Tomcat 源码分析(转)
本文转自:http://blog.csdn.net/haitao111313/article/category/1179996
Tomcat源码分析(一)--服务启动
1. Tomcat主要有两个组件,连接器和容器,所谓连接器就是一个http请求过来了,连接器负责接收这个请求,然后转发给容器。容器即servlet容器,容器有很多层,分别是Engine,
Host,Context,Wrapper。最大的容器Engine,代表一个servlet引擎,接下来是Host,代表一个虚拟机,然后是Context,代表一个应用,Wrapper对应一个servlet。从连接器
传过来连接后,容器便会顺序经过上面的容器,最后到达特定的servlet。要说明的是Engine,Host两种容器在不是必须的。实际上一个简单的tomcat只要连接器和容器就可以了,
但tomcat的实现为了统一管理连接器和容器等组件,额外添加了服务器组件(server)和服务组件(service),添加这两个东西的原因我个人觉得就是为了方便统一管理连接器和
容器等各种组件。一个server可以有多个service,一个service包含多个连接器和一个容器,当然还有一些其他的东西,看下面的图就很容易理解Tomcat的架构了:
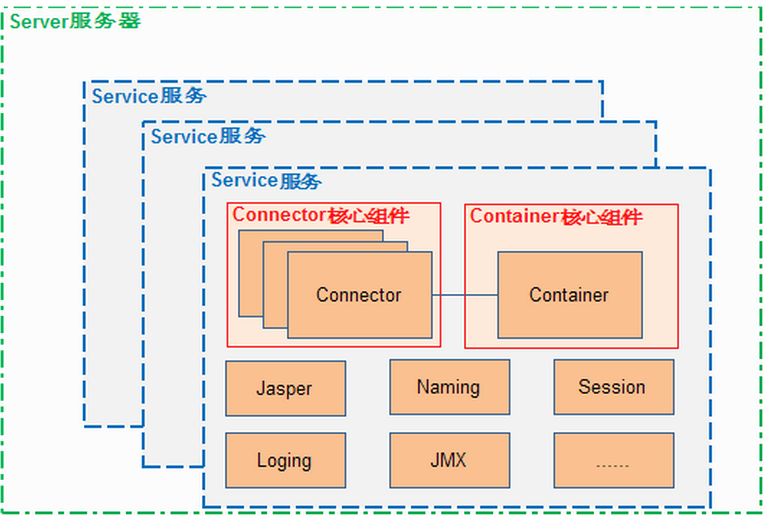
2. 一个父组件又可以包含多个子组件,这些被统一管理的组件都实现了Lifecycle接口。只要一个组件启动了,那么他的所有子组件也会跟着启动,比如一个server启动了,它的所有子
service都会跟着启动,service启动了,它的所有连接器和容器等子组件也跟着启动了,这样,tomcat要启动,只要启动server就行了,其他的组件都会跟随着启动
3. 一般启动Tomcat会是运行startup.bat或者startup.sh文件,实际上这两个文件最后会调用org.apache.catalina.startup.Bootstrap类的main方法,这个main方法主要做了两件事情,
1:定义和初始化了tomcat自己的类加载器,2:通过反射调用了org.apache.catalina.startup.Catalina的process方法;
4. process方法的功能也很简单,1:如果catalina.home和catalina.base两个属性没有设置就设置一下,2:参数正确的话就调用execute方法,execute的方法就是简单的调用start方法,
其中在判断参数正确的方法arguments中会设置starting标识为true,这样在execute方法中就能调用start方法,start方法是重点,在它里面启动了我们的Tomcat所有的服务
5. 这里最重要的方法是createStartDigester();和((Lifecycle) server).start();createStartDigester方法主要的作用就是帮我们实例化了所有的服务组件包括server,service和connect,至于
怎么实例化的等下再看,start方法就是启动服务实例了。File file = configFile();是新建server.xml文件实例,后面的服务组件都是要根据这个文件来的
6. Digester是一个外部jar包里面的类,主要的功能就是解析xml里面的元素并把元素生成对象,把元素的属性设置成对象的属性,并形成对象间的父子兄弟等关系。
Digester.addObjectCreate("Server", "org.apache.catalina.core.StandardServer", "className");//创建一个org.apache.catalina.core.StandardServer对象,实际上这里并没有真正
创建出一个对象,而是添加一个模式,只是后面创建的对象是根据这些模式和server.xml来的,所以可以暂时这么理解。真正创建对象是在start方法里面的digester.parse(is),is是
server.xml文件的流,digester刚才已经添加了StandardServer和StandardService等服务组件,也添加了StandardServer和StandardService的关系以及StandardService和连接器
HttpConnector,容器StandardHost的关系,所以调用digester.parse(is)方法后就会根据模式和server.xml文件来生成对象以及他们之间的相互关系。这样我们便有了服务器组件
StandardServer的对象,也有了它的子组件StandardService对象等等
