfoEnabled()) {
- logger.info("Event: " + EventHelper.dumpEvent(event, maxBytesToLog));
- }
- } else {//4、如果Channel中没有Event,则默认进入故障补偿机制,即防止死循环造成CPU负载高
- result = Status.BACKOFF;
- }
- //5、成功后提交事务
- transaction.commit();
- } catch (Exception ex) {
- //6、失败后回滚事务
- transaction.rollback();
- throw new EventDeliveryException("Failed to log event: " + event, ex);
- } finally {
- //7、关闭事务
- transaction.close();
- }
- return result;
- }
Sink中一些实现是支持批处理的,比如RollingFileSink:
- //1、开启事务
- //2、批处理
- for (int i = 0; i < batchSize; i++) {
- event = channel.take();
- if (event != null) {
- sinkCounter.incrementEventDrainAttemptCount();
- eventAttemptCounter++;
- serializer.write(event);
- }
- }
- //3、提交/回滚事务、关闭事务
定义一个批处理大小然后在事务中执行批处理。
4、整体流程
从以上部分我们可以看出,不管是Source还是Sink都依赖Channel,那么启动时应该先启动Channel然后再启动Source或Sink即可。
Flume有两种启动方式:使用EmbeddedAgent内嵌在Java应用中或使用Application单独启动一个进程,此处我们已Application分析为主。
首先进入org.apache.flume.node.Application的main方法启动:
- //1、设置默认值启动参数、参数是否必须的
- Options options = new Options();
- Option option = new Option("n", "name", true, "the name of this agent");
- option.setRequired(true);
- options.addOption(option);
- option = new Option("f", "conf-file", true,
- "specify a config file (required if -z missing)");
- option.setRequired(false);
- options.addOption(option);
- //2、接着解析命令行参数
- CommandLineParser parser = new GnuParser();
- CommandLine commandLine = parser.parse(options, args);
- String agentName = commandLine.getOptionValue('n');
- boolean reload = !commandLine.hasOption("no-reload-conf");
- if (commandLine.hasOption('z') || commandLine.hasOption("zkConnString")) {
- isZkConfigured = true;
- }
- if (isZkConfigured) {
- //3、如果是通过ZooKeeper配置,则使用ZooKeeper参数启动,此处忽略,我们以配置文件讲解
- } else {
- //4、打开配置文件,如果不存在则快速失败
- File configurationFile = new File(commandLine.getOptionValue('f'));
- if (!configurationFile.exists()) {
- throw new ParseException(
- "The specified configuration file does not exist: " + path);
- }
- List<LifecycleAware> components = Lists.newArrayList();
- if (reload) { //5、如果需要定期reload配置文件,则走如下方式
- //5.1、此处使用Guava提供的事件总线
- EventBus eventBus = new EventBus(agentName + "-event-bus");
- //5.2、读取配置文件,使用定期轮训拉起策略,默认30s拉取一次
- PollingPropertiesFileConfigurationProvider configurationProvider =
- new PollingPropertiesFileConfigurationProvider(
- agentName, configurationFile, eventBus, 30);
- components.add(configurationProvider);
- application = new Application(components); //5.3、向Application注册组件
- //5.4、向事件总线注册本应用,EventBus会自动注册Application中使用@Subscribe声明的方法
- eventBus.register(application);
- } else { //5、配置文件不支持定期reload
- PropertiesFileConfigurationProvider configurationProvider =
- new PropertiesFileConfigurationProvider(
- agentName, configurationFile);
- application = new Application();
- //6.2、直接使用配置文件初始化Flume组件
- application.handleConfigurationEvent(configurationProvider
- .getConfiguration());
- }
- }
- //7、启动Flume应用
