多云架构,JuiceFS 如何实现一致性与低延迟的数据分发
随着大模型的普及,GPU 算力成为稀缺资源,单一数据中心或云区域的 GPU 资源常常难以满足用户的全面需求。同时,跨地域团队的协作需求也推动了企业在不同云平台之间调度数据和计算任务。多云架构正逐渐成为一种趋势,然而该架构下的数据分发面临一系列挑战。
01 多云架构下的存储挑战
在实际操作中,不少企业在各个云平台自行构建计算 Pod,来处理特定的计算任务并进行数据分发。然而,如何确保这一分发过程的持续性,并将训练结果及时归并,成为了亟待解决的难题。尤其是当数据需要跨地域传输时,性能瓶颈和数据一致性问题尤为突出。
以一个具体场景为例,图中左侧为训练集群,部署于腾讯云,而右侧则为推理集群,位于阿里云。如何将训练集群所生成的模型数据高效地分发至推理集群呢?
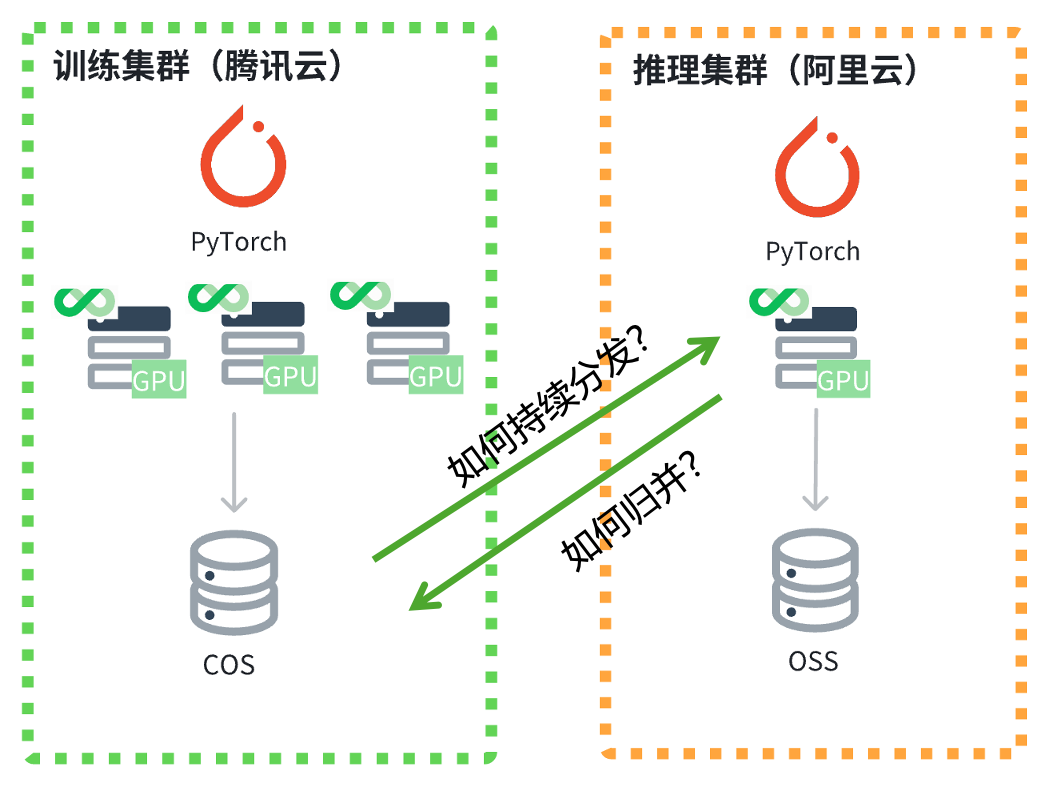
首要问题在于,数据的分发与异地计算难度较大,需用户自行将数据从文件系统层面拷贝至异地,并设定定时定量的策略。
其次,当数据量庞大时,若需全面同步,将耗费大量资源。而热数据往往仅占少数,企业往往难以预知哪些数据为热数据,需在读取后才能确定。因此,按需拷贝而非全面拷贝,并在异地设立本地缓存,既能提升性能,又能兼顾成本。
再者,网络带宽、出错重试等问题可能导致数据不一致。此外,云厂商通常倾向于构建封闭的生态,不愿提供跨云功能,如腾讯云便不会提供工具协助用户将数据拷贝至其他云进行分发。因此,作为云中立的第三方文件系统,我们需提供整体的解决方案,以打破单一云厂商的束缚,满足客户的跨云与多云需求。
02 JuiceFS 跨云、多云解决方案
