第6讲、全面拆解Encoder、Decoder内部模块
全面拆解 Transformer 架构:Encoder、Decoder 内部模块解析(附流程图小测验)
关键词:Transformer、Encoder、Decoder、Self-Attention、Masked Attention、位置编码、残差连接、多头注意力机制
Transformer 自 2017 年诞生以来,已经成为深度学习中最具影响力的模型架构之一。无论是 GPT、BERT,还是今天的大模型 GPT-4、Claude、Gemini,它们的底层都离不开 Transformer 的基本框架。
今天我们就来全面拆解 Transformer 的 Encoder 与 Decoder 内部模块结构,并附上一个动手小测验:画出 Transformer 的完整流程图,帮助大家真正掌握这个强大的架构。
一、Transformer 总览
Transformer 的核心是:自注意力机制(Self-Attention)+ 前馈神经网络(Feed Forward Network),通过堆叠多层 Encoder 和 Decoder 实现序列建模。
整个模型可以分为两个部分:
- Encoder:理解输入序列
- Decoder:逐步生成输出序列
每个部分都由多个重复的模块(Layer)组成,每个 Layer 内部结构非常规范。
二、Encoder 模块拆解
一个 Encoder Layer 通常包括以下结构:
输入 Embedding → 位置编码 → 多头自注意力(Multi-Head Self-Attention)→ 残差连接 + LayerNorm → 前馈全连接层(FFN)→ 残差连接 + LayerNorm
1. 输入 Embedding + 位置编码
- 词嵌入:将离散词 token 转化为连续向量
- 位置编码(Positional Encoding):添加序列中 token 的位置信息,常用 sin/cos 形式
2. 多头自注意力(Multi-Head Self-Attention)
- 每个位置都对所有位置的 token 做注意力计算
- 多头机制可以并行学习不同语义空间的信息
3. 残差连接 + LayerNorm
- 避免深层网络梯度消失
- 加快收敛速度,提高训练稳定性
4. 前馈神经网络(FFN)
- 两层全连接层,中间使用激活函数 ReLU 或 GELU
- 提高模型非线性表达能力
三、Decoder 模块拆解
Decoder Layer 在结构上和 Encoder 类似,但多了一个关键模块:Encoder-Decoder Attention,同时引入了Mask 机制来保证自回归生成。
输入 Embedding → 位置编码 → Masked Multi-Head Self-Attention → 残差连接 + LayerNorm
→ Encoder-Decoder Attention → 残差连接 + LayerNorm
→ FFN → 残差连接 + LayerNorm
1. Masked Multi-Head Self-Attention
- 为了防止"看见未来",只允许当前 token 看到它左边的 token(即因果 Mask)
2. Encoder-Decoder Attention
- 允许 Decoder 访问 Encoder 的输出表示,用于对输入序列进行上下文感知
- 本质也是注意力机制,只不过 Query 来自 Decoder,Key 和 Value 来自 Encoder 输出
四、整体结构图
建议自己画一遍 Transformer 的流程图,从输入 token 到输出结果,包括 Encoder 和 Decoder 各层之间的连接方式。
小提示可以参考以下流程(动手练习!):
[Input Embedding + Pos Encoding] → [N个Encoder Layer 堆叠] → Encoder输出
↓
[Shifted Output Embedding + Pos Encoding] → [N个Decoder Layer 堆叠(含 Mask + Encoder-Decoder Attention)]
↓
[线性层 + Softmax] → 最终预测输出
小测验:请尝试画出这个结构图,并标注出每个模块的主要作用。
五、总结:你需要掌握的关键点
| 模块 | 作用说明 |
|---|---|
| Self-Attention | 获取上下文依赖 |
| Multi-Head Mechanism | 学习多种注意力表示 |
| Positional Encoding | 注入位置信息 |
| FFN | 增强模型表达能力 |
| Residual + LayerNorm | 稳定训练、加快收敛 |
| Masking(Decoder) | 保证生成的因果性 |
| Encoder-Decoder Attention | 对输入序列做条件建模 |
六、后续推荐阅读
- 《Attention is All You Need》原论文
- BERT、GPT、T5 架构演化对比
- Transformer 变体(如:Linformer、Performer、Longformer)
希望这篇文章能帮助你真正"看懂" Transformer 的结构与逻辑。建议动手画一画,理解每一个模块的输入输出关系,构建自己的知识图谱。
你是否已经掌握 Transformer 的全部细节了?不妨挑战一下自己,不看图,能不能完整说出 Encoder 和 Decoder 每一层的结构?
