MemSQL分布式架构介绍(二)
接上次的MemSQL分布式架构介绍(一),原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/
首先上张图,是我根据自己的理解画的,如有错误还请大家指出
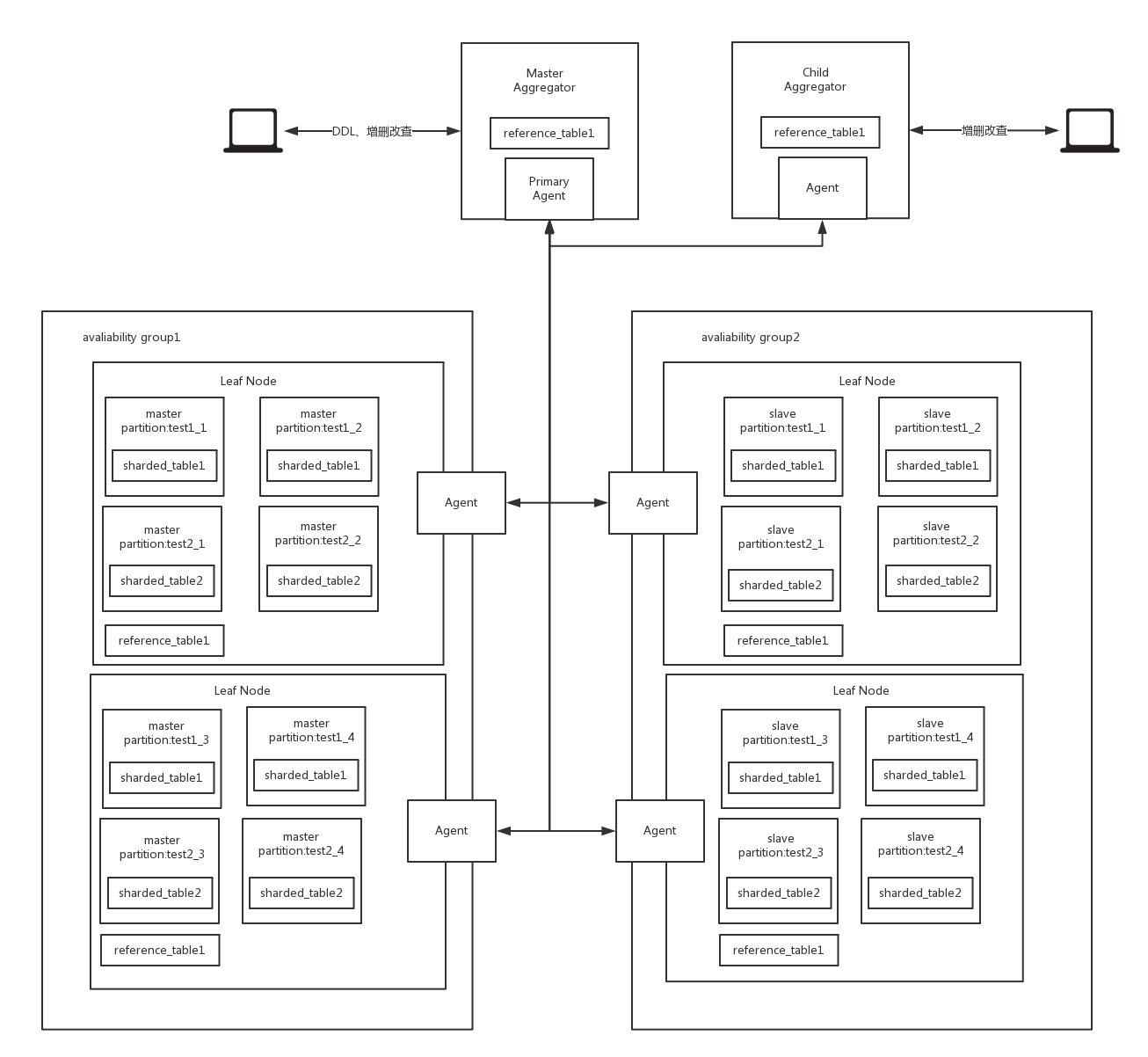
几个概念
1、MemSQL有两种类型的表:
- reference table 参照表 数据分布在主 aggregator和每个leaf节点。每个节点的数据都是完整的(没有分区)。 参照表同过复制从 主 aggregator向每个 leaf节点同步数据。另外参照表的写只能在 主 aggregator进行。
- sharded table 分布表 数据通过hash分片存储在每 个leaf节点, 每 个leaf节点只有部分数据。
Querying MemSQL
注#官方文档里面说的这个query我理解为是增删改查操作,如理解有误,也请大家指出。
MemSQL在第一次执行一条query时将会编译这条语句并cache到内存中。
用户的query总是被指向一个汇聚器。DDL的操作或者向reference table写数据时必须通过主汇聚器,而其他的DML语句则可以通过任意的汇聚器。
只对reference table进行的query只会在汇聚器执行。汇聚器将不会发送这些query到叶子节点因为每一个汇聚器节点或者叶子节点都存有reference table的一个拷贝。
对sharded table进行的query包含更多:
- 在最简单的情况下,一个query需要的数据只在一个分区中,因此这个query能直接被forward到正确叶子节点,如INSERT INTO db.table VALUES (15)。除非重写数据库名字让其映射到指定的分区,INSERT INTO db_3.table VALUES (15) 。
- 如果一个query需要的数据在多个分区中,那么汇聚器将会从多个叶子节点中获取数据。比如说,SELECT COUNT(*) from t 将会发送一个COUNT(*)给每个分区,然后汇总返回,最终返回一行给用户。
一些query会有很多的query转换和汇聚逻辑,但他们都遵循了相同的通用流程。可以在一个query语句中使用EXPLAIN关键字来显示汇聚器和叶子节点之间的执行计划,包括将会发送到叶子节点的重写query。