7. 既然有了服务器组件的对象,就初始化然后启动就可以了,到此,tomcat就实现了启动服务器组件StandardServer。启动后做的事情就东西比较多,但是还是比较清晰的,
StandardServer的start方法关键代码是启动它的子组件StandardService。StandardService的start方法跟StandardServer的start方法差不多,是启动它的连接器和容器,上面说了一个
Service包含一个容器和多个连接器
8. 默认的连接器是HttpConnector,所以会调用HttpConnector的start方法。这里有个两个关键的类:HttpConnector和HttpProcessor,它们都实现了Runnable接口,HttpConnector
负责接收http请求,HttpProcessor负责处理由HttpConnector接收到的请求。注意这里HttpProcessor会有很多的实例,最大可以有maxProcessor个,初始化是20个。所以在
threadStart方法中会启动一个后台线程来接收http连接
9. 这样,就会启动HttpConnector后台线程,它的run方法不断循环,主要就是新建一个ServerSocket来监听端口等待连接。serverSocket一直等待连接,得到连接后给HttpProcessor
的实例processor来处理,serverSocket则继续循环监听,至于processor具体怎么处理,还有很多要说,这里先不说。
Tomcat源码分析(二)--连接处理
1. 在上一节里已经启动了一个HttpConnector线程,并且也启动了固定数量的HttpProcessor线程。HttpConnector用来等待http连接,得到http连接后交给其中的一个HttpProcessor
线程来处理。接下里具体看一下HttpConnector是怎么得到连接得,以及HttpProcessor是怎么处理的
2. 这里很关键的就是socket = serverSocket.accept();和processor.assign(socket); 在循环里面内,serverSocket.accept();负责接收http请求然后赋值给socket,最后交给其中一个processor
处理。这里processor并不是等到需要的时候再实例化,而是在HttpConnector初始化的时候已经有了若干个processor。httpConnector里面持有一个包含HttpProcessor对象的栈,需要的
时候拿出来就是了。
3. 接下来由processor.assign(socket); 记住这个方法是异步的,不需要等待HttpProcessor来处理完成,所以HttpConnector才能不间断的传入Http请求
4. 很明显,在它的run方法一开始便是调用上面的await方法来等待(因为一开始available变量为false),所以HttpProcessor会一直阻塞,直到有线程来唤醒它。当从HttpConnector中调用
processor.assign(socket),会把socket传给此HttpProcessor对象,并设置available为true,调用notifyAll()唤醒该processor线程以处理socket。同时,在await方法中又把available
设置成false,因此又回到初始状态,即可以重新接受socket。这里处理socket的方法是process(socket),主要作用有两点,1:解析这个socket,即解析http请求,包括请求方法,请求协议等,以
填充request,response对象(是不是很熟悉,在servlet和jsp开发经常用到的request,response对象就是从这里来的)。2:传入request,response对象给和HttpConnector绑定的容器,让容器来
调用invoke方法进行处理。
5. 在那些parse××方法里面会对request,response对象进行初始化,然后调用容器的invoke方法进行处理,至此,http请求过来的连接已经完美的转交给容器处理,容器剩下的问题就是要最终转
交给哪个servlet或者jsp的问题。前面我们知道,一个连接会跟一个容器相连,一个级别大的容器会有一个或者多个子容器,最小的容器是Wrapper,对应一个servlet,在这里我们只要知道请求的
路径决定了最终会选择哪个wrapper,wrapper最终会调用servlet的。至少一开始提出来的问题已经明白了。
Tomcat源码分析(三)--连接器是如何与容器关联的?
