elasticsearch + hive环境搭建
一、环境介绍:
elasticsearch:2.3.1
hive:0.12
二、环境搭建
2.1 首先获取elasticsearc-hadoop的jar包
链接地址:http://jcenter.bintray.com/org/elasticsearch/elasticsearch-hadoop/2.3.1/elasticsearch-hadoop-2.3.1.jar,下载即可。需要说明的是你的elasticsearch什么版本,那么elasticsearch-hadoop的jar包就什么版本,否则后果难料
2.2 hive集成elasticsearch
将elasticsearch-hadoop-2.3.1.jar拷贝到hive的默认lib目录即可。我的目录是:$HIVE_HOME/auxlib目录
启动hive,查看效果:
/home/q/java/default/bin/java -Xmx256m -Djava.net.preferIPv4Stack=true *** -hiveconf hive.aux.jars.path=file:///home/q/hive/hive-0.12.0-bin/auxlib/elasticsearch-hadoop-2.0.1.jar
只要包含了上面的红色部分说明集成成功
三、插入数据
3.1 建立数据表
3.1.1 建立view表
CREATE EXTERNAL TABLE user (id INT, name STRING)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'radiott/artiststt','es.index.auto.create' = 'true','es.nodes' = 'elastisticsearch.*.qunar.com','es.port' = '');
有几个参数,es.nodes是配置的es的url地址,默认是localhost。es.port是端口号码,默认是9200
3.1.2 建立数据表
CREATE TABLE user_source (id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3.2 加载数据
3.2.1 加载基础数据
数据示例,我放在/tmp/user_source.log
1,medcl
2,lcdem
3,tom
4,jack
加载到user_source表,命令如下:LOAD DATA LOCAL INPATH '/tmp/user_source.log' OVERWRITE INTO TABLE user_source;
3.2.2 加载到es
INSERT OVERWRITE TABLE user SELECT s.id, s.name FROM user_source s;
查看效果:
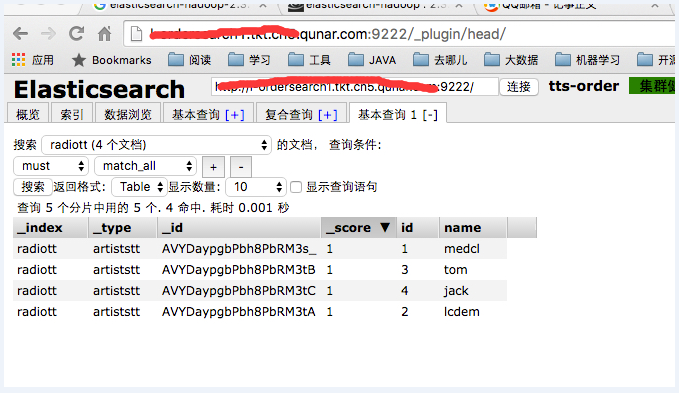
四、参考文档:
http://blog.csdn.net/sunflower_cao/article/details/39896189
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html#_essential_settings
elasticsearch + hive环境搭建的更多相关文章
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
- Hive环境搭建
hive 环境搭建需要hadoop的环境.hadoop环境的搭建不在这里赘述.参考:http://www.cnblogs.com/parkin/p/6952370.html 1.准备阶段 hive 官 ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
- Hadoop生态圈-Hive快速入门篇之Hive环境搭建
Hadoop生态圈-Hive快速入门篇之Hive环境搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据仓库(理论性知识大多摘自百度百科) 1>.什么是数据仓库 数据 ...
- Hive环境搭建和SparkSql整合
一.搭建准备环境 在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境 这里使用Hive和Spark进行整合的目的主要是: 1.使用Hive对SparkSql中产 ...
- Hive——环境搭建
Hive--环境搭建 相关hadoop和mysql环境已经搭建好.我博客中也有相关搭建的博客. 一.下载Hive并解压到指定目录(本次使用版本hive-1.1.0-cdh5.7.0,下载地址:http ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 转载 Elasticsearch开发环境搭建(Eclipse\MyEclipse + Maven)
概要: 1.使用Eclipse搭建Elasticsearch详情参考下面链接 2.Java Elasticsearch 配置 3.ElasticSearch Java Api(一) -添加数据创建索引 ...
随机推荐
- C#设计模式(6)——原型模式(Prototype Pattern)
一.引言 在软件系统中,当创建一个类的实例的过程很昂贵或很复杂,并且我们需要创建多个这样类的实例时,如果我们用new操作符去创建这样的类实例,这未免会增加创建类的复杂度和耗费更多的内存空间,因为这样在 ...
- “System.Web.UI.WebControls.Literal”不允许使用子控件
今天在写下面的代码时遭遇错误——“System.Web.UI.WebControls.Literal”不允许使用子控件('System.Web.UI.WebControls.Literal' does ...
- 冲刺阶段 day2
day2 项目进展 今天本组五位同学聚在一起将项目启动,首先我们对项目进行了规划,分工,明确指出每个人负责哪些项目.由负责第一部分的组员开始编程,在已经搭建好的窗体内,对系部设置进行了编写,本校共六个 ...
- ubuntu 12.04 支持中文----完胜版
原文地址 http://pobeta.com/ubuntu-sublime.html, /* sublime-imfix.c Use LD_PRELOAD to interpose some func ...
- 重装Eclipse、离线安装ADT、Android SDK
由于最新的ADT.Android SDK需要最新版本的Eclipse才能使用,我无奈的只好升级Eclipse.看看自己的Eclipse已经两年没有升级了,也是时候升级了.升级前,有很多的顾虑.因为像这 ...
- Javascript之document对象用法(很重要)
一.找到元素 document.getElementById("id"):根据id找层,最多找一个 var a=document.getElementById("id&q ...
- atitit.常用编程语言的性能比较 c c++ java
atitit.常用编程语言的性能比较 c c++ java 选择一个什么样的程序问题进行这样的测试呢?这是一个很关键的问题,也最容易影响测试的公平性.另外的,对于每种语言,各自的优势都是不同的 #-- ...
- Django基础——Model篇(二)
一 Model连表关系 一对多:models.ForeignKey(其他表) 多对多:models.ManyToManyField(其他表) 一对一:models.OneToOneFiel ...
- python常用sql语句
#coding=utf-8 import MySQLdb conn = MySQLdb.Connect(host = '127.0.0.1',port=3306,user='root',passwd= ...
- How to get blob data using javascript XmlHttpRequest by sync
Tested: Firefox 33+ OK Chrome 38+ OK IE 6 -- IE 10 Failed Thanks to 阮一峰's blog: http://www.ruanyifen ...