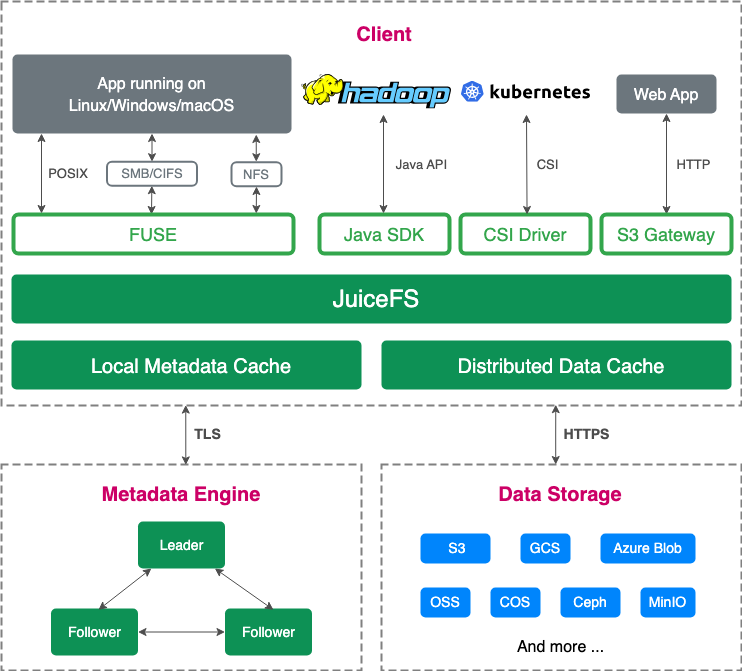
JuiceFS 企业版是基于对象存储的分布式文件系统,相比社区版它提供了更强的元数据引擎和缓存管理能力。针对用户在多云架构中对数据访问性能的不同需求,juiceFS 提供跨区和跨地域的多种方案。
方案 1:同地域、跨云数据分发
该方案是指在同区域的不同云之间进行数据分发,常被应用于数据双活与灾备场景。通过在源区域(下图左上角)与目标区域之间建立异步数据同步关系,系统能够自动将数据从一个区域复制到另一个区域,并保证数据的一致性。
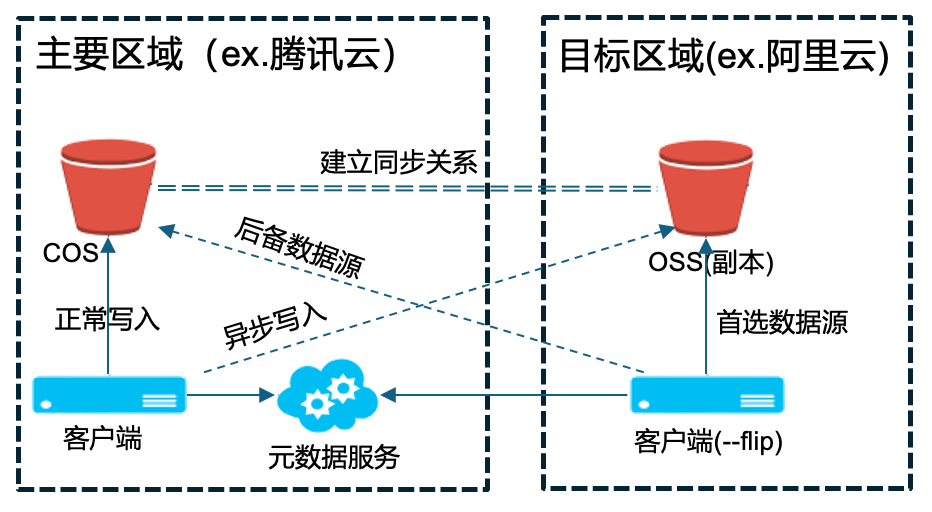
该方案采用共享元数据服务的方式,使得不同区域的客户端可以在挂载文件系统时进行就近写入,优化数据存取效率。异步复制和元数据一致性保证了在不同区域间的数据一致性和稳定性。
数据一致性方面,JuiceFS 的强一致性由元数据保证,文件有变更会在对象存储上追加新的数据块,然后元数据会指向新的数据块,所以只要元数据一致,就能确保整个文件的一致性。因此,当目标客户端访问同一元数据服务时,不存在数据不一致的情况。期间若数据已同步至目标区域存储桶,则直接从该桶读取;若尚未同步,则会回源至源存储桶读取,以确保数据的完整性和一致性。
此方案广泛适用于数据双活和灾备场景。对于数据双活应用,企业可以通过跨区数据复制在多个区域之间共享数据,实现高可用性和负载均衡。
在灾备场景中,该方案通过异步将数据备份到目标区域,避免了因源云平台出现问题(如账号封禁、访问限制等)导致的数据不可用情况。即便源区域发生故障,客户端只需挂载并切换到目标区域即可继续正常工作,数据可以无缝恢复。
方案 2:跨地域数据访问,适用于大规模 AI 训练场景