数据分布
MemSQL将会在分布表上通过每一行的主键哈希来分布数据(哈希分区表)。由于每个主键是唯一的同时hash函数一般又是统一的,所以集群能够相对均匀地分布数据和最小化数据倾斜(data skew)
在创建数据库的时候,MemSQL会拆分数据库到几个分区中。每个分区都有自己的哈希范围。你能够显式地指定分区数量通过PARTITIONS=X选项。默认的话分区的总数是叶子节点数的8倍。
每一个叶子节点上的分区是通过database实现的。当一个分布表被创建的时候,它会根据database的分区数量被拆分。这个表被保存于分区的数据切片中。二级索引是通过每个分区和每行主键作为唯一索引的前缀来被管理的。
如果你运行的一个query需要查找二级索引,那么汇聚器会fan out这个query到集群中的所有分区,每个分区都会去找这个二级索引。
精确匹配shard key的的Query将会被路由到一个单一的叶子节点(我的理解是insert语句或者可以确定hash值的增删改查语句,因为确定了hash值MemSQL就知道这条记录放在哪里了)。否则的话,汇聚器将会发送这个query到集群中并收集结果。你可以使用EXPLAIN关键字来测试创建的query,并查看叶子节点和query分布策略。
Availability Groups
一个高可用组是叶子节点的集合,用于存储冗余数据以确保高可用。每一个高可用组包含了每一个分区的拷贝(一些为master而一些为slave)。目前,MemSQL只支持两个高可用组。你可以设置高可用组的数量通过redundancy_level变量在主汇聚器上。后面我们讨论的是redundancy-2的场景(有就是有两个高可用组的情况)。
每一个在高可用组的叶子节点都有对应的pair节点在其他的高可用组中。当有一个分区失效时,MemSQL将会自动将这个分区的slave分区提升为master分区。
MemSQL分布式架构介绍(二)的更多相关文章
- MemSQL分布式架构介绍(一)
最近在了解MemSQL架构,看了些官方文档,在这里做个记录,原文在这里:http://docs.memsql.com/latest/concepts/distributed_architecture/ ...