这篇文章要弄懂一个问题,我们知道,一个链接器是跟一个容器关联的,容器跟链接器是在什么时候关联上的?
1. 在明白这个问题前要先了解一下Digester库,这个库简单的说就是解析xml文件,这里有两个概念:模式和规则,所谓模式就是一个xml的标签,规则就是遇到一个xml标签需要做什么,看一下他主要的三个方法:
addObjectCreate(String pattern, String className, String attributeName) 根据模式pattern实例化一个对象className
addSetProperties(String pattern) 设置这个模式的属性
addSetNext(String pattern, String methodName, String paramType) 添加模式之间的关系,调用父模式的
上面可能不好理解,看tomcat是怎么用到Digester的,在org.apache.catalina.startup.Catalina.createStartDigester()的方法里,在这个方法里有使用Digester来解析server.xml文件
2. 遇到标签Server/Service/Connector的时候(这里简化了说法,应该是标签Server下的子标签Service的子标签Connector,有点拗口),实例化HttpConnector,然后在它的上一级父容器StandardService
下调用addConnector,这样就把链接器HttpConnector添加进容器StandardService下了
3. 把一个链接器connector添加到StandardService的connectors数组里,然后关联上StandardService的容器
4. 当我们调用了digester.addRuleSet(new EngineRuleSet("Server/Service/"));方法,Digester便会自动调用到EngineRuleSet类的addRuleInstances方法,在方法里面无非也是添加各种模式和规则,
根据上面的添加规则,很容易知道这里又添加了一个StandardEngine对象(容器),然后又在该模式的上一级模式Server/Service添加StandardEngine跟StandardService的关系,即通过setContainer
方法把容器添加进StandardService里。
5. 把容器设置到StandardService下,在“同步代码块”处,把容器和链接器关联上了,至此,容器和链接器就关联上了。
Tomcat源码分析(四)--容器处理链接之责任链模式
1. connector.getContainer()得到的容器应该是StandardEngine(其实应该是由server.xml文件配置得到的,这里先假定是StandardEngine),StandardEngine没有invoke方法,它继承与
ContainerBase(事实上所有的容器都继承于ContainerBase,在ContainerBase类有一些容器的公用方法和属性)
2. 由代码可知ContainerBase的invoke方法是传递到Pipeline,调用了Pipeline的invoke方法。这里要说一下Pipeline这个类,这是一个管道类,每一个管道类Pipeline包含数个阀类,阀类是
实现了Valve接口的类,Valve接口声明了invoke方法。管道和阀的概念跟servlet编程里面的过滤器机制非常像,管道就像过滤器链,阀就好比是过滤器。不过管道中还有一个基础阀的概念,
所谓基础阀就是在管道中当管道把所有的普通阀都调用完成后再调用的。不管是普通阀还是基础阀,都实现了Value接口,也都继承于抽象类ValveBase。在tomcat中,当调用了管道的
invoke方法,管道则会顺序调用它里面的阀的invoke方法。
3. 其中StandardPipelineValveContext是管道里的一个内部类,内部类的作用是帮助管道顺序调用阀Value的invoke方法
内部类StandardPipelineValveContext的invokeNext方法通过使用局部变量来访问下一个管道数组,管道类的变量stage保存当前访问到第几个阀,valves保存管道的所有阀,在调用普通阀的
invoke方法是,会把内部类StandardPipelineValveContext本身传进去,这样在普通阀中就能调用invokeNext方法以便访问下一个阀的invoke方法
4. 这个阀的invoke方法,通过传进来到StandardPipelineValveContext(实现了ValveContext接口)的invokeNext方法来实现调用下一个阀的invoke方法。然后简单的打印了请求的ip地址。