- application.start();
- //8、注册虚拟机关闭钩子,当虚拟机关闭时调用Application的stop方法进行终止
- final Application appReference = application;
- Runtime.getRuntime().addShutdownHook(new Thread("agent-shutdown-hook") {
- @Override
- public void run() {
- appReference.stop();
- }
- });
以上流程只提取了核心代码中的一部分,比如ZK的实现直接忽略了,而Flume启动大体流程如下:
1、读取命令行参数;
2、读取配置文件;
3、根据是否需要reload使用不同的策略初始化Flume;如果需要reload,则使用Guava的事件总线实现,Application的handleConfigurationEvent是事件订阅者,PollingPropertiesFileConfigurationProvider是事件发布者,其会定期轮训检查文件是否变更,如果变更则重新读取配置文件,发布配置文件事件变更,而handleConfigurationEvent会收到该配置变更重新进行初始化;
4、启动Application,并注册虚拟机关闭钩子。
handleConfigurationEvent方法比较简单,首先调用了stopAllComponents停止所有组件,接着调用startAllComponents使用配置文件初始化所有组件:
- @Subscribe
- public synchronized void handleConfigurationEvent(MaterializedConfiguration conf) {
- stopAllComponents();
- startAllComponents(conf);
- }
MaterializedConfiguration存储Flume运行时需要的组件:Source、Channel、Sink、SourceRunner、SinkRunner等,其是通过ConfigurationProvider进行初始化获取,比如PollingPropertiesFileConfigurationProvider会读取配置文件然后进行组件的初始化。
对于startAllComponents实现大体如下:
- //1、首先启动Channel
- supervisor.supervise(Channels,
- new SupervisorPolicy.AlwaysRestartPolicy(), LifecycleState.START);
- //2、确保所有Channel是否都已启动
- for(Channel ch: materializedConfiguration.getChannels().values()){
- while(ch.getLifecycleState() != LifecycleState.START
- && !supervisor.isComponentInErrorState(ch)){
- try {
- Thread.sleep(500);
- } catch (InterruptedException e) {
- Throwables.propagate(e);
- }
- }
- }
- //3、启动SinkRunner
- supervisor.supervise(SinkRunners,
- new SupervisorPolicy.AlwaysRestartPolicy(), LifecycleState.START);
- //4、启动SourceRunner
- supervisor.supervise(SourceRunner,
- new SupervisorPolicy.AlwaysRestartPolicy(), LifecycleState.START);
- //5、初始化监控服务
- this.loadMonitoring();
从如下代码中可以看到,首先要准备好Channel,因为Source和Sink会操作它,对于Channel如果初始化失败则整个流程是失败的;然后启动SinkRunner,先准备好消费者;接着启动SourceRunner开始进行采集日志。此处我们发现有两个单独的组件LifecycleSupervisor和MonitorService,一个是组件守护哨兵,一个是监控服务。守护哨兵对这些组件进行守护,假设出问题了默认策略是自动重启这些组件。
对于stopAllComponents实现大体如下:
- //1、首先停止SourceRunner
- supervisor.unsupervise(SourceRunners);
- //2、接着停止SinkRunner
- supervisor.unsupervise(SinkRunners);
- //3、然后停止Channel
- supervisor.unsupervise(Channels);
- //4、最后停止MonitorService
- monitorServer.stop();
此处可以看出,停止的顺序是Source、Sink、Channel,即先停止生产,再停止消费,最后停止管道。
Application中的start方法代码实现如下:
- public synchronized void start() {
- for(LifecycleAware component : components) {
- supervisor.supervise(component,
- new SupervisorPolicy.AlwaysRestartPolicy(), LifecycleState.START);
- }
- }
其循环Application注册的组件,然后守护哨兵对它进行守护,默认策略是出现问题会自动重启组件,假设我们支持reload配置文件,则之前启动Application时注册过PollingPropertiesFileConfigurationProvider组件,即该组件会被守护哨兵守护着,出现问题默认策略自动重启。
而Application关闭执行了如下动作:
- public synchronized void stop() {
- supervisor.stop();
- if(monitorServer != null) {
- monitorServer.stop();
- }
- }
即关闭守护哨兵和监控服务。
到此基本的Application分析结束了,我们还有很多疑问,守护哨兵怎么实现的。
整体流程可以总结为:
