[Advanced Python] 14 - "Generator": calculating prime
高性能编程
几个核心问题
• 生成器是怎样节约内存的?
• 使用生成器的最佳时机是什么?
• 我如何使用 itertools 来创建复杂的生成器工作流?
• 延迟估值何时有益,何时无益?
From: https://www.dataquest.io/blog/python-generators-tutorial/
• The basic terminology needed to understand generators
• What a generator is
• How to create your own generators
• How to use a generator and generator methods
• When to use a generator
表示数列
有限数列情况
案例一:xrange,节省内存
自定义xrange使用yield,采用的方法是依次计算。
目前的range具备了这个特性。
In [16]: def xrange(start, stop, step=1):
...: while start < stop:
...: yield start
...: start += step
...: In [17]: for i in xrange(1,100):
...: print(i)
无限数列情况
案例二:Fibonacci Sequence
def fibonacci(n):
a, b = 0, 1
while n > 0:
yield b
a, b = b, a + b
n -= 1 def Fibonacci_Yield(n):
# return [f for i, f in enumerate(Fibonacci_Yield_tool(n))]
return list(fibonacci(n))
案例三:fibonacci中有几个奇数
for 循环中的自定义序列。
def fibonacci_transform():
count = 0
for f in fibonacci():
if f > 5000:
break
if f % 2 == 1:
count += 1 return count
生成器的延时估值
—— 主要关注如何处理大数据,并具备什么优势。
Ref: Python Generators
Big Data. This is a somewhat nebulous term, and so we won’t delve into the various Big Data definitions here. Suffice to say that any Big Data file is too big to assign to a variable.
尤其是List不方便一下子装载到内存的时候。
各种形式的生成器
- Load beer data in big data.
beer_data = "recipeData.csv"
lines = (line for line in open(beer_data, encoding="ISO-8859-1"))
建议把这里的open事先改为:with ... as。
- Laziness and generators
Once we ask for the next value of a generator, the old value is discarded.
Once we go through the entire generator, it is also discarded from memory as well.
进化历程
- Build pipeline
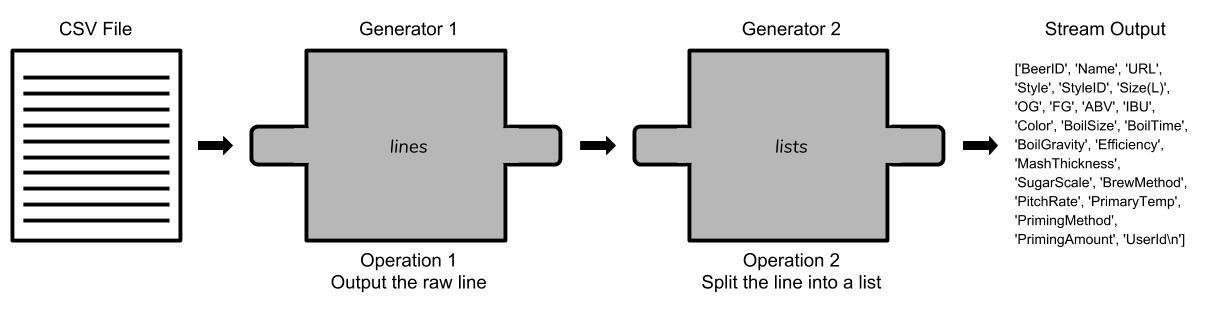
beer_data = "recipeData.csv"
lines = (line for line in open(beer_data, encoding="ISO-8859-1")) # (1) 获得了“一行”
lists = (l.split(",") for l in lines) # (2) 对这“一行”进行分解
- Operation in pipeline
(1) 先获得第一行的title,也就是column将作为key;然后从第二行开始的值作为value。
['BeerID', 'Name', 'URL', ..., 'PrimaryTemp', 'PrimingMethod', 'PrimingAmount', 'UserId\n']
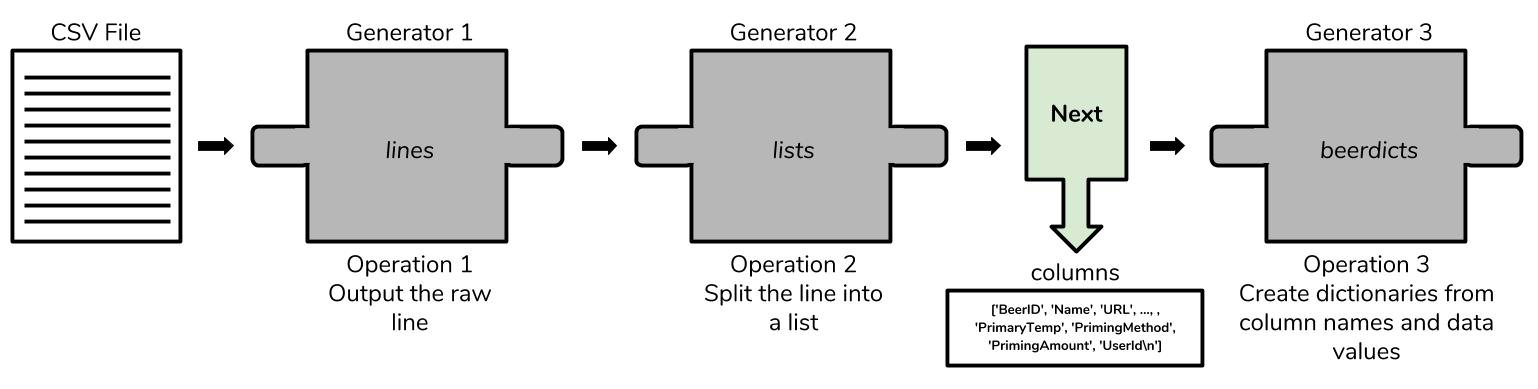