最后再看StandardPipelineValveContext的invokeNext方法,调用完普通阀数组valves的阀后,开始调用基础阀basic的invoke方法,这里先说基础阀的初始化,在每一个容器的构造函数类就已经
初始化了基础阀。即在容器构造的时候就已经把基础阀添加进管道pipeline中,这样在StandardPipelineValveContext中的invokeNext方法里就能调用基础阀的invoke了,当
basic.invoke(request, response, this);进入基础阀StandardEngineValve
5. 在StandardEngine的基础阀StandardEngineValve里,调用了子容器invoke方法(这里子容器就是StandardHost),还记得一开始connector.invoke(request, response)
(即StandardEngine的invoke方法)现在顺利的传递到子容器StandardHost的invoke方法,变成了StandardHost.invoke(request, response)。由此可以猜测StandardHost也会传递给它的
子容器,最后传递到最小的容器StandardWrapper的invoke方法,然后调用StandardWrapper的基础阀StandardWrapperValue的invoke方法,由于StandardWrapper是最小的容器了,
不能再传递到其他容器的invoke方法了,那它的invoke方法做了什么?主要做了两件事, 1:创建一个过滤器链并 2:分配一个servlet或者jsp
6. 这里先不关注jsp,只关注一下servlet,通过servlet = wrapper.allocate(); 进入StandardWrapper的allocate方法,allocate主要就是调用了loadServlet方法,在
loadServlet方法类用tomcat自己的类加载器实例化了一个servlet对象,并调用了该servlet的init和service方法。至此已经把请求传递到servlet的service(或者jsp的service)方法,
整个处理请求到这里就结束了,剩下的就是返回客户端了。
Tomcat源码分析(五)--容器处理连接之servlet的映射
本文所要解决的问题:一个http请求过来,容器是怎么知道选择哪个具体servlet?
1. 一个Context容器表示一个web应用,一个Wrapper容器表示一个servlet,所以上面的问题可以转换为怎么由Context容器选择servlet,答案是映射器。映射器是实现了Mapper接口的
类,作用就是根据请求连接(主要是协议和路径)来选择下一个容器,可以看做是一个哈希表,根据关键字段来选择具体的值,Mapper接口
2. 在Tomcat源码分析(四)--容器处理链接之责任链模式中已经知道,请求连接到达StandardContext容器的invoke方法,最终会到达StandardContextValue阀的invoke方法里面,在这个
invoke方法中有一句这样的代码。这句代码表示容器会调用map方法来映射请求到具体的wrapper上,意思就是说,根据连接请求request来选择wrapper。上面的map会调用父类ContainerBase
的map方法来找到具体的映射器,至于这个映射器和容器是怎么关联上的,具体请参考Tomcat源码分析(三)--连接器是如何与容器关联的?这篇文章,大致原理是一样的。StandardContext容器
有一个标准的映射器实现类StandardContextMapper,所以最终会调用到映射器StandardContextMapper的map方法,这个方法是选择servlet的关键
3. 分4中匹配模式(完全匹配,前缀匹配,扩展匹配,默认匹配)来选择wrapper,关键代码就是name = context.findServletMapping和wrapper = (Wrapper) context.findChild(name);这里
面context都是StandardContext。context.findServletMapping是根据匹配模式来找到servlet名字,context.findChild是根据servlet名字找到具体的wrapper。findServletMapping方法很
简单,就是在一个HashMap里面得到servlet名字
Tomcat源码分析(六)--日志记录器和国际化
1. 只要实现Logger就能有一个自己的日志记录器,其中setContainer是把日志记录器跟具体的容器关联,setVerbosity是设置日志的级别,log是具体的日志记录函数。FATAL,ERROR,WARNING,
INFORMATION,DEBUG代表日志记录的五个级别,看单词就能明白意思。这里主要讲解一下FileLogger类,这是Tomcat的其中一个日志记录器,它把日志记录在一个文件中,FileLogger的启动