1、首先初始化命令行配置;
2、接着读取配置文件;
3、根据是否需要reload初始化配置文件中的组件;如果需要reload会使用Guava事件总线进行发布订阅变化;
4、接着创建Application,创建守护哨兵,并先停止所有组件,接着启动所有组件;启动顺序:Channel、SinkRunner、SourceRunner,并把这些组件注册给守护哨兵、初始化监控服务;停止顺序:SourceRunner、SinkRunner、Channel;
5、如果配置文件需要定期reload,则需要注册Polling***ConfigurationProvider到守护哨兵;
6、最后注册虚拟机关闭钩子,停止守护哨兵和监控服务。
轮训实现的SourceRunner 和SinkRunner会创建一个线程进行工作,之前已经介绍了其工作方式。接下来我们看下守护哨兵的实现。
首先创建LifecycleSupervisor:
- //1、用于存放被守护的组件
- supervisedProcesses = new HashMap<LifecycleAware, Supervisoree>();
- //2、用于存放正在被监控的组件
- monitorFutures = new HashMap<LifecycleAware, ScheduledFuture<?>>();
- //3、创建监控服务线程池
- monitorService = new ScheduledThreadPoolExecutor(10,
- new ThreadFactoryBuilder().setNameFormat(
- "lifecycleSupervisor-" + Thread.currentThread().getId() + "-%d")
- .build());
- monitorService.setMaximumPoolSize(20);
- monitorService.setKeepAliveTime(30, TimeUnit.SECONDS);
- //4、定期清理被取消的组件
- purger = new Purger();
- //4.1、默认不进行清理
- needToPurge = false;
LifecycleSupervisor启动时会进行如下操作:
- public synchronized void start() {
- monitorService.scheduleWithFixedDelay(purger, 2, 2, TimeUnit.HOURS);
- lifecycleState = LifecycleState.START;
- }
首先每隔两个小时执行清理组件,然后改变状态为启动。而LifecycleSupervisor停止时直接停止了监控服务,然后更新守护组件状态为STOP:
- //1、首先停止守护监控服务
- if (monitorService != null) {
- monitorService.shutdown();
- try {
- monitorService.awaitTermination(10, TimeUnit.SECONDS);
- } catch (InterruptedException e) {
- logger.error("Interrupted while waiting for monitor service to stop");
- }
- }
- //2、更新所有守护组件状态为STOP,并调用组件的stop方法进行停止
- for (final Entry<LifecycleAware, Supervisoree> entry : supervisedProcesses.entrySet()) {
- if (entry.getKey().getLifecycleState().equals(LifecycleState.START)) {
- entry.getValue().status.desiredState = LifecycleState.STOP;
- entry.getKey().stop();
- }
- }
- //3、更新本组件状态
- if (lifecycleState.equals(LifecycleState.START)) {
- lifecycleState = LifecycleState.STOP;
- }
- //4、最后的清理
- supervisedProcesses.clear();
- monitorFutures.clear();
接下来就是调用supervise进行组件守护了:
- if(this.monitorService.isShutdown() || this.monitorService.isTerminated()
- || this.monitorService.isTerminating()){
- //1、如果哨兵已停止则抛出异常,不再接收任何组件进行守护
- }
- //2、初始化守护组件
- Supervisoree process = new Supervisoree();
- process.status = new Status();
- //2.1、默认策略是失败重启
- process.policy = policy;
- //2.2、初始化组件默认状态,大多数组件默认为START
- process.status.desiredState = desiredState;
- process.status.error = false;
- //3、组件监控器,用于定时获取组件的最新状态,或者重新启动组件
- MonitorRunnable monitorRunnable = new MonitorRunnable();
- monitorRunnable.lifecycleAware = lifecycleAware;
- monitorRunnable.supervisoree = process;
- monitorRunnable.monitorService = monitorService;
- supervisedProcesses.put(lifecycleAware, process);
- //4、定期的去执行组件监控器,获取组件最新状态,或者重新启动组件
- ScheduledFuture<?> future = monitorService.scheduleWithFixedDelay(
- monitorRunnable, 0, 3, TimeUnit.SECONDS);
- monitorFutures.put(lifecycleAware, future);
- }