zip()将两个list的元素配对,然后转换为dict。
# 样例模板
beer_data = "recipeData.csv"
lines = (line for line in open(beer_data, encoding="ISO-8859-1"))
lists = (l.split(",") for l in lines)
#-----------------------------------------------------------------------------
# Take the column names out of the generator and store them, leaving only data
columns = next(lists) # 取第一行单独出来用 # Take these columns and use them to create an informative dictionar
beerdicts = ( dict( zip(columns, line) ) for line in lists )
(2) 一行数据结合一次“标题栏” 构成了一条新的数据。然后,开始统计。
bd["Style"] 作为每一条数据的类别的key,拿来做统计用。

# 遍历每一条,并统计beer的类型
beer_counts = {}
for bd in beerdicts:
if bd["Style"] not in beer_counts:
beer_counts[bd["Style"]] = 1
else:
beer_counts[bd["Style"]] += 1 # 得到beer类型的统计结果:beer_counts
most_popular = 0
most_popular_type = None
for beer, count in beer_counts.items():
if count > most_popular:
most_popular = count
most_popular_type = beer most_popular_type
>>> "American IPA"
# 再通过这个结果,处理相关数据
abv = (float(bd["ABV"]) for bd in beerdicts if bd["Style"] == "American IPA")
质数生成 - prime number
next 结合 yield
定义了一个“内存环保”的计算素数的函数primes()。
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
# 保存一个breakpoint,下次在此基础上计算 def _not_divisible(n):
return lambda x: x % n > 0 # 对每一个元素x 都去做一次处理,参数是n def primes():
yield 2
it = _odd_iter() # (1).初始"惰性序列"
while True:
n = next(it) # (2).n是在历史记录的基础上计算而得
yield n
it = filter(_not_divisible(n), it) # (3).构造新序列,it代表的序列是无限的; p = primes()
next(p)
next(p)
这里妙在,在逻辑上保证了it代表的序列是个无限序列,但实际上在物理意义上又不可能。
例如,当n = 9时?首选,n不可能等于9,因为后面会“不小心”yield出去。
闭包带来的问题
Stack Overflow: How to explain this “lambda in filter changes the result when calculate primes"
此问题涉及到 Lambda如何使用,以及闭包的风险:[Python] 07 - Statements --> Functions
# odd_iter = filter(not_divisible(odd), odd_iter) # <--(1)
odd_iter = filter((lambda x: x%odd>0) , odd_iter) # <--(2)
当yield的这种lazy机制出现时,谨慎使用lambda;注意保护好”内部变量“。
质数生成的"高效方案"
# Sieve of Eratosthenes
# Code by David Eppstein, UC Irvine, 28 Feb 2002
# http://code.activestate.com/recipes/117119/ def gen_primes():
""" Generate an infinite sequence of prime numbers.
