大数据计算引擎 EasyMR 如何简单高效管理 Yarn 资源队列
设想一下,作为一个开发人员,你现在所在的公司有一套线上的 Hadoop 集群。A部门经常做一些定时的 BI 报表,B部门则经常使用软件做一些临时需求。那么他们肯定会遇到同时提交任务的场景,这个时候到底应该如何分配资源满足这两个任务呢?是先执行A的任务,再执行B的任务,还是同时跑两个?
如果你存在上述的困惑,可以多了解一些 Yarn 的资源调度器。
Yarn 的三种调度器
从 Hadoop2 开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。Yarn 作为一款 Hadoop 集群的资源共享,不仅可以跑 MapReduce,还可以跑 Spark,Flink。
在 Yarn 框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用在同一时间有条不紊的工作。
最原始的调度规则就是 FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待,也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。所以 FIFO 虽然很简单,但是并不能满足我们的需求。
如下图所示,在 Yarn 中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
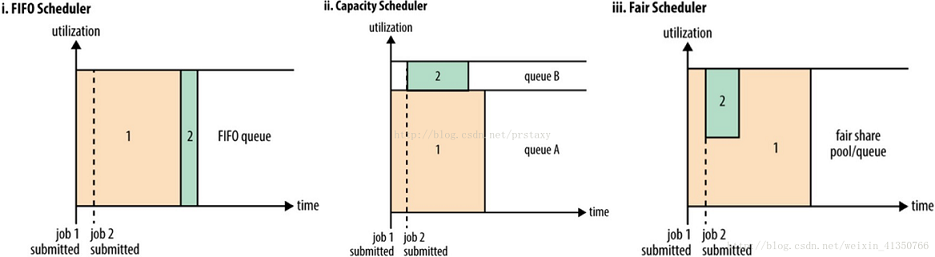
FIFO Scheduler
把应用按提交的顺序排成一个先进先出队列,在进行资源分配的时候,先给队列中最头部的应用进行分配资源,等到最头部的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler 是最简单也是最容易理解的调度器,它不需要任何配置,但不适用于共享集群中。大的应用可能会占用所有集群资源,从而导致其它应用被阻塞。
Capacity 调度器
允许多租户安全的共享集群资源,提供的核心理念就是 Queues(队列),它支持多个队列,每个队列可配置一定的资源量,以确保在其他 queues 允许使用空闲资源之前,资源可以在一个组织的 sub-queues 之间共享,且每个队列采用 FIFO 调度策略。为了在共享资源上,提供更多的控制和预见性,applications 在容量限制之下,可以及时的分配资源。
Fair 调度器
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是 Fair 调度器既得到了高的资源利用率又能保证小任务及时完成。
EasyMR 如何管理 Yarn 资源队列
最原始的调度规则就是 FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样可能会导致一个大任务独占资源,其他的资源需要不断的等待,也可能导致一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。