如果不需要守护了,则需要调用unsupervise:
- public synchronized void unsupervise(LifecycleAware lifecycleAware) {
- synchronized (lifecycleAware) {
- Supervisoree supervisoree = supervisedProcesses.get(lifecycleAware);
- //1.1、设置守护组件的状态为被丢弃
- supervisoree.status.discard = true;
- //1.2、设置组件盼望的最新生命周期状态为STOP
- this.setDesiredState(lifecycleAware, LifecycleState.STOP);
- //1.3、停止组件
- lifecycleAware.stop();
- }
- //2、从守护组件中移除
- supervisedProcesses.remove(lifecycleAware);
- //3、取消定时监控组件服务
- monitorFutures.get(lifecycleAware).cancel(false);
- //3.1、通知Purger需要进行清理,Purger会定期的移除cancel的组件
- needToPurge = true;
- monitorFutures.remove(lifecycleAware);
- }
接下来我们再看下MonitorRunnable的实现,其负责进行组件状态迁移或组件故障恢复:
- public void run() {
- long now = System.currentTimeMillis();
- try {
- if (supervisoree.status.firstSeen == null) {
- supervisoree.status.firstSeen = now; //1、记录第一次状态查看时间
- }
- supervisoree.status.lastSeen = now; //2、记录最后一次状态查看时间
- synchronized (lifecycleAware) {
- //3、如果守护组件被丢弃或出错了,则直接返回
- if (supervisoree.status.discard || supervisoree.status.error) {
- return;
- }
- //4、更新最后一次查看到的状态
- supervisoree.status.lastSeenState = lifecycleAware.getLifecycleState();
- //5、如果组件的状态和守护组件看到的状态不一致,则以守护组件的状态为准,然后进行初始化
- if (!lifecycleAware.getLifecycleState().equals(
- supervisoree.status.desiredState)) {
- switch (supervisoree.status.desiredState) {
- case START: //6、如果是启动状态,则启动组件
- try {
- lifecycleAware.start();
- } catch (Throwable e) {
- if (e instanceof Error) {
- supervisoree.status.desiredState = LifecycleState.STOP;
- try {
- lifecycleAware.stop();
- } catch (Throwable e1) {
- supervisoree.status.error = true;
- if (e1 instanceof Error) {
- throw (Error) e1;
- }
- }
- }
- supervisoree.status.failures++;
- }
- break;
- case STOP: //7、如果是停止状态,则停止组件
- try {
- lifecycleAware.stop();
- } catch (Throwable e) {
- if (e instanceof Error) {
- throw (Error) e;
- }
- supervisoree.status.failures++;
- }
- break;
- default:
- }
- } catch(Throwable t) {
- }
- }
- }
如上代码进行了一些简化,整体逻辑即定时去采集组件的状态,如果发现守护组件和组件的状态不一致,则可能需要进行启动或停止。即守护监视器可以用来保证组件如能失败后自动启动。默认策略是总是失败后重启,还有一种策略是只启动一次。
日志是系统数据的基石,对于系统的安全来说非常重要,它记录了系统每天发生的各种各样的事情,用户可以通过它来检查错误发生的原因,或者寻找受到攻击时攻击者留下的痕迹。日志主要的功能是审计和监测。它还可以实时地监测系统状态,监测和追踪侵入者。现在互联网上存在的日志组件各种各样,我们这里主要讲的是Flume。
Flume 发展历史
Cloudera 开发的分布式日志收集系统 Flume,是 hadoop 周边组件之一。其可以实时的将分布在不同节点、机器上的日志收集到 hdfs 中。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,这点可以在 BigInsights 产品文档的 troubleshooting 板块发现。为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。当然我们现在用的是Flume NG,所以不再讲Flume OG的内容。
Flume定义
Flume是一个高可用,高可靠,分布式海量日志采集、聚合和传输系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume架构介绍
Flume日志收集结构图
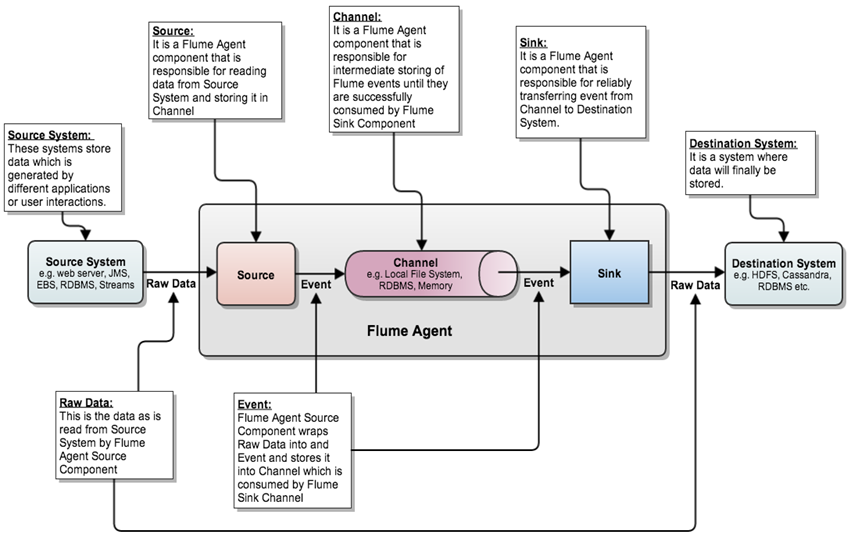
Flume 的核心是把数据从数据源收集过来,再送到目的地。
为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。
Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。
Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
Flume 运行的核心是 Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是 Source、Channel、Sink。