"""
# Maps composites to primes witnessing their compositeness.
# This is memory efficient, as the sieve is not "run forward"
# indefinitely, but only as long as required by the current
# number being tested.
#
D = {} # The running integer that's checked for primeness
q = 2 while True:
if q not in D:
# q is a new prime.
# Yield it and mark its first multiple that isn't
# already marked in previous iterations
#
yield q
D[q * q] = [q]
else:
# q is composite. D[q] is the list of primes that
# divide it. Since we've reached q, we no longer
# need it in the map, but we'll mark the next
# multiples of its witnesses to prepare for larger
# numbers
#
for p in D[q]:
D.setdefault(p + q, []).append(p)
print("else: {}, {}".format(q, D))
del D[q]
q += 1
...
loop: 2, {}
2
loop: 3, {4: [2]}
3
loop: 4, {4: [2], 9: [3]}
else: 4, {4: [2], 9: [3], 6: [2]}
loop: 5, {9: [3], 6: [2]}
5
loop: 6, {9: [3], 6: [2], 25: [5]}
else: 6, {9: [3], 6: [2], 25: [5], 8: [2]}
loop: 7, {9: [3], 25: [5], 8: [2]}
7
loop: 8, {9: [3], 25: [5], 8: [2], 49: [7]}
else: 8, {9: [3], 25: [5], 8: [2], 49: [7], 10: [2]}
loop: 9, {9: [3], 25: [5], 49: [7], 10: [2]}
else: 9, {9: [3], 25: [5], 49: [7], 10: [2], 12: [3]}
loop: 10, {25: [5], 49: [7], 10: [2], 12: [3]}
else: 10, {25: [5], 49: [7], 10: [2], 12: [3, 2]}
loop: 11, {25: [5], 49: [7], 12: [3, 2]}
11
loop: 12, {25: [5], 49: [7], 12: [3, 2], 121: [11]}
else: 12, {25: [5], 49: [7], 12: [3, 2], 121: [11], 15: [3]}
else: 12, {25: [5], 49: [7], 12: [3, 2], 121: [11], 15: [3], 14: [2]}
loop: 13, {25: [5], 49: [7], 121: [11], 15: [3], 14: [2]}
13
loop: 14, {25: [5], 49: [7], 121: [11], 15: [3], 14: [2], 169: [13]}
else: 14, {25: [5], 49: [7], 121: [11], 15: [3], 14: [2], 169: [13], 16: [2]}
loop: 15, {25: [5], 49: [7], 121: [11], 15: [3], 169: [13], 16: [2]}
else: 15, {25: [5], 49: [7], 121: [11], 15: [3], 169: [13], 16: [2], 18: [3]}
loop: 16, {25: [5], 49: [7], 121: [11], 169: [13], 16: [2], 18: [3]}
else: 16, {25: [5], 49: [7], 121: [11], 169: [13], 16: [2], 18: [3, 2]}
loop: 17, {25: [5], 49: [7], 121: [11], 169: [13], 18: [3, 2]}
17
loop: 18, {25: [5], 49: [7], 121: [11], 169: [13], 18: [3, 2], 289: [17]}
else: 18, {25: [5], 49: [7], 121: [11], 169: [13], 18: [3, 2], 289: [17], 21: [3]}
else: 18, {25: [5], 49: [7], 121: [11], 169: [13], 18: [3, 2], 289: [17], 21: [3], 20: [2]}
loop: 19, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 21: [3], 20: [2]}
19
loop: 20, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 21: [3], 20: [2], 361: [19]}
else: 20, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 21: [3], 20: [2], 361: [19], 22: [2]}
loop: 21, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 21: [3], 361: [19], 22: [2]}
else: 21, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 21: [3], 361: [19], 22: [2], 24: [3]}
loop: 22, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 22: [2], 24: [3]}
else: 22, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 22: [2], 24: [3, 2]}
loop: 23, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 24: [3, 2]}
23
loop: 24, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 24: [3, 2], 529: [23]}
else: 24, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 24: [3, 2], 529: [23], 27: [3]}
else: 24, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 24: [3, 2], 529: [23], 27: [3], 26: [2]}
loop: 25, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 26: [2]}
else: 25, {25: [5], 49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 26: [2], 30: [5]}
loop: 26, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 26: [2], 30: [5]}
else: 26, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 26: [2], 30: [5], 28: [2]}
loop: 27, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 30: [5], 28: [2]}
else: 27, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 27: [3], 30: [5, 3], 28: [2]}
loop: 28, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 30: [5, 3], 28: [2]}
else: 28, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 30: [5, 3, 2], 28: [2]}
loop: 29, {49: [7], 121: [11], 169: [13], 289: [17], 361: [19], 529: [23], 30: [5, 3, 2]}
29
End.