针对跨地域数据访问的性能挑战,我们提供了多种解决方案以满足不同场景下的需求。
元数据和数据同步
当两地享有共同地域的元数据服务时,数据访问通常不会受到显著延迟影响。然而,当数据需要跨国或跨大洲传输,如从新加坡或美国节点访问时,性能问题可能变得尤为突出,尤其是当涉及大量小文件时。此时,远程数据访问若未命中缓存,可能需要回源区域读取,这将严重影响性能。
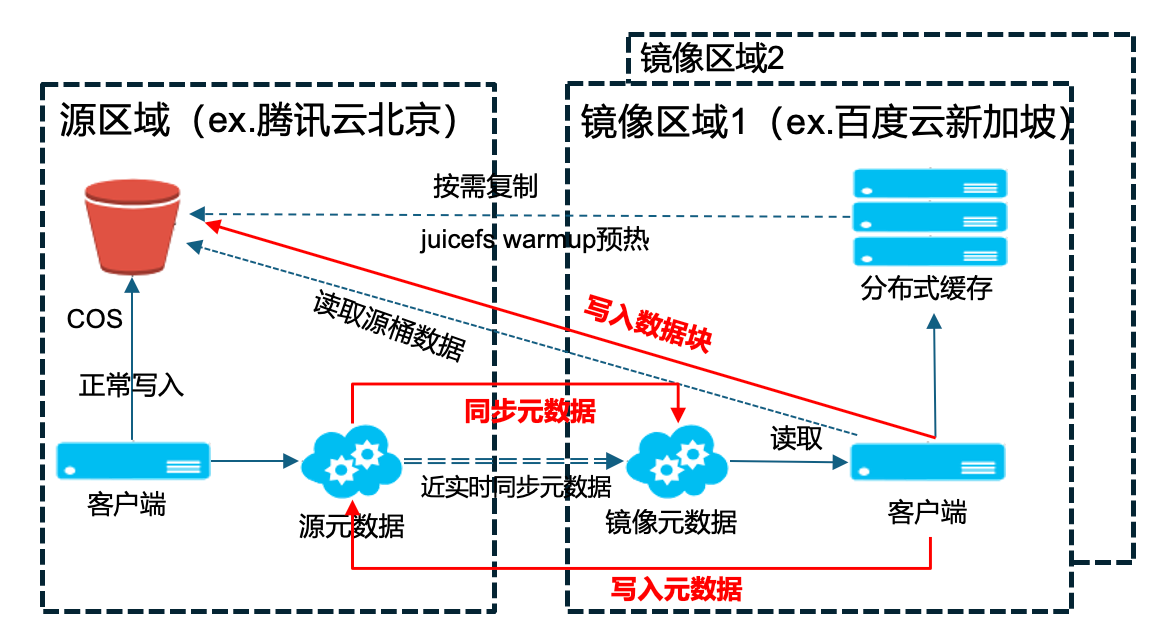
为解决这一问题,我们设计了镜像文件系统功能,该功能通过同步源区域和目标区域(镜像区域)中的数据和元数据,确保两地数据一致性,从而实现跨地域数据的低延迟访问。虽然我们期望实现实时同步,但由于地域间的网络限制,实际上无法做到完全的实时性。
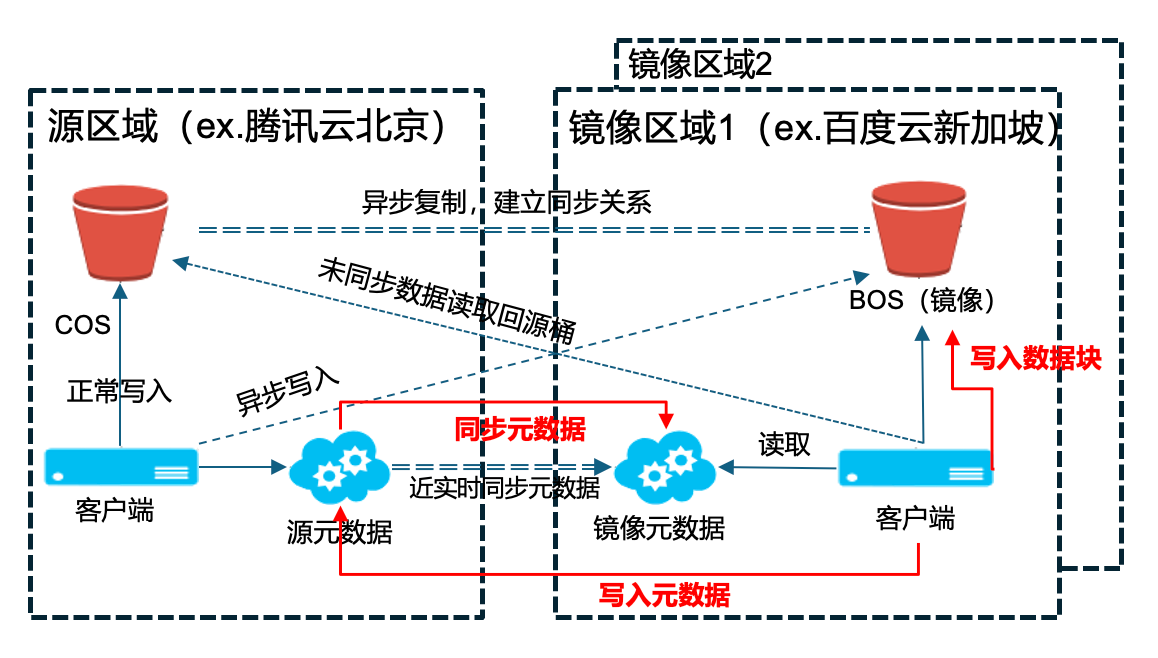
镜像文件系统中的操作流程如下:当源区域的客户端对源区域的存储桶发起读写操作时,会异步地将数据写入镜像区域的存储桶。当镜像区域的客户端在进行训练或推理时,系统将就近从镜像区域读取数据,以减少访问延迟从而提高性能。若数据尚未同步至镜像区域,系统将回源读取。
值得注意的是,在 JuiceFS 5.0 版本之前,镜像区域仅支持读操作;5.0 及之后版本则加入了写操作功能。在进行写操作时,系统先将数据写入镜像区域桶里,再将元数据更新到源区域的元数据服务中(注意:元数据不会直接写入镜像区域)。然后,元数据再按正常流程同步到镜像区域。
这个镜像写入流程看起来有些复杂,但为了确保在各种网络波动情况下同步不会出现错误,我们采用了单向同步的设计,虽然在写入时会承受一定的延迟,但这是为了一致性做出必要的妥协。