所以 FIFO 虽然很简单,但是并不能满足我们的需求。最常使用的是容量调度策略,但是运维人员在配置容量队列时,需要考虑队列资源利用率,队列的状态,修改完成后,亦无法校验配置是否正确。
以容量调度为例,为大家简单演示 EasyMR中队列的使用。假设公司有个大数据部门,该部门下有个做数据同步的小组,队列树形图如下:
root
├── bigdata
|---dataSync
要创建这样层次的队列,首先需要在父级别下面创建 bigdata 队列,然后在 bigdata 下面划分一个子队列 dataSync,下文进行详细介绍。
创建队列
首先创建父队列 bigdata,设置最小容量20%,最大容量50%。
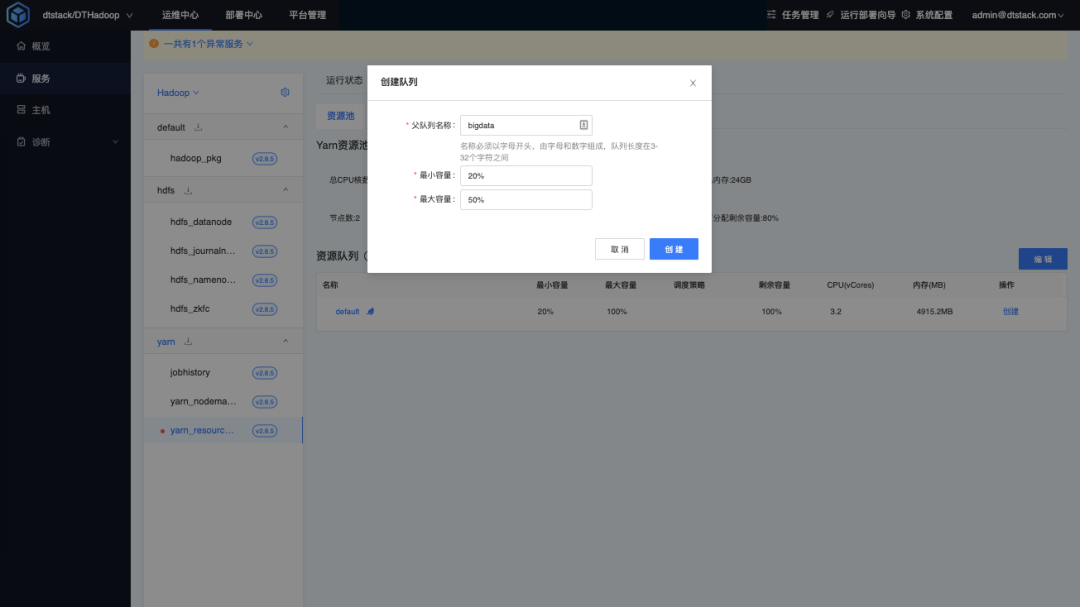
在父队列中添加 bigdata 队列名称。
<property>
<!-- root队列中有哪些子队列-->
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,bigdata</value>
<description></description>
</property>
设置 bigdata 的容量调度配置。
<property>
<!-- bigdata队列占用的容量百分比-->
<name>yarn.scheduler.capacity.root.bigdata.capacity</name>
<value>20</value>
<description></description>
</property>
<property>
<!-- root队列中bigdata队列占用的容量百分比的最大值-->
<name>yarn.scheduler.capacity.root.bigdata.maximum-capacity</name>
<value>50</value>
<description></description>
</property>
<property>
<!-- queue容量的倍数,用来设置一个user可以获取更多的资源。默认值为1-->
<name>yarn.scheduler.capacity.root.bigdata.user-limit-factor</name>
<value>1</value>
<description></description>
</property>
<property>
<!--设置bigdata队列的状态-->
<name>yarn.scheduler.capacity.root.bigdata.state</name>
<value>RUNNING</value>
<description></description>
</property>
创建子队列
在 bigdata 父队列下面,选择创建子队列,设置最小容量10%,最大容量30%。
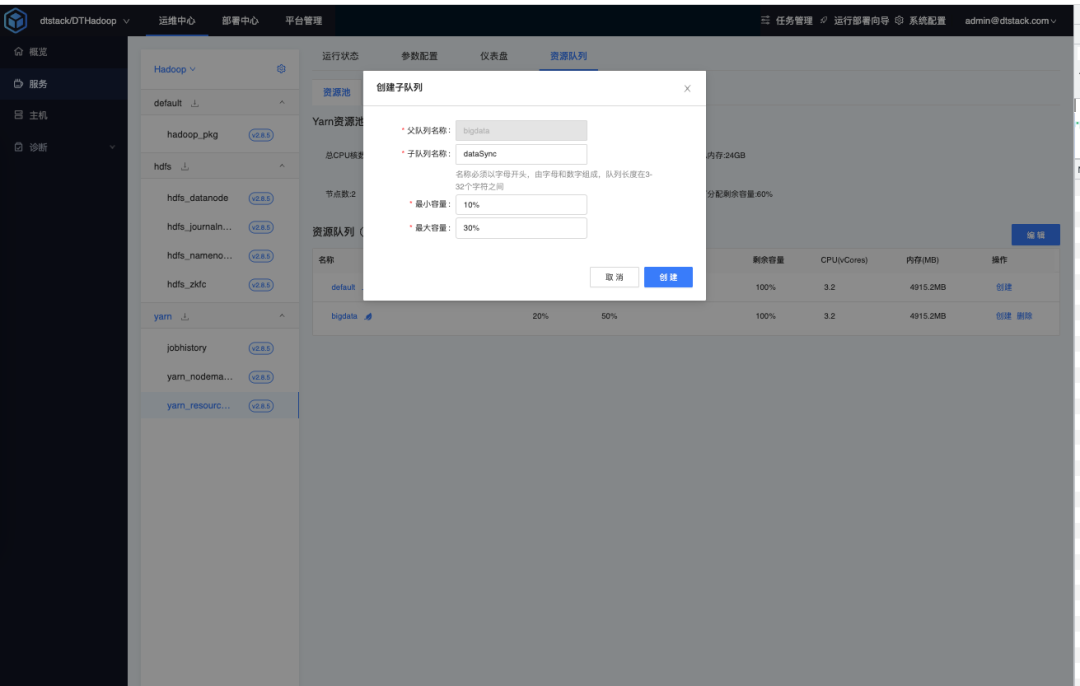
在 bigdata 队列中添加 dataSync 队列名。
<property>
<!-- bigdata队列中有哪些子队列-->
<name>yarn.scheduler.capacity.root.bigdata.queues</name>
