Redis缓存策略
常用策略有“求留余数法”和“一致性HASH算法”
redis存储的是key,value键值对
一、求留余数法
使用HASH表数据长度对HASHCODE求余数,余数作为索引,使用该余数,直接设置或访问缓存。
计算key的HashCode
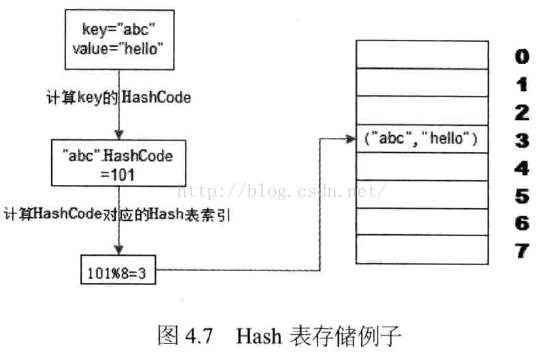
缺点:增加服务器,由于除数不一样了,之前缓存的数据都没办法访问了,即不支持热部署【扩展】
二、一致性HASH算法
一致性HASH算法通过一个叫做一致性HASH环的数据结构,实现KEY到缓存服务器的HASH映射。
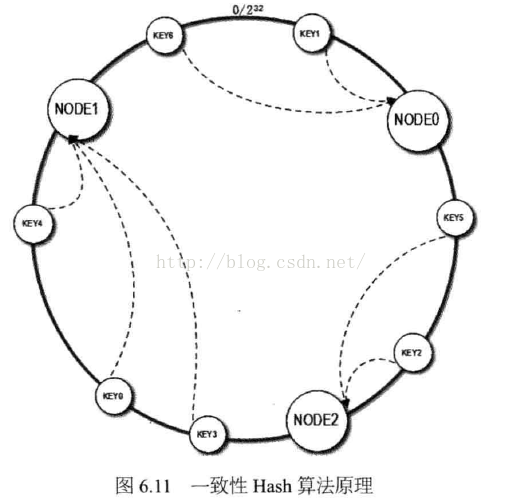
算法过程如下:
先构造一个0到232的整数环,然后将服务器节点的Hash值,放在该环上(可以理解为将你的ip做hash,将ip的HashCode放在环上)。然后根据需要缓存的数据的Key,计算Key的HashCode,然后在环上,顺时针查找距离这个Key的Hash值最近的缓存服务器的节点,然后将Value,存储到该服务器节点上。
这是当缓存服务器集群需要扩容的时候,只需要将新加入的节点的HashCode,放入一致性Hash环中,由于Key是顺时针查找距离最近的节点,因此,新加入的节点只影响整个环中的一小段。
请参见上图,如果我们新加入的服务器节点Node3,在Node1和Node2之间,如下图:
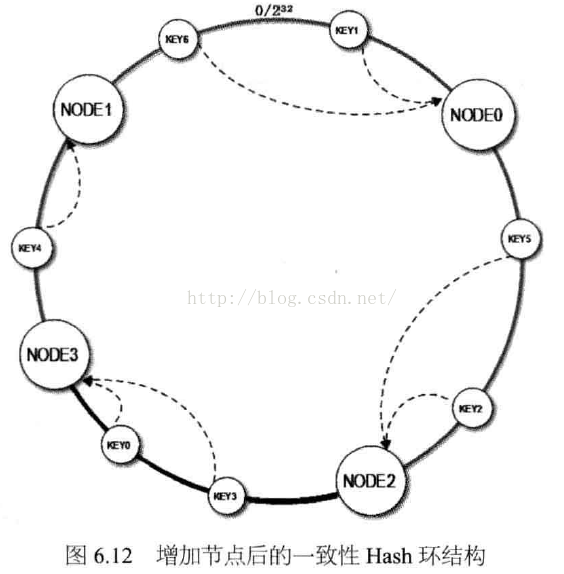
那么受影响的区域,只是Node2到Node3之间(顺时针)的缓存,此区间的缓存数据,加入节点之前是缓存在Node1上的,现在需要重新缓存到Node3上面。
具体应用中,这个长度为232的整数环,通常使用二叉查找树实现,Hash查找过程实际上是在二叉树中查找不小于查找树的最小值。当然,这个二叉树的最右边的叶子节点和最左边的叶子节点相连接,构成环。
通过上面的一致性Hash算法,就解决了分布式缓存集群中扩容的问题。然而上面的方法,仍然有问题。我们已经说过,上面的架构,只影响了Node2到Node3之间的区域(顺时针),那么Node3,也只是分摊了Node1节点的压力,而Node0和Node2的访问压力,并没有变化。也就是说:我们加入了硬件投入,却起到了很小的效果。
一致性Hash算法的进化版
所以说,我们还需要对上面的做法,进行改进。
上述问题是,一致性Hash算法带来的负载均衡不均衡。我们可以通过增加虚拟层来实现。
我们将每台缓存服务器,虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值,放置在Hash环上,Key在环上先找到虚拟服务器节点,再得到物理服务器的信息。
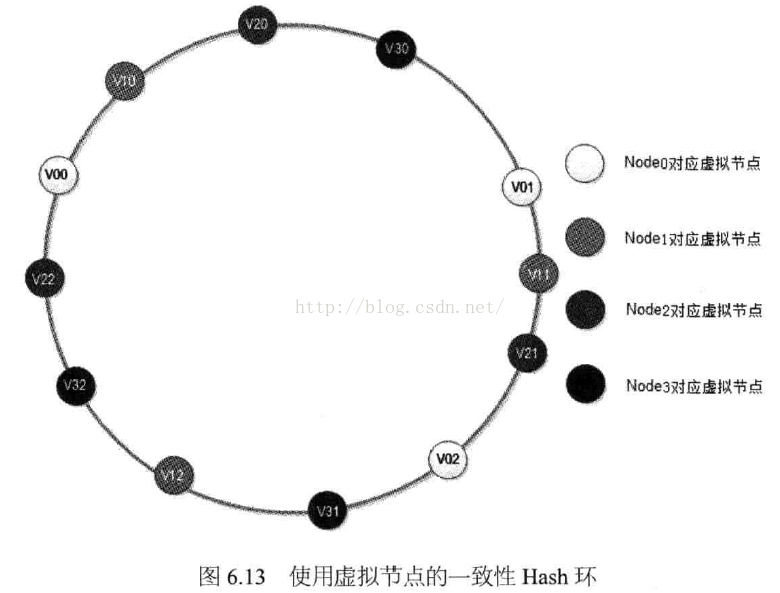
这样,一台服务器节点,被环中多个虚拟节点所代表,且多个节点均匀分配。很显然,每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致。
Redis缓存策略的更多相关文章
- redis 缓存策略
redis 缓存策略配置项:maxmemory <bytes>maxmemory-policy noeviction 触发时机:每次执行命令(processCommand)的时候会检测 w ...