需要我生成一张配套的 Transformer 流程图吗?
七、核心公式与直观解释
1. 自注意力机制(Self-Attention)
公式:
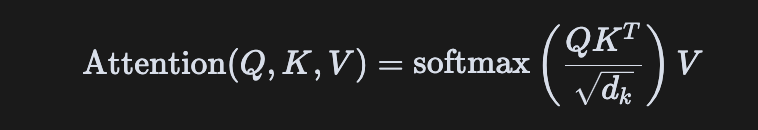
直观理解:每个 token 通过 Query 与所有 token 的 Key 计算相关性分数,Softmax 后加权 Value,动态聚合全局信息。
2. 前馈神经网络(FFN)
- 结构:两层全连接,常用激活函数 ReLU/GELU
- 作用:提升模型的非线性表达能力
3. Mask 机制
- Decoder Masked Attention:用上三角 Mask 保证自回归生成,防止信息泄露
4. Encoder-Decoder Attention
- 作用:让 Decoder 能"读"到 Encoder 的输出,做条件生成
- 本质:Query 来自 Decoder,Key/Value 来自 Encoder
八、配套流程图与交互式可视化代码(Streamlit Demo)
1. 结构流程图建议
建议动手画一遍 Transformer 的流程图,帮助理解各模块的输入输出关系。参考流程如下:
[Input Embedding + Pos Encoding] → [N个Encoder Layer 堆叠] → Encoder输出
↓
[Shifted Output Embedding + Pos Encoding] → [N个Decoder Layer 堆叠(含 Mask + Encoder-Decoder Attention)]
↓
[线性层 + Softmax] → 最终预测输出
你可以用 draw.io、ProcessOn、Visio 等工具绘制,也可以参考下方 Streamlit Demo 的可视化。
2. Streamlit 交互式可视化 Demo 代码
将以下代码保存为 streamlit_transformer_demo.py,在命令行运行 streamlit run streamlit_transformer_demo.py 即可体验:
import streamlit as st
import numpy as np
import matplotlib.pyplot as plt
st.set_page_config(page_title="Transformer Encoder/Decoder 可视化拆解", layout="wide")
st.title("Transformer Encoder/Decoder 结构交互式拆解")
st.markdown("""
> 结合自注意力、前馈网络、Mask 机制等核心模块,交互式理解 Transformer 架构。
""")
tab1, tab2, tab3 = st.tabs(["结构流程图", "模块细节", "自注意力演示"])
with tab1:
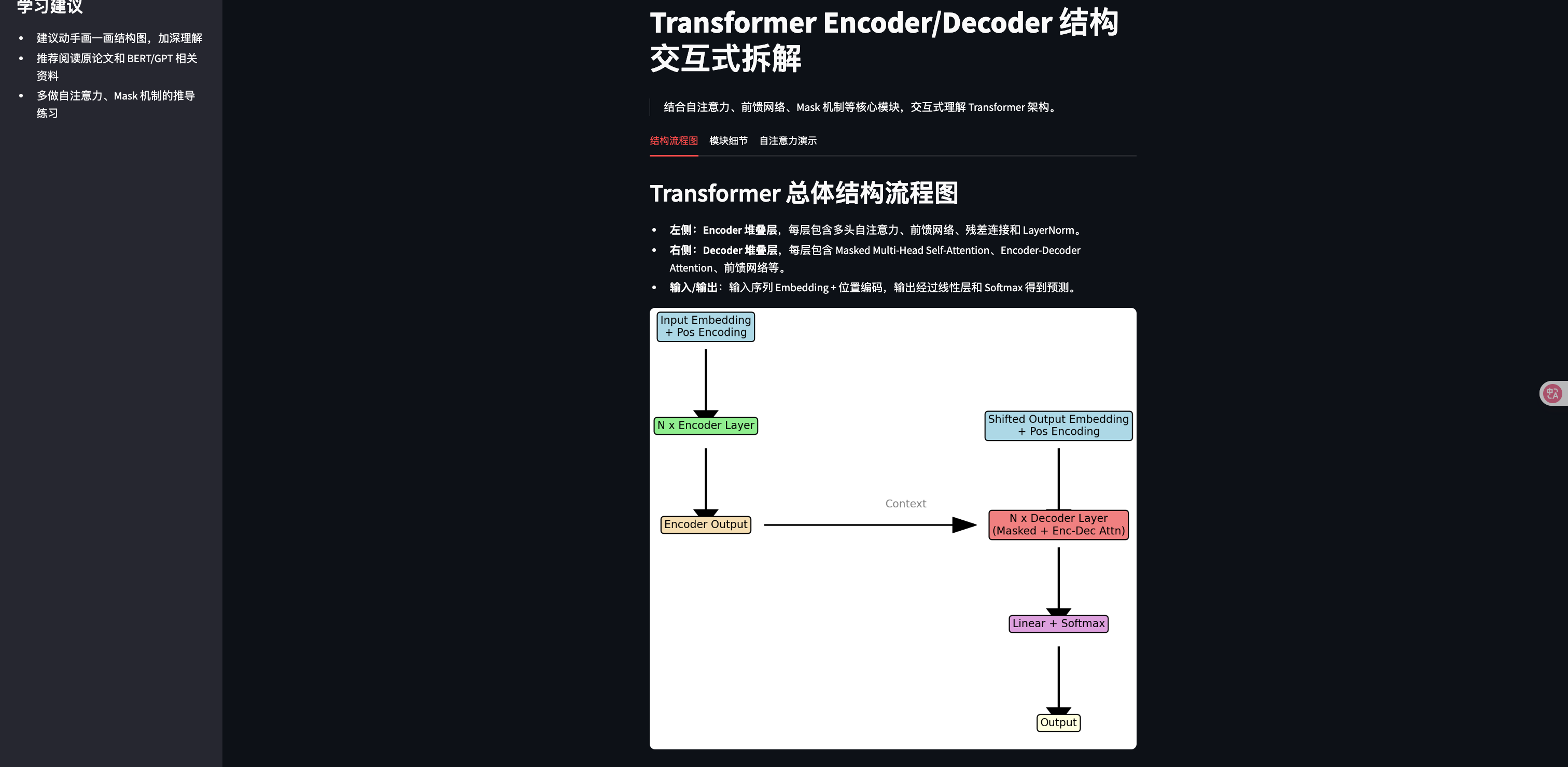
st.header("Transformer 总体结构流程图")
st.markdown("""
- **左侧:Encoder 堆叠层**,每层包含多头自注意力、前馈网络、残差连接和 LayerNorm。
- **右侧:Decoder 堆叠层**,每层包含 Masked Multi-Head Self-Attention、Encoder-Decoder Attention、前馈网络等。
- **输入/输出**:输入序列 Embedding + 位置编码,输出经过线性层和 Softmax 得到预测。
""")
fig, ax = plt.subplots(figsize=(7, 7))
ax.axis('off')