方法和关闭仅仅是出发一个生命周期事件,并不做其他的事情
Tomcat源码分析(七)--单一启动/关闭机制(生命周期)
1. Tomcat有很多组件,要一个一个启动组件难免有点麻烦。由于Tomcat的包含关系是Catalina->Server->Service->容器/连接器/日志器等,于是可通过父组件负责启动/关闭它的子组件,
这样只要启动Catalina,其他的都自动启动了。这种单一启动和关闭的机制是通过实现Lifecycle接口来实现的
2. 当组件实现了Lifecycle接口,父组件启动的时候,即调用start方法时,只要在父组件的start方法中也调用子组件的start方法即可(只有实现统一的接口Lifecycle才能实现统一调用,如以下调用
方式:(Lifecycle)子组件.start())
3. 关键看((Lifecycle) server).start();这样便在启动Catalina的时候启动了Server,再看StandardServer的start方法
主要做了两件事,1:发送生命周期事件给监听者;2:启动子组件services(至于server怎么关联上services请看前面的几篇文章,以后都不再题怎么关联上的了)。
4. 这里先岔开一下,说一下监听器,lifecycle是一个工具类LifecycleSupport的实例,每一个组件都有这样一个工具类,这个工具类的作用就是帮助管理该组件上的监听器,包括添加监听器和群发
事件给监听器
5. 先看构造方法,传入一个lifecycle,因为每个组件都实现了lifecycle,所以这里传入的实际上是一个组件,即每个组件都有一个LifecycleSupport与之关联,当要在组件中添加一个监听器的时候,
实际上是添加进工具类LifecycleSupport的一个监听器数组listeners中,当要发送一个组件生命周期的事件时,工具类就会遍历监听器数组,然后再一个一个的发送事件。这里需要先实现我们
自己的监听器类并且添加进我们需要监听的组件当中。实现监听器类只要实现LifecycleListener接口就行
6. 我们需要做的就是实现LifecycleListener接口来拥有自己的监听器,在lifecycleEvent方法里写自己监听到事件后该做的事情,然后添加进要监听的组件就行,比如当我们要看StandardServer
是否启动了,在上面StandardServer的start方法有一句这样的代码:lifecycle.fireLifecycleEvent(START_EVENT, null);即发送StandardServer启动的事件给跟它关联的监听器。接下来回
到一开始,当server启动后,接着启动它的子组件service,即调用StandardService的start方法,这个方法跟StandardServer的start方法差不多,只是启动了连接器和容器,连接器的start
方法在前面的文章已经讲过了,主要是启动了n个处理器HttpProcessor组件。顶级容器是StandardEngine,它的start方法仅仅调用了父类ContainerBase的start方法
它启动了Tomcat其他所有的组件,包括加载器,映射器,日志记录器,管道等等,由这里也可以看出,他们都实现了Lifecycle接口。统一关闭跟统一启动的逻辑差不多,这里就不再说了。
Tomcat源码分析(八)--载入器(加载器)
1. Tomcat就是用的这种方法。jdk建议我们实现自己的类加载器的时候是重写findClass方法,不建议重写loadclass方法,因为ClassLoader的loadclass方法保证了类加载的父亲委托机制,
如果重写了这个方法,就意味着需要实现自己在重写的loadclass方法实现父亲委托机制
2. 当所有父类都加载不了,才会调用findClass方法,即调用到我们自己的类加载器的findClass方法
3. 在我们自己实现的类加载器中,defineClass方法才是真正的把类加载进jvm,defineClass是从ClassLoader继承而来,把一个表示类的字节数组加载进jvm转换为一个类。
4. 我们自己实现的类加载器跟系统的类加载器没有本质的区别,最大的区别就是加载的路径不同,系统类加载器会加载环境变量CLASSPATH中指明的路径和jvr文件,我们自己的类加载器
可以定义自己的需要加载的类文件路径.同样的一个class文件,用系统类加载器和自定义加载器加载进jvm后类的结构是没有区别的,只是他们访问的权限不一样,生成的对象因为加载器不同
也会不一样.当然我们自己的类加载器可以有更大的灵活性,比如把一个class文件(其实就是二进制文件)加密后(简单的加密就把0和1互换),系统类加载器就不能加载,需要由我们自己定义
解密类的加载器才能加载该class文件.