- MySQL 部署分布式架构 MyCAT (二)
安装 MyCAT 安装 java 环境(db1) yum install -y java 下载 Mycat-server-1.6.5-release-20180122220033-linux.tar. ...
- MySQL之九---分布式架构(Mycat/DBLE)
MyCAT基础架构图 双主双从结构 MyCAT基础架构准备 准备环境 环境准备: 两台虚拟机 db01 db02 每台创建四个mysql实例:3307 3308 3309 3310 删除历史环境 p ...
- shiro权限控制(二):分布式架构中shiro的实现
前言:前段时间在搭建公司游戏框架安全验证的时候,就想到之前web最火的shiro框架,虽然后面实践发现在netty中不太适用,最后自己模仿shiro写了一个缩减版的,但是中间花费两天时间弄出来的shi ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- (转)OpenStack —— 原理架构介绍(一、二)
原文:http://blog.51cto.com/wzlinux/1961337 http://blog.51cto.com/wzlinux/category18.html-------------O ...
- [原创].NET 分布式架构开发实战之二 草稿设计
原文:[原创].NET 分布式架构开发实战之二 草稿设计 .NET 分布式架构开发实战之二 草稿设计 前言:本篇之所以称为草稿设计,是因为设计的都是在纸上完成的.反映了一个思考的过程. 本篇的议题如下 ...
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- 大型网站技术架构介绍--squid
一.大型网站技术架构介绍 1.pv高 ip高 并发量 2.大型网站架构重点 1. 高性能:响应时间,TPS,系统性能计数器.缓存,消息队列等. 高可用性High Availabilit ...
随机推荐
- C语言编译过程详解
前言 C语言程序从源代码到二进制行程序都经历了那些过程?本文以Linux下C语言的编译过程为例,讲解C语言程序的编译过程. 编写hello world C程序: // hello.c #include ...
- 微软参考源代码 referencesource.microsoft.com
微软参考源代码 http://referencesource.microsoft.com/ referencesource 下载地址 https://github.com/Microsoft/refe ...
- Java知识点总结(不定时更新)
1.基于分代的垃圾收集算法 设计思路:把对象按照寿命长短来分组,分为年轻代和年老代,新创建的对象被分在年轻代,如果对象经过几次回收后仍然存活,那么再把这个对象划分到年老代.年老代的收集频率不像年轻代那 ...
- Hadoop Pipes Exception: Illegal text protocol command
Hadoop Pipes Exception: Illegal text protocol command 对于Hadoop pipes 出现这样的错误,基本上编译代码依赖的.so和.a 版本不匹配 ...
- 清除浮动after
.clearf{display: inline-block;} .clearf:after { content: "."; display: block; height:; cle ...
- RabbitMQ与AMQP协议详解
1. 消息队列的历史 了解一件事情的来龙去脉,将不会对它感到神秘.让我们来看看消息队列(Message Queue)这项技术的发展历史. Message Queue的需求由来已久,80年代最早在金融交 ...
- spring mvc绑定复杂对象报错“Could not instantiate property type [com.ld.net.spider.pojo.WorkNode] to auto-grow nested property path: java.lang.InstantiationException: com.ld.net.spider.pojo.WorkNode”
解决方法之一: 1.确保所有的Pojo都包含了默认的构造器:
- C++ 面向对象的三个特点--多态性(二)
运算符重载 运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型. 类外部的运算符重载 首先,我们通过一个例子来说明为什么要有运算符重载. // Complex.h cl ...
- android MVP模式介绍与实战
android MVP模式介绍与实战 描述 MVP模式是什么?MVP 是从经典的模式MVC演变而来,它们的基本思想有相通的地方:Controller/Presenter负责逻辑的处理,Model提供数 ...
- ogrinfo使用
简介 orginfo是OGR模块中提供的一个重要工具,用于读取地图文件中记录,可以指定筛选条件(按字段.sql.矩形范围) 使用方式 命令行参数 Usage: ogrinfo [--help-gene ...