# Encoder部分
ax.text(0.5, 0.95, "Input Embedding\n+ Pos Encoding", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightblue"))
ax.arrow(0.5, 0.92, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')
ax.text(0.5, 0.82, "N x Encoder Layer", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightgreen"))
ax.arrow(0.5, 0.79, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')
ax.text(0.5, 0.69, "Encoder Output", ha='center', va='center', bbox=dict(boxstyle="round", fc="wheat"))
# Decoder部分
ax.text(0.8, 0.82, "Shifted Output Embedding\n+ Pos Encoding", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightblue"))
ax.arrow(0.8, 0.79, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')
ax.text(0.8, 0.69, "N x Decoder Layer\n(Masked + Enc-Dec Attn)", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightcoral"))
ax.arrow(0.8, 0.66, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')
ax.text(0.8, 0.56, "Linear + Softmax", ha='center', va='center', bbox=dict(boxstyle="round", fc="plum"))
ax.arrow(0.8, 0.53, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')
ax.text(0.8, 0.43, "Output", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightyellow"))
# Encoder Output 到 Decoder Layer 的横向箭头
ax.arrow(0.55, 0.69, 0.18, 0, head_width=0.02, head_length=0.02, fc='k', ec='k', length_includes_head=True)
ax.text(0.67, 0.71, "Context", ha='center', va='bottom', fontsize=10, color='gray')
st.pyplot(fig)
with tab2:
st.header("模块细节与原理")
st.markdown("""
### Encoder Layer
- **多头自注意力(Multi-Head Self-Attention)**:每个 token 能关注全局,捕捉长距离依赖。
- **残差连接 + LayerNorm**:防止梯度消失,加快收敛。
- **前馈神经网络(FFN)**:提升非线性表达能力。