Source 可以接收外部源发送过来的数据。不同的 Source,可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容。
Channel 是一个存储地,接收 Source 的输出,直到有 Sink 消费掉 Channel 中的数据。
Channel 中的数据直到进入到下一个Channel中或者进入终端才会被删除。
当 Sink 写入失败后,可以自动重启,不会造成数据丢失,因此很可靠。
Sink 会消费 Channel 中的数据,然后送给外部源或者其他 Source。如数据可以写入到 HDFS 或者 HBase 中。
Flume 核心概念整理
Agent Agent中包含多个sources和sinks。
Client 生产数据,运行在一个独立的线程。
Source 从Client收集数据,传递给Channel。用来消费传递到该组件的Event。
Sink 从Channel收集数据,将Event传递到Flow Pipeline中的下一个Agent。
Channel 中转Event临时存储,保存Source传递过来Event,连接 sources 和 sinks 。
Events 一个数据单元,带有一个可选的消息头。可以是日志记录、 avro 对象等。
Flume 特点
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
Agent是Flume中最小的运行单位,一个Agent中由Source、Sink和Channel三个组件构成。
Event是Flume中基本数据单位,Event中包含有传输数据及数据头数据包
如下图所示: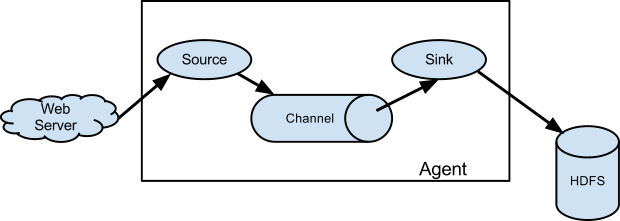
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。
比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。
如下图所示: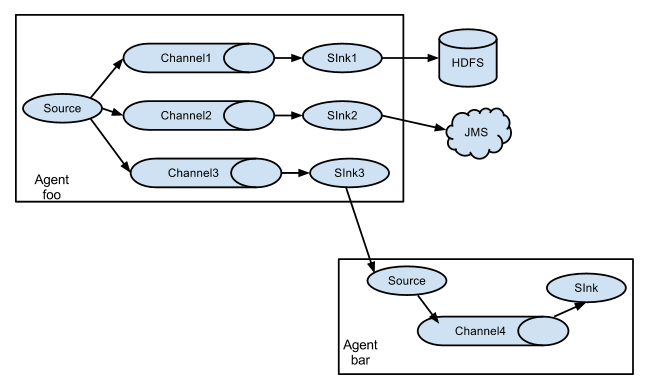
Flume 整体架构总结
Flume架构整体上看就是 source-->channel-->sink 的三层架构,类似生成者和消费者的架构,他们之间通过queue(channel)传输,解耦。
Source:完成对日志数据的收集,分成 transtion 和 event 打入到channel之中。
Channel:主要提供一个队列的功能,对source提供中的数据进行简单的缓存。
Sink:取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
对现有程序改动最小的使用方式是使用是直接读取程序原来记录的日志文件,基本可以实现无缝接入,不需要对现有程序进行任何改动。
Flume 下载、安装
安装JDK
1.将下载好的JDK包解压,比如我的解压到 /home/liuqing/jdk1.7.0_72 目录下
2.配置环境变量
在/etc/profile 文件中添加
- export JAVA_HOME=/home/liuqing/jdk1.7.0_72
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASS_PATH
3.执行source profile
4.在命令行输入 java -version
出现:
java version "1.7.0_72"
Java(TM) SE Runtime Environment (build 1.7.0_72-b14)
Java HotSpot(TM) 64-Bit Server VM (build 24.72-b04, mixed mode)
表示安装成功
安装Flume
1. 从官网 http://flume.apache.org/download.html 下载最新的安装包
2. 解压缩,比如我的解压到 /home/liuqing/hadoop/flume目录
3. 修改 flume-env.sh 配置文件,主要是JAVA_HOME变量设置
JAVA_HOME=/home/liuqing/jdk1.7.0_72
4. 验证是否安装成功
root@ubuntu:/home/liuqing/hadoop/flume/bin# ./flume-ng version
出现:
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
表示安装成功
案例
案例1. 单节点 Flume配置
1. 新建配置文件,配置文件示例
- # example.conf: A single-node Flume configuration
- # agent组件名称
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- # source 配置
- a1.sources.r1.type = netcat
- a1.sources.r1.bind = localhost
- a1.sources.r1.port = 44444
- # sink 配置
- a1.sinks.k1.type = logger
- # 使用内存中Buffer Event Channel
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000
- a1.channels.c1.transactionCapacity = 100
- # 绑定 source 和 sink 到channel
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
将上述配置存为:/home/liuqing/hadoop/flume/conf/example.conf
2. 然后我们就可以启动 Flume 了:
在/home/liuqing/hadoop/flume路径下运行:
- bin/flume-ngagent --conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,console
其中 -c/--conf 后跟配置目录,-f/--conf-file 后跟具体的配置文件,-n/--name 指定agent的名称
3. 然后我们再开一个 shell 终端窗口,telnet 上配置中侦听的端口,就可以发消息看到效果了:
- $ telnet localhost 44444
- Trying 127.0.0.1...