[Advanced Python] 14 - "Generator": calculating prime的更多相关文章
- 【Python注意事项】如何理解python中间generator functions和yield表情
本篇记录自己的笔记Python的generator functions和yield理解表达式. 1. Generator Functions Python支持的generator functions语 ...
- Debug 路漫漫-11:Python: TypeError: 'generator' object is not subscriptable
调试程序,出现以下错误: Python: TypeError: 'generator' object is not subscriptable “在Python中,这种一边循环一边计算的机制,称为生成 ...
- [Advanced Python] 15 - "Metaclass": ORM
From: 使用元类 动态创建类 与静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的. 一 .type()动态创建 我们说class的定义是运行时动态创建的: 而创建cl ...
- 【python之路29】python生成器generator与迭代器
一.python生成器 python生成器原理: 只要函数中存在yield,则函数就变为生成器函数 #!usr/bin/env python # -*- coding:utf-8 -*- def xr ...
- python yield generator 详解
本文将由浅入深详细介绍yield以及generator,包括以下内容:什么generator,生成generator的方法,generator的特点,generator基础及高级应用场景,genera ...
- python enhanced generator - coroutine
本文主要介绍python中Enhanced generator即coroutine相关内容,包括基本语法.使用场景.注意事项,以及与其他语言协程实现的异同. enhanced generator 在上 ...
- python 生成器generator
关于生成器,主要有以下几个 关键点的内容 一.什么是generator ,为什么要有generator? 二.两种创建生成器方式 三.yield关键字 四.generator 两个调用方法 next( ...
- python生成器(generator)、迭代器(iterator)、可迭代对象(iterable)区别
三者联系 迭代器(iterator)是一个更抽象的概念,任何对象,如果它的类有next方法(next python3)和__iter__方法返回自己本身,即为迭代器 通常生成器是通过调用一个或多个yi ...
- 流畅的python 14章可迭代的对象、迭代器 和生成器
可迭代的对象.迭代器和生成器 迭代是数据处理的基石.扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项.这就是迭代器模式(Iterator pattern). 迭 ...
随机推荐
- Oracle笔记_多表查询
1 执行sql文件 @文件地址名 --执行某个sql文件: 2 多表查询 想要的数据不在同一张表,就需要多个表进行联查. 多表查询也叫做表连接查询,其中的where条件就是连接条件. 可以使用join ...
- Codeforces 814D
题意略. 思路: 由于不重合这个性质,我们可以将每一个堆叠的圆圈单独拿出来考虑,而不用去考虑其他并列在同一层的存在, 在贪心解法下,发现,被嵌套了偶数层的圆圈永远是要被减去的,而奇数层的圆圈是要加上的 ...
- Linux 下安装 mysql8
1.下载mysql wget https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.13-linux-glibc2.12-x86_64.tar 2. ...
- python循环语句的一些题型
1. 使用while循环输出1 2 3 4 5 6 8 9 10 i =1 while i <= 10: print(i,end=' ') i = i +1 if i == 7: i = i + ...
- java基础-多线程一
什么是线程 说到线程就不得不说下进程了, 大家都知道,许许多多的线程组合在一起就成了一个进程,进程是由操作系统进行资源操作的一个最小的单位,线程则是比进程更小的实际执行操作的单位:每个线程都有自己的堆 ...
- 第7章 使用springMVC构建Web应用程序 7.1 springMVC配置
最近在看spring in action第3版,这里搭建一个简单的spring mvc,也算书没白看,当然老鸟可以不屑了,这里只是给自己做个笔记,配置也尽量删烦就简, Spring MVC的核心是Di ...
- SpringCloud(二)- 服务注册与发现Eureka
离上一篇微服务的基本概念已经过去了几个月,在写那篇博客之前,自己还并未真正的使用微服务架构,很多理解还存在概念上.后面换了公司,新公司既用了SpringCloud也用了Dubbo+Zookeeper, ...
- 系统模块 OS
os.system("系统命令") 调用系统命令 os.system("task kill /f /im 系统的进程") 关闭系统进程 os.listdir( ...
- python中的全局变量
1. 在函数中定义的局部变量如果和全局变量同名,则会使用局部变量(即隐藏全局变量). 示例: x = 1 def func(): x = 2 print x func() print x 运行结果: ...
- 牛客国庆集训派对Day3 B Tree(树形dp + 组合计数)
传送门:https://www.nowcoder.com/acm/contest/203/B 思路及参考:https://blog.csdn.net/u013534123/article/detail ...