### Decoder Layer
- **Masked Multi-Head Self-Attention**:保证生成时不"偷看"未来 token。
- **Encoder-Decoder Attention**:让 Decoder 能访问 Encoder 输出,实现条件生成。
- **残差连接 + LayerNorm、FFN**:同 Encoder。
### 位置编码(Positional Encoding)
- 注入序列顺序信息,常用 sin/cos 公式。
### Mask 机制
- Decoder 中用上三角 Mask,防止信息泄露。
---
**自注意力公式**:
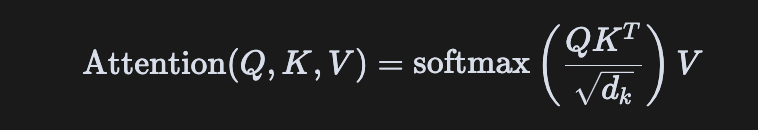
with tab3:
st.header("自注意力分数计算演示")
st.markdown("""
下面你可以输入一组简单的 token 向量,体验自注意力分数的计算过程。
""")
st.markdown("**假设有3个token,每个维度为2**")
tokens = st.text_area("输入token向量(每行一个token,用逗号分隔)", "1,0\n0,1\n1,1")
try:
X = np.array([list(map(float, line.split(','))) for line in tokens.strip().split('\n')])
d_k = X.shape[1]
Q = X
K = X
V = X
attn_scores = Q @ K.T / np.sqrt(d_k)
attn_weights = np.exp(attn_scores) / np.exp(attn_scores).sum(axis=1, keepdims=True)
output = attn_weights @ V
st.write("**Attention 分数矩阵**")
st.dataframe(attn_scores)
st.write("**Softmax 后的权重**")
st.dataframe(attn_weights)
st.write("**输出向量(加权和)**")
st.dataframe(output)
except Exception as e:
st.error(f"输入格式有误: {e}")
st.sidebar.title("学习建议")
st.sidebar.markdown("""
- 建议动手画一画结构图,加深理解
- 推荐阅读原论文和 BERT/GPT 相关资料
- 多做自注意力、Mask 机制的推导练习
""")
---
希望这份补充和可视化 Demo 能帮助你更深入理解 Transformer 架构!如需进一步扩展,欢迎留言交流。
第6讲、全面拆解Encoder、Decoder内部模块的更多相关文章
- 自定义Encoder/Decoder进行对象传递
转载:http://blog.csdn.net/top_code/article/details/50901623 在上一篇文章中,我们使用Netty4本身自带的ObjectDecoder,Objec ...
- 比sun.misc.Encoder()/Decoder()的base64更高效的mxBase64算法
package com.mxgraph.online; import java.util.Arrays; /** A very fast and memory efficient class to e ...
- Netty自定义Encoder/Decoder进行对象传递
转载:http://blog.csdn.net/top_code/article/details/50901623 在上一篇文章中,我们使用Netty4本身自带的ObjectDecoder,Objec ...