仅元数据同步
此外,为了应对大数据量同步时的成本和时间挑战,我们提供了按需同步的方案。用户可以选择仅同步元数据。这与上一种方式的差别就在于避免的全桶复制,虽然缺乏一定数据本地性,但如果分布式缓存有足够命中率,性能仍能得到保障。最为关键的是,这种方式省去了大量时间、复制流量及重复存储的成本。在写入数据时,系统同样将数据写回源区域的存储桶和元数据区域,并同步至镜像区域。通过这样的方式,我们实现了安全、高效的跨地域数据同步和访问。
03 某 LLM 企业腾讯云到阿里云跨云案例(仅元数据同步)
该企业在阿里云上拥有大量闲置的训练 GPU 资源,希望能够将这些资源与腾讯云的训练任务协同使用。因此,企业需要将数据从腾讯云分发到阿里云。然而,由于两者之间网络波动频繁,数据分发受阻,进而影响了训练效率,尤其是在处理大量小文件时,卡顿现象更为明显。
为解决这一问题,企业选择使用 JuiceFS 来支持跨地域的数据分发场景。通过同步元数据, JuiceFS 有效降低了网络波动带来的影响。同时,为了控制成本,企业并未将所有数据同步到阿里云,而是采用分布式缓存,仅按需预热并同步需要的数据,从而在保证性能的同时优化了成本。
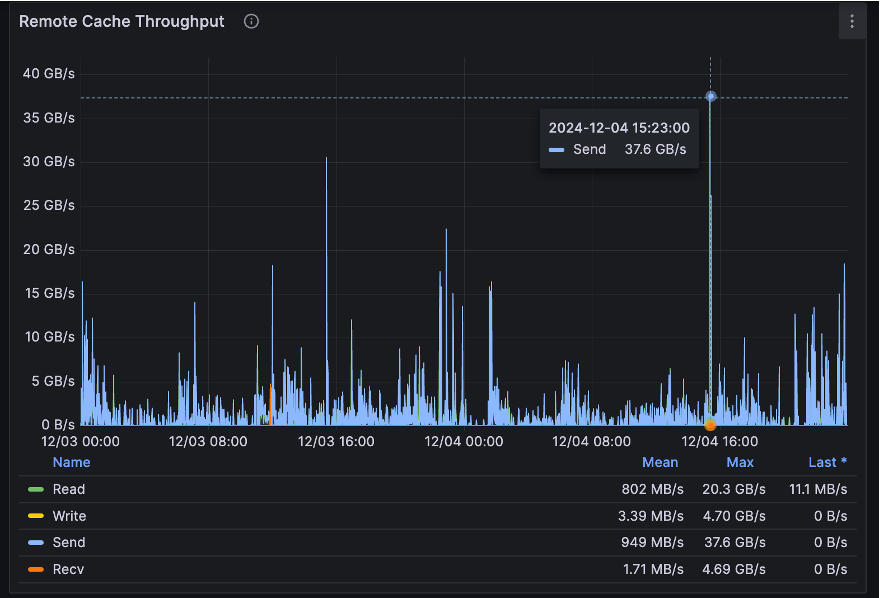
目前,镜像文件系统的大小约为 256TB,文件数量达到 1300 万个,平均文件大小约为18.6MB。阿里云客户端在镜像区域的数量达到 540 个,有大量的训练容器协助腾讯云进行训练。阿里云端元数据的 QPS 已达到 5.81 万次。尽管分布式缓存节点数量为 138 个,缓存容量仅为 8.8TB,但通过足够的节点数量和网卡数量,系统能够聚合出较大的带宽,缓存的最大读取吞吐量为 37GB/s,写入吞吐量为 4GB/s,能够满足该场景的性能要求。