- Connected to localhost.localdomain (127.0.0.1).
- Escape character is '^]'.
- Hello world! <ENTER>
- OK
4.Flume 终端窗口此时会打印出如下信息,就表示成功了
- 12/06/1915:32:19 INFO source.NetcatSource: Source starting
- 12/06/1915:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
- 12/06/1915:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
至此,咱们的第一个 Flume Agent 算是部署成功了!
案例2. 结合实际项目
参考:https://github.com/gilt/logback-flume-appender
1. 在/home/liuqing/hadoop/flume/conf/下新建配置文件 test.conf
- agent1.sources = source1
- agent1.sinks = sink1
- agent1.channels = channel1
- # Describe/configure source1
- agent1.sources.source1.type = avro
- agent1.sources.source1.bind = 0.0.0.0
- agent1.sources.source1.port = 44444
- # Describe sink1
- #日志文件按时间生成
- #agent1.sinks.sink1.type = FILE_ROLL
- #agent1.sinks.sink1.sink.directory = /home/liuqing/hadoop/flume/flume-out
- #agent1.sinks.sink1.sink.rollInterval = 1800
- #agent1.sinks.sink1.batchSize = 5
- #日志文件根据大小生成
- #生成目录在conf文件夹下的log4j.properties可以配置
- agent1.sinks.sink1.type = logger
- # Use a channel which buffers events in memory
- agent1.channels.channel1.type = memory
- agent1.channels.channel1.capacity = 1000
- agent1.channels.channel1.transactionCapactiy = 100
- # Bind the source and sink to the channel
- agent1.sources.source1.channels = channel1
- agent1.sinks.sink1.channel = channel1
2. 项目已经配好了logback.xml 文件
在logback.xml文件中添加
- <appender name="flumeApplender"
- class="com.xxx.hd.extended.log.flume.FlumeLogstashV1Appender">
- <flumeAgents>
- 192.168.23.235:44444,
- </flumeAgents>
- <flumeProperties>
- connect-timeout=4000;
- request-timeout=8000
- </flumeProperties>
- <batchSize>2048</batchSize>
- <reportingWindow>20480</reportingWindow>
- <additionalAvroHeaders>
- myHeader=myValue
- </additionalAvroHeaders>
- <application>ProjectName</application>
- <layout class="ch.qos.logback.classic.PatternLayout">
- <pattern>%d{HH:mm:ss.SSS} %-5level %logger{36} - \(%file:%line\) - %msg%n%ex</pattern>
- </layout>
- </appender>
3. 然后我们就可以启动 Flume 了:
在/home/liuqing/hadoop/flume路径下运行:
- bin/flume-ng agent --conf ./conf/ -f conf/lqtest.conf -n agent1
4. 现在日志会打印到/home/liuqing/hadoop/flume/logs目录下
日志文件满128M就会自动建一个新的
Flume架构与源码分析-整体架构的更多相关文章
- 精尽 MyBatis 源码分析 - 整体架构
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- Fresco 源码分析 —— 整体架构
Fresco 是我们项目中图片加载专用框架.虽然我不是负责 Fresco 框架,但是由本人负责组里的图片加载浏览等工作,因此了解 Fresco 的源码有助于我今后的工作,也可以学习 Fresco 的源 ...
- zepto源码分析·整体架构
代码数量 1.2.0版本代码量为1650行,去掉注释大概1500左右 代码模块 默认版本只包括核心模块,事件模块,ajax模块,form模块和ie模块,其它模块需要自行拓展加入,其中form模块只包含 ...