- 查看python内部模块命令,内置函数,查看python已经安装的模块命令
查看python内部模块命令,内置函数,查看python已经安装的模块命令 可以用dir(modules) 或者用 pip list或者用 help('modules') 或者用 python -m ...
- nw.js node-webkit系列(15)如何使用内部模块和第三方模块进行开发
原文链接:http://blog.csdn.net/zeping891103/article/details/50786259 原谅原版链接:https://github.com/nwjs/nw.js ...
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
1.主要完成的任务是能够将英文转译为法文,使用了一个encoder-decoder模型,在encoder的RNN模型中是将序列转化为一个向量.在decoder中是将向量转化为输出序列,使用encode ...
- pytoch之 encoder,decoder
import torch import torch.nn as nn import torch.utils.data as Data import torchvision import matplot ...
- PL301 matrix内部模块
ASIB中的valid信号,有两部分,一部分add产生的地址映射,到main中的default addr.(vect) 一部分由Dmu和Cdas组成,到main中的build. Dmu:interco ...
- Mysql架构与内部模块-第一章
Mysql作为大多数中小型企业的首选数据库,也可能是众多同僚接触的第一个数据库,其热门程度不言而喻,一些相对基础的知识本系列不做赘述,主要简述Mysql相关的进阶知识. 本章将由浅入深的讲解从连接My ...
- Mysql架构与内部模块-第三章
前言 接上文,本篇文章专门简述Mysql存储引擎,内容繁多,如果你只需知道每种存储引擎的适用场景,可以直接查看本文最后列出的适用场景部分. 正文: Mysql存储引擎作为本系列文章中相对重要的一环,也 ...
随机推荐
- 宝塔导入mysql数据库后,phpmyadmin可以登录,本地Navicat无法登录
问题描述:宝塔导入mysql数据库后,phpmyadmin可以登录,本地Navicat无法登录 问题排查:1.检查服务器3306端口是否开启,如果为云服务器,需要登录云服务器后台安全组设置开启: 2. ...
- 百万架构师第四十七课:并发编程的原理(二)|JavaGuide
原文链接 JavaGuide <并发编程的艺术> 并发编程的实现原理 目标 上节课内容回顾 synchronized 原理分析 wait 和 notify Lock 同步锁 回顾 原子性 ...
- next.js 添加 PWA 渐进式WEB应用(service-worker) 支持
本文仅作为 next 系列文章中的一部分,其他 next 文章参考: https://blog.jijian.link/categories/nextjs/ 去 github 搜索了一把,估计是我关键 ...
- sourcetree 重新设置git账号密码
设置提交git账号邮箱 到项目根目录,执行 vi ~/.gitconfig ,直接编辑修改即可 重新设置git登陆账号密码 打开 sourcetree 的偏好设置,选择高级,然后移除即可
- codelite常用快捷键积累
博客地址:https://www.cnblogs.com/zylyehuo/ 编译整个工作空间 workplace Ctrl+shift+B 编译当前文件 file Ctrl+F7 编译项目 proj ...
- oracle忘记sys,system密码的解决方法
1. 找到oracle的安装目录: 找到此路径(D:\app\Administrator\product\11.2.0\dbhome_1\BIN),通过sqlplus.exe执行操作命令.(如果提示s ...
- 【Java】基本语法
一.语言概述 整体语言概述 (一)Java语言概述 1.基础常识 软件:即一系列按照特定顺序组织的计算机数据和指令的集合.分为:系统软件 和 应用软件 系统软件:windows , mac os , ...
- 【错误解决】Android APK 方法数量限制
错误:# Cannot fit requested classes in a single dex file (# methods: 74519 > 65536) 最近开发安卓程序遇到以下错误: ...
- 学习unigui【17】-数据集和JSON互相转换-DataSetConverter4D 开源项目
学习unigui过程中,出现使用json和fdquery等数据交换的太多场景要求. 感谢开源DataSetConverter4D提供轮子. 直接抄demo: {Convert DataSet to J ...
- 配置springmvc的springmvc.xml
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...