03 小结
针对用户在多云架构中对数据访问性能的不同需求,JuiceFS 从第三方云中立的角度提供完整的解决方案,不捆绑任何特定云平台。
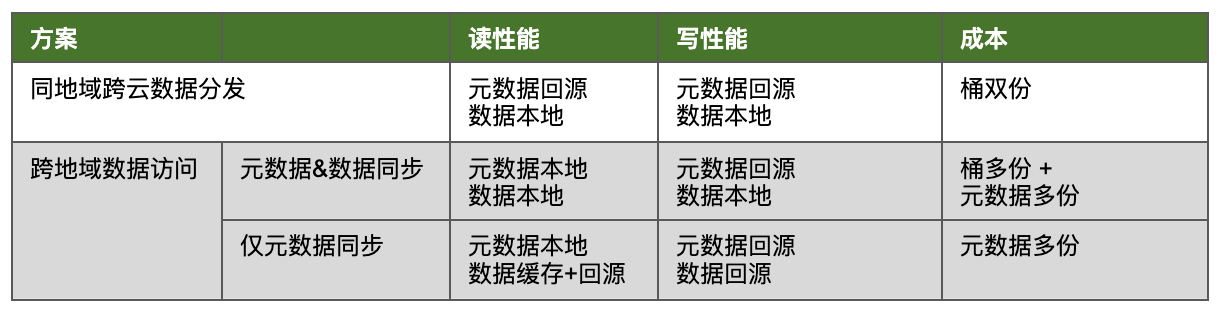
- 方案 1:同地域跨云数据分发
- 适用于两地距离相对较近、数据通信稳定的场景,同时也适用于跨云桶数据灾备的解决方案。
- 方案 2:跨地域数据访问
- 数据与元数据均同步。此方案支持多份数据同步,尤其适用于地域相隔较远的场景。其优势在于读取性能最佳,因为元数据和数据均可从本地读取。然而,这也带来了最高的成本。
- 仅元数据同步:兼顾成本与性能的折衷方案。元数据从本地读取,而数据则按需从缓存中读取;若缓存未命中,则回源读取。然而,其写入性能相对一般,因为无论是数据还是元数据,均需回源写入。此方案尤其适用于对成本敏感且镜像区域大量数据为只读的场景。
多云架构,JuiceFS 如何实现一致性与低延迟的数据分发的更多相关文章
- 使用Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
近年来出现了从单体架构向微服务架构的转变.微服务架构使应用程序更容易扩展和更快地开发,支持创新并加快新功能上线时间.但是这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难.为了获得更深入和更 ...
- 多云架构下,JAVA微服务技术选型实例解析