<value>dataSync</value>
<description></description>
</property>
设置 dataSync 队列的容量调度配置。
<property>
<!-- bigdata队列dataSync子队列的容量百分比-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.capacity</name>
<value>10</value>
<description></description>
</property>
<property>
<!-- bigdata队列中bigdata队列占用的容量百分比的最大值-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.maximum-capacity</name>
<value>30</value>
<description></description>
</property>
<property>
<!-- queue容量的倍数,用来设置一个user可以获取更多的资源。默认值为1-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.user-limit-factor</name>
<value>1</value>
<description></description>
</property>
<property>
<!--设置子队列dataSync队列的状态-->
<name>yarn.scheduler.capacity.root.bigdata.dataSync.state</name>
<value>RUNNING</value>
<description></description>
</property>
查看队列
创建完成后,可以在 EasyMR 资源队列查看队列详情。
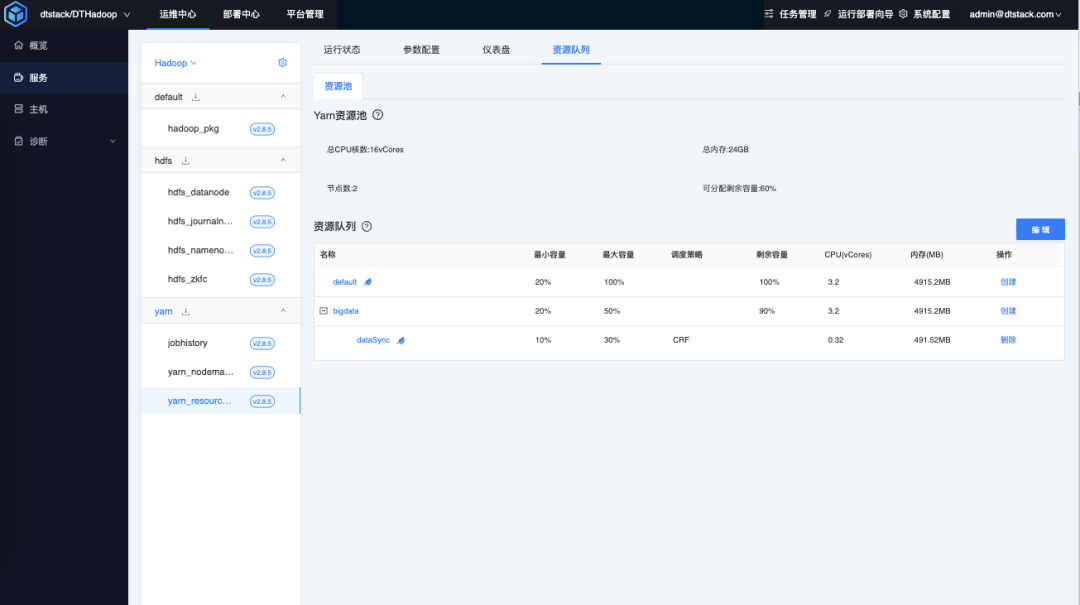
在 EasyMR 创建完成后,也可以在 yarn web 管理页面查看队列创建详情。
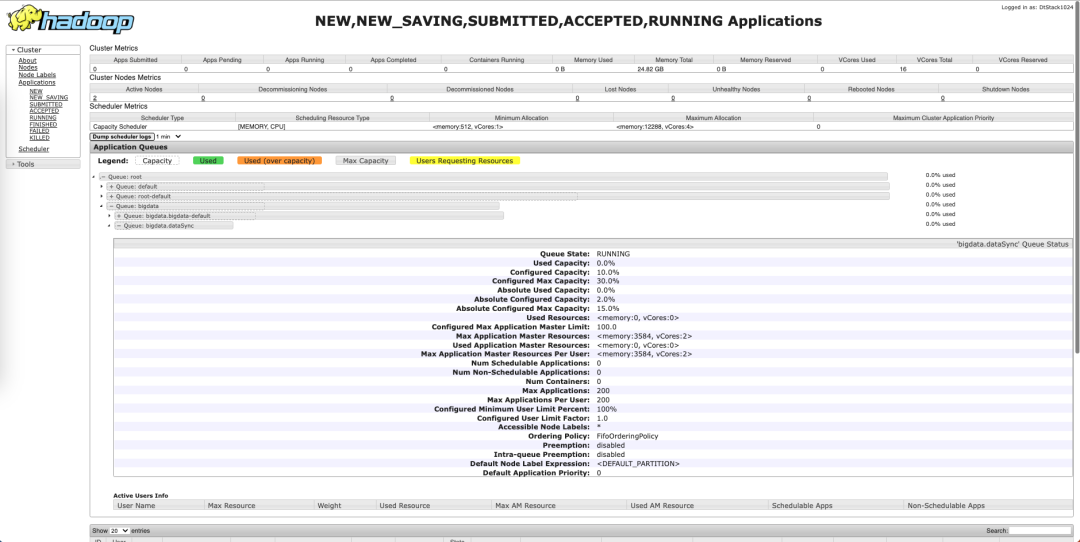
至此,Yarn 的一个简单容量调度就创建完成了。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
大数据计算引擎 EasyMR 如何简单高效管理 Yarn 资源队列的更多相关文章
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- 大数据计算引擎之Flink Flink CEP复杂事件编程
原文地址: 大数据计算引擎之Flink Flink CEP复杂事件编程 复杂事件编程(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的时事件系序列库,并 ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 大数据计算:如何仅用1.5KB内存为十亿对象计数