5. 现在来初步的看看Tomcat的类加载器,为什么Tomcat要有自己的类加载器.这么说吧,假如没有自己的类加载器,我们知道,在一个Tomcat中是可以部署很多应用的,如果所有的类都由
系统类加载器来加载,那么部署在Tomcat上的A应用就可以访问B应用的类,这样A应用与B应用之间就没有安全性可言了。还有一个原因是因为Tomcat需要实现类的自动重载,所以也
需要实现自己的类加载器。Tomcat的载入器是实现了Loader接口的WebappLoader类,也是Tomcat的一个组件,实现Lifecycle接口以便统一管理,启动时调用start方法,在start
方法主要做了以下的事情:
1:创建一个真正的类加载器以及设置它加载的路径,调用createClassLoader方法
2:启动一个线程来支持自动重载,调用threadStart方法
6. 在createClassLoader方法内,实例化了一个真正的类加载器WebappClassLoader,代码很简单。WebappClassLoader是Tomcat的类加载器,它继承了
URLClassLoader(这个类是ClassLoader的孙子类)类。重写了findClass和loadClass方法。Tomcat的findClass方法并没有加载相关的类,只是从已经加载的类中查找
这个类有没有被加载,具体的加载是在重写的loadClass方法中实现,从上面的对java的讨论可知,重写了loadClass方法就意味着失去了类加载器的父亲委托机制,需要自己
来实现父亲委托机制。
7. 上面的代码很长,但实现了Tomcat自己的类加载机制,具体的加载规则是:
1:因为所有已经载入的类都会缓存起来,所以先检查本地缓存
2:如本地缓存没有,则检查上一级缓存,即调用ClassLoader类的findLoadedClass()方法;
3:若两个缓存都没有,则使用系统的类进行加载,防止Web应用程序中的类覆盖J2EE的类
4:若打开标志位delegate(表示是否代理给父加载器加载),或者待载入的类是属于包触发器的包名,则调用父类载入器来加载,如果父类载入器是null,则使用系统类载入器
5:从当前仓库中载入相关类
6:若当前仓库中没有相关类,且标志位delegate为false,则调用父类载入器来加载,如果父类载入器是null,则使用系统类载入器(4跟6只能执行一个步骤的)
8. 先检查系统ClassLoader,因此WEB-INF/lib和WEB-INF/classes或{tomcat}/libs下的类定义不能覆盖JVM 底层能够查找到的定义(譬如不能通过定义java.lang.Integer替代底层的实现
Tomcat源码分析(九)--Session管理
1. JSESSIONID是一个唯一标识号,用来标识服务器端的Session,也用来标识客户端的Cookie,客户端和服务器端通过这个JSESSIONID来一一对应。这里需要说明的是Cookie已经包含
JSESSIONID了,可以理解为JSESSIONID是Cookie里的一个属性。
2. 让我假设一次客户端连接来说明我对个这三个概念的理解:
Http连接本身是无状态的,即前一次发起的连接跟后一次没有任何关系,是属于两次独立的连接请求,但是互联网访问基本上都是需要有状态的,即服务器需要知道两次连接请求是不是同
一个人访问的。如你在浏览淘宝的时候,把一个东西加入购物车,再点开另一个商品页面的时候希望在这个页面里面的购物车还有上次添加进购物车的商品。也就是说淘宝服务器会知道这
两次访问是同一个客户端访问的。
客户端第一次请求到服务器连接,这个连接是没有附带任何东西的,没有Cookie,没有JSESSIONID。服务器端接收到请求后,会检查这次请求有没有传过来JSESSIONID或者Cookie,
如果没有JSESSIONID和Cookie,则服务器端会创建一个Session,并生成一个与该Session相关联的JSESSIONID返回给客户端,客户端会保存这个JSESSIONID,并生成一个与该
JSESSIONID关联的Cookie,第二次请求的时候,会把该Cookie(包含JSESSIONID)一起发送给服务器端,这次服务器发现这个请求有了Cookie,便从中取出JSESSIONID,然后
根据这个JSESSIONID找到对应的Session,这样便把Http的无状态连接变成了有状态的连接。但是有时候浏览器(即客户端)会禁用Cookie,我们知道Cookie是通过Http的请求头部
的一个cookie字段传过去的,如果禁用,那么便得不到这个值,JSESSIONID便不能通过Cookie传入服务器端,当然我们还有其他的解决办法,url重写和隐藏表单,url重写就是把