- jquery-2.0.3 源码分析 整体架构
关键 var jQuery = function( selector, context ) { return new jQuery.fn.init(); } jQuery.fn = jQuery.pr ...
- Caching-缓存架构与源码分析
Caching-缓存架构与源码分析 首先奉献caching的开源地址[微软源码] 1.工程架构 为了提高程序效率,我们经常将一些不频繁修改,但是使用了还很大的数据进行缓存.尤其是互联网产品,缓存可以说 ...
- MyBatis架构与源码分析<资料收集>
1.架构与源码分析 :https://www.cnblogs.com/luoxn28/p/6417892.html .https://www.cnblogs.com/wangdaijun/p/5296 ...
- MyBatis 源码篇-整体架构
MyBatis 的整体架构分为三层, 分别是基础支持层.核心处理层和接口层,如下图所示. 基础支持层 反射模块 该模块对 Java 原生的反射进行了良好的封装,提供了更加简洁易用的 API ,方便上层 ...
- [转]Libev源码分析 -- 整体设计
Libev源码分析 -- 整体设计 libev是Marc Lehmann用C写的高性能事件循环库.通过libev,可以灵活地把各种事件组织管理起来,如:时钟.io.信号等.libev在业界内也是广受好 ...
- [Asp.net 5] Caching-缓存架构与源码分析
首先奉献caching的开源地址[微软源码] 1.工程架构 为了提高程序效率,我们经常将一些不频繁修改,但是使用了还很大的数据进行缓存.尤其是互联网产品,缓存可以说是提升效率优化第一利器.微软为我们实 ...
- Hessian源码分析--总体架构
Hessian是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能. 相比WebService,Hessian更简单.快捷.采用的是二进制RPC协议,因为采用的是二进制协 ...
随机推荐
- 开源 - Ideal库 - 常用枚举扩展方法(二)
书接上回,今天继续和大家享一些关于枚举操作相关的常用扩展方法. 今天主要分享通过枚举值转换成枚举.枚举名称以及枚举描述相关实现. 我们首先修改一下上一篇定义用来测试的正常枚举,新增一个枚举项,代码如下 ...
- ECharts 引入中国地图和区域地图
一,引入中国地图 <div id="chinaMap"></div> import china from 'echarts/map/js/china. ...
- Mysql分页实现及优化
通常,我们会采用ORDER BY LIMIT start, offset 的方式来进行分页查询.例如下面这个SQL: SELECT * FROM `t1` WHERE ftype=1 ORDER BY ...
- java——棋牌类游戏斗地主(singleddz3.0)
这是本人最近一段时间写的斗地主的java代码,大体框架都实现了,主要缺少,AI的智能算法. 下载地址http://download.csdn.net/detail/novelly/5695445 im ...
- Python:pygame游戏编程之旅一(Hello World)
按照上周计划,今天开始学习pygame,学习资料为http://www.pygame.org/docs/,学习的程序实例为pygame模块自带程序,会在程序中根据自己的理解加入详细注释,并对关键概念做 ...
- python之typing
typing介绍 Python是一门动态语言,很多时候我们可能不清楚函数参数类型或者返回值类型,很有可能导致一些类型没有指定方法,在写完代码一段时间后回过头看代码,很可能忘记了自己写的函数需要传什么参 ...
- 网站安全锁-SSL证书
为了安全起见,现在开发微信服务号和IOS客户端等访问服务器端都要求使用https加密传输. SSL证书是数字证书的一种,类似于驾驶证.护照和营业执照的电子副本.因为配置在服务器上,也称为SSL服务器证 ...
- 大语言模型中的MoE
1.概述 MoE代表"混合专家模型"(Mixture of Experts),这是一种架构设计,通过将不同的子模型(即专家)结合起来进行任务处理.与传统的模型相比,MoE结构能够动 ...
- ZCMU-1110
思路:- 首先可以知道最少动就是从三个角对称的划分 因为不是对称划分则会出现破坏了正三角,后面还要重新对好 之后就可以进行推导(按三角形我没看懂) 其中设底上截出来的三角形的底为i,则上面就是n-2* ...
- ZCMU-1033
我觉得这位大佬说的已经很好了,可以直接看她的思路了: 大佬思路 但是她的代码没有考虑到1 1 1 1的情况, 代码思路 这个是可以的很长且没有注释: #include<bits/stdc++.h ...