[摘要] 本文介绍了基于开源自建和适配云厂商开发框架两种构建多云架构的思路,以及这些思路的优缺点. 微服务生态 微服务生态本质上是一种微服务架构模式的实现,包括微服务开发SDK,以及微服务基础设施. ...
- PrismCDN 网络的架构解析,以及低延迟、低成本的奥秘
5 月 19.20 日,行业精英齐聚的 WebRTCon 2018 在上海举办.又拍云 PrismCDN 项目负责人凌建发在大会做了<又拍云低延时的 WebP2P 直播实践>的精彩分享. ...
- QQ视频直播架构及原理 流畅与低延迟之间做平衡 音画如何做同步?
QQ视频直播架构及原理 - tianyu的专栏 - CSDN博客 https://blog.csdn.net/wishfly/article/details/53035342 作者:王宇(腾讯音视频高 ...
- 翟佳:高可用、强一致、低延迟——BookKeeper的存储实现
分享嘉宾:翟佳 StreamNative 联合创始人 编辑整理:张晓伟 美团点评 出品平台:DataFunTalk 导读:多数读者们了解BookKeeper是通过Pulsar,实际上BookKeepe ...
- 一款低延迟的分布式数据库同步系统--databus
每次看到马路对面摩托罗拉的大牌子,都想起谷歌125亿美元收购摩托罗拉移动,后来又以29亿美元卖给联想的事情.谷歌所做的决策都比较考虑长远利益,在这串交易中,谷歌获得了摩托罗拉最有价值的几千项专利,稳健 ...
- 高吞吐低延迟Java应用的垃圾回收优化
高吞吐低延迟Java应用的垃圾回收优化 高性能应用构成了现代网络的支柱.LinkedIn有许多内部高吞吐量服务来满足每秒数千次的用户请求.要优化用户体验,低延迟地响应这些请求非常重要. 比如说,用户经 ...