JSESSIONID附带在url后面传过去。隐藏表单是在表单提交的时候传入一个隐藏字段JSESSIONID。这两种方式都能把JSESSIONID传过去。
3. 代码主要就是从http请求头部的字段cookie得到JSESSIONID并设置到reqeust的sessionid,没有就不设置。这样客户端的JSESSIONID(cookie)就传到tomcat,tomcat
把JSESSIONID的值赋给request了。这个request在Tomcat的唯一性就标识了。
4. Session只对应用有用,两个应用的Session一般不能共用,在Tomcat一个Context代表一个应用,所以一个应用应该有一套自己的Session,Tomcat使用Manager来管理各个应用
的Session,Manager也是一个组件,跟Context是一一对应的关系,怎么关联的请参考Tomcat源码分析(一)--服务启动,方法类似。Manager的标准实现是StandardManager,
由它统一管理Context的Session对象(标准实现是StandardSession),能够猜想,StandardManager一定能够创建Session对象和根据JSESSIONID从跟它关联的应用中查找
Session对象。事实上StandardManager确实有这样的方法,但是StandardManager本身没有这两个方法
5. Session是在什么时候生成的?仔细想想,我们编写servlet的时候,如果需要用到Session,会使用request.getSession(),这个方法最后会调用到HttpRequestBase的
getSession()方法,所以这里有个重要的点:Session并不是在客户端第一次访问就会在服务器端生成,而是在服务器端(一般是servlet里)使用request调用getSession方法才
生成的。但是默认情况下,jsp页面会调用request.getSession(),即jsp页面的这个属性<%@ page session="true" %>默认是true的,编译成servlet后会调用
request.getSession()。所以只要访问jsp页面,一般是会在服务器端创建session的。但是在servlet里就需要显示的调用getSession(),当然是在要用session的情况。
Tomcat源码分析(十)--部署器
1. 在Tomcat的世界里,一个Host容器代表一个虚机器资源,Context容器代表一个应用,所谓的部署器就是能够把Context容器添加进Host容器中去的一个组件。显然,一个Host
容器应该拥有一个部署器组件。
2. 在Catalina的createStartDigester()方法中,向StandardHost容器中添加了一个HostConfig的实例。HostConfig类实现了LifecycleListener接口,也就是说它是个监听器类,
能监听到组件的生命周期事件
3. 如果监听到StandardHost容器启动开始了,则调用start方法来
4. ((Deployer) host).install(contextPath, url);会调用到StandardHost的install方法,再由StandardHost转交给StandardHostDeployer的install方法,
StandardHostDeployer是一个辅助类,帮助StandardHost来实现发布应用,它实现了Deployer接口,看它的install(URL config, URL war)方法(它有两个install方法,分别
用来发布上面不同方式的应用
Tomcat 源码分析(转)的更多相关文章
- tomcat源码分析(三)一次http请求的旅行-从Socket说起
p { margin-bottom: 0.25cm; line-height: 120% } tomcat源码分析(三)一次http请求的旅行 在http请求旅行之前,我们先来准备下我们所需要的工具. ...
- [Tomcat 源码分析系列] (二) : Tomcat 启动脚本-catalina.bat
概述 Tomcat 的三个最重要的启动脚本: startup.bat catalina.bat setclasspath.bat 上一篇咱们分析了 startup.bat 脚本 这一篇咱们来分析 ca ...
- Tomcat源码分析
前言: 本文是我阅读了TOMCAT源码后的一些心得. 主要是讲解TOMCAT的系统框架, 以及启动流程.若有错漏之处,敬请批评指教! 建议: 毕竟TOMCAT的框架还是比较复杂的, 单是从文字上理解, ...