- 转:Redis 缓存策略
转:http://api.crap.cn/index.do#/web/article/detail/web/ARTICLE/7754a002-6400-442d-8dc8-e76e72d948ac 目 ...
- Redis缓存策略设计及常见问题
Redis缓存设计及常见问题 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要.下面会介绍缓存使用技巧和设计方案,包含如下内容:缓存的收益和成本分析.缓存更新策略的选 ...
- mysql+redis缓存策略常见的错误
什么时候应该更新缓存 应该是从数据库读取数据后,再更新缓存,从缓存读取到数据,就不需要再重新写缓存了,一个常见的错误是,每次访问接口都更新缓存,这样的话,如果接口一直有流量,那么db中的数据,就一直没 ...
- 在Window系统中使用Redis缓存策略
Redis是一个用的比较广泛的Key/Value的内存数据库,新浪微博.Github.StackOverflow 等大型应用中都用其作为缓存,Redis的官网为http://redis.io/. 最近 ...
- Redis的缓存策略和主键失效机制
作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略. >>EXPIRE主键失效机制 在Redis当中,有生存期的key被称为volatile,在创建缓存时,要为给定的key设置 ...
- 浅谈一下缓存策略以及memcached 、redis区别
缓存策略三要素:缓存命中率 缓存更新策略 最大缓存容量.衡量一个缓存方案的好坏标准是:缓存命中率.缓存命中率越高,缓存方法设计的越好. 三者之间的关系为:当缓存到达最大的缓存容量时,会触发缓存更 ...
- redis 缓存用户账单策略
最近项目要求分页展示用户账单列表,为提高响应使用redis做缓存,用到的缓存策略和大家分享一下. 需求描述:展示用户账单基本信息以时间倒序排序,筛选条件账单类型(所有,订单收入.提现.充值...). ...
- 缓存策略:redis缓存之springCache
最近通过同学,突然知道服务器的缓存有很多猫腻,这里通过网上查询其他人的资料,进行记录: 缓存策略 比较简单的缓存策略: 1.失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放 ...
随机推荐
- Linux 的 Crond(二)
最近由于工作中用到了crond,之前对crond不是很了解,只知道咋用,但是这次需要考虑好多情况,所以又深入了解了一下crond,下面就以下几个问题来谈谈crond. crond 中指定的job,如果 ...
- windows golang安装golang.org/x/net text grpc
使用git # 吧$GOPATH替换成自己的GOPATH git clone https://github.com/golang/net.git $GOPATH\src\golang.org\x\ne ...
- React中引用CSS样式的方法
相对于html中引用css的三种方法,react中也有三种方法,一一相对: 1. 行内样式:直接在组件内部定义 <div style={{width:'20px',height:'30px'}} ...
- Codeforces Round #602 (Div. 2, based on Technocup 2020 Elimination Round 3) E. Arson In Berland Forest 二分 前缀和
E. Arson In Berland Forest The Berland Forest can be represented as an infinite cell plane. Every ce ...
- Python程序中的进程操作-进程池(multiprocess.Pool)
目录 一.进程池 二.概念介绍--multiprocess.Pool 三.参数用法 四.主要方法 五.其他方法(了解) 六.代码实例--multiprocess.Pool 6.1 同步 6.2 异步 ...
- js 的cookie问题
获取时解码可以用decodeURIComponent(),代替 unescape() // 设置cookiefunction setCookie(name,value) { var Days = 30 ...
- jmeter进行接口测试--csv参数化,数据驱动-转
首先我们要有一个接口测试用例存放的地方,我们这里用EXCEL模板管理,里面包含用例编号.入参.优先级.请求方式.url等等. 1:新建一个txt文件,命名为sjqd,后缀名改为csv,右键excel格 ...
- Delphi 10.2 Tokyo新增JSON类学习——TJsonSerializer
Delphi 10.3.2 for windows 7 编译通过,源码下载地址: Tokyo 10.2新增类,效率更高更快 TJsonSerializer 需要引用单元:System.JSON.Ser ...
- 数据库——SQL-SERVER练习(5) 供应关系
以下题目用到工程供应数据库关系模式:供应商(供应商号,供应商名,城市) S(Sno,Sname,City)零件(零件号,零件名,零件颜色) P(Pno,Pname,Color)工 ...
- MVC过滤器:自定义异常过滤器使用案例
在上一篇文章中讲解了自定义异常过滤器,这篇文章会结合工作中的真实案例讲解一下如何使用自定义异常过滤器. 一.需求 本案例要实现的功能需求:在发生异常时记录日志,日志内容包括发生异常的Controlle ...