- 转: 低延迟系统的Java实践
from: http://blog.csdn.net/jacktan/article/details/41177779 在很久很久以前,如果有人让我用Java语言开发一个低延迟系统,我肯定会用迷茫的 ...
- 学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端—— AI 应用的系统需求:支持(a)异质、并行计算,(b)动态任务图,(c)高吞吐量和低延迟的调度,以及(d)透明的容错性。
学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端 from:https://baijia.baidu.com/s?id=1587367874517247282&wfr ...
- 在Chrome、Firefox等高版本浏览器中实现低延迟播放海康、大华RTSP
一.背景 现在到处是摄像头的时代,随着带宽的不断提速和智能手机的普及催生出火热的网络直播行业,新冠病毒的大流行又使网络视频会议系统成为商务会议的必然选择,因此RTSP实时视频流播放及处理不再局限于安防 ...
随机推荐
- 电脑端 itunes 备份保存路径修改方法
默认在c盘,重做系统就会丢失. 1.先删除C:\Users\你的用户名\AppData\Roaming\Apple Computer里的 MobileSync文件夹(首次安装iTunes没有,要先运行 ...
- web上线部署系统 Walle
Walle瓦力是基于git和rsync实现的一个web部署系统工具. 用户分身份注册.登录 开发者发起上线任务申请 管理者审核上线任务 支持多项目部署 快速回滚 部署前准备任务(前置检查) 代码检出后 ...
- 5.6 Linux Vim撤销和恢复撤销快捷键
使用 Vim 编辑文件内容时,经常会有如下 2 种需求: 对文件内容做了修改之后,却发现整个修改过程是错误或者没有必要的,想将文件恢复到修改之前的样子. 将文件内容恢复之后,经过仔细考虑,又感觉还是刚 ...
- 洛谷P4913【深基16.例3】二叉树深度题解
很简单的二叉树遍历问题,可以用dfs(深度优先搜索)解决. 看到数据范围,最大不超过 \(10^6\) ,可以不开 long long (但我还是习惯性地开了) 接下来上代码: #include< ...
- 鸿蒙NEXT开发案例:血型遗传计算
[引言] 血型遗传计算器是一个帮助用户根据父母的血型预测子女可能的血型的应用.通过选择父母的血型,应用程序能够快速计算出孩子可能拥有的血型以及不可能拥有的血型.这个过程不仅涉及到了简单的数据处理逻辑, ...
- .NET Core 异步(Async)底层原理浅谈
简介 多线程与异步是两个完全不同的概念,常常有人混淆. 异步 异步适用于"IO密集型"的场景,它可以避免因为线程等待IO形成的线程饥饿,从而造成程序吞吐量的降低. 其本质是:让线程 ...
- 用VuePress在GitHub Pages上搭建博客
请先点击链接RobinDevNotes,体验用VuePress搭建博客的效果(logo还没有合适的替换),目前部署在GitHub Pages上,国内访问速度还可以,再阅读本文感受来龙去脉和搭建过程. ...
- 阿里巴巴LangEngine开源了!支撑亿级网关规模的高可用Java原生AI应用开发框架
LangEngine作为阿里集团内部发起的纯Java版本的AI应用开发框架,经过充分实践,已经广泛应用于包括淘宝.天猫.阿里云.爱橙科技.菜鸟.蚂蚁.飞猪.1688.LAZADA等在内的多个业务场景. ...
- 揭秘“山姆黄牛”背后的技术逻辑:用Java实现会员管理系统的防黄牛策略
在浙江绍兴的山姆超市外,"黄牛"现象引发了广泛关注.这些"黄牛"通过提供带入和结账服务,让未办理会员卡的消费者也能进入超市购物.这一行为不仅扰乱了市场秩序,也对 ...
- IOS快捷指令代码分享
IOS快捷指令分享 制作快捷指令 首先在快捷指令APP上制作快捷指令 添加一些逻辑,具体可以自己体验 然后点击共享,获取iCloud链接 类似于这种 https://www.icloud.com/sh ...