- Tomcat源码分析之—具体启动流程分析
从Tomcat启动调用栈可知,Bootstrap类的main方法为整个Tomcat的入口,在init初始化Bootstrap类的时候为设置Catalina的工作路径也就是Catalina_HOME信息 ...
- Tomcat源码分析--转
一.架构 下面谈谈我对Tomcat架构的理解 总体架构: 1.面向组件架构 2.基于JMX 3.事件侦听 1)面向组件架构 tomcat代码看似很庞大,但从结构上看却很清晰和简单,它主要由一堆组件组成 ...
- tomcat 源码分析
Tomcat源码分析——Session管理分析(下) Tomcat源码分析——Session管理分析(上) Tomcat源码分析——请求原理分析(下) Tomcat源码分析——请 ...
- Tomcat源码分析——Session管理分析(下)
前言 在<TOMCAT源码分析——SESSION管理分析(上)>一文中我介绍了Session.Session管理器,还以StandardManager为例介绍了Session管理器的初始化 ...
- Tomcat源码分析——Session管理分析(上)
前言 对于广大java开发者而已,对于J2EE规范中的Session应该并不陌生,我们可以使用Session管理用户的会话信息,最常见的就是拿Session用来存放用户登录.身份.权限及状态等信息.对 ...
- Tomcat源码分析——请求原理分析(下)
前言 本文继续讲解TOMCAT的请求原理分析,建议朋友们阅读本文时首先阅读过<TOMCAT源码分析——请求原理分析(上)>和<TOMCAT源码分析——请求原理分析(中)>.在& ...
- Tomcat源码分析——请求原理分析(中)
前言 在<TOMCAT源码分析——请求原理分析(上)>一文中已经介绍了关于Tomcat7.0处理请求前作的初始化和准备工作,请读者在阅读本文前确保掌握<TOMCAT源码分析——请求原 ...
随机推荐
- Windwos下连远程linux Hbase小问题
前几天,兴起想仔细玩玩hbase,细细去研究一下,写了个小demo,从win7去连接另一台T510的ubuntu上的hbase.很简单的crud的操作程序,没有看出来什么问题,但是跑起来,硬是好像bl ...
- Apple设备中point,磅(pt),pixel的关系与转换,以及iPhone模拟器与真机的长度关系
查阅了好多资料都没有发现有相关的详细介绍,包括苹果官方文档,也是草草带过.后来是在一个介绍Macbook打印字体的博客中看到的,受到启发. 首先说明苹果设备绘图的长度单位可以认为是point,不是磅( ...
- 第二百一十七节,jQuery EasyUI,NumberSpinner(数字微调)组件
jQuery EasyUI,NumberSpinner(数字微调)组件 学习要点: 1.加载方式 2.属性列表 3.事件列表 4.方法列表 本节课重点了解 EasyUI 中 NumberSpinner ...
- 重载(Overload)
重载(Overload) 重载(overloading) 是在一个类里面,方法名字相同,而参数不同.返回类型可以相同也可以不同. 每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表. 最 ...
- VC中怎么输入特殊符号(如平方、立方等下标符号)
同在列表控件里显示汉字一样,直接把输入法里特殊字符放进一个数组里,然后再赋值:CString F[]={"m²","∑","±"," ...
- [转]廖雪峰Git教程总结
- SpringMVC学习(十一)——SpringMVC实现Resultful服务
http://blog.csdn.net/yerenyuan_pku/article/details/72514034 Restful就是一个资源定位及资源操作的风格,不是标准也不是协议,只是一种风格 ...
- Delphi TreeView – 自动展开树形结构
Delphi TreeView – 自动展开树形结构 当处理完TreeView控件树形结构的数据后,需要默认自动全部展开,可以用到TreeView的Expanded属性. 1 2 3 4 5 6 7 ...
- matplotlib图像中文乱码(python3.6)
方法一:(在代码中添加如下代码) import matplotlib #指定默认字体 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] matpl ...
- VC中获取窗口句柄的各种方法
AfxGetMainWndAfxGetMainWnd获取自身窗口句柄HWND hWnd = AfxGetMainWnd()->m_hWnd; GetTopWindow函数功能:该函数检查与特定父 ...