大数据计算:如何仅用1.5KB内存为十亿对象计数 Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce. 虽然现在通过框架的不 ...
- 开发一个不需要重写成Hive QL的大数据SQL引擎
摘要:开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL. 本文分享自华为云社区< ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
随机推荐
- UNIX 系统
UNIX 系统的历史,UNIX 是操作系统的开山鼻祖,是操作系统的发源地,后来的 Windows 和 Linux 都参考了 UNIX. 有人说,这个世界上只有两种操作系统: UNIX 和类 UNIX ...
- 2025年3月GESP八级真题解析
第一题--上学 题目描述 C 城可以视为由 \(n\) 个结点与 \(m\) 条边组成的无向图.这些结点依次以 \(1,2,-,n\) 标号,边依次以 \(1,2,-,m\) 标号.第 \(i\) 条 ...
- HTML5
转
贴个图:
- sql server2008r2其中一张表不能任何操作
用户的数据库一张高频表,使用select count(*) from t1 竟然一直在转圈,显示开始,而没有end. 找尽原因不得果.把数据库备份后在恢复,可以使用几小时,之后又是老毛病抽风. 用户生 ...
- zk基础—5.Curator的使用与剖析
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curat ...
- nohup启动jar包
1. 后台启动jar包,并追加日志到日志文件run.log nohup java -jar wash-1.0-SNAPSHOT.jar >> run.log 2>&1 &am ...
- Linux使用.net core
Linux使用.net core .wiz-editor-body .wiz-code-container { position: relative; padding: 8px 0; margin: ...
- webapi里调用grpc
参照:ASP .NET Core 6.0使用Grpc配置服务和调用服务_asp.net core grpc 服务-CSDN博客 demo:https://files.cnblogs.com/files ...
- .NET Core短信验证(分布式session)
一.手机短信验证码登录过程 1.构造手机验证码,需要生成一个6位的随机数字串: 2.找短信平台获取使用接口向短信平台发送手机号和验证码,然后短信平台再把验证码发送到制定手机号上 3.将手机号验证码.操 ...
- 通达OA前台任意用户登录漏洞+RCE漏洞复现
声明 本文仅用于技术交流,请勿用于非法用途 由于传播.利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任. 文章作者拥有对此文章的修改和解释权.如 ...