python数据库-mongoDB的高级查询操作(55)
一、MongoDB索引
为什么使用索引?
假设有一本书,你想看第六章第六节讲的是什么,你会怎么做,一般人肯定去看目录,找到这一节对应的页数,然后翻到这一页。这就是目录索引,帮助读者快速找到想要的章节。在数据库中,我们也有索引,其目的当然和我们翻书一样,能帮助我们提高查询的效率。索引就像目录一样,减少了计算机工作量,对于表记录较多的数据库来说是非常实用的,可以大大的提高查询的速度。否则的话,如果没有索引,计算机会一条一条的扫描,每一次都要扫描所有的记录,浪费大量的cpu时间。
为了查询方便,我们创建一个拥有500000条数据的一个集合
> for(var i=0;i<500000;i++){db.nums.insert({name:"name"+i,age:i})}
WriteResult({ "nInserted" : 1 })
createIndex() 方法:MongoDB使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
语法:createIndex()方法基本语法格式如下所示:
>db.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
实例:
1、先在未创建索引之前我们按需求查找nums集合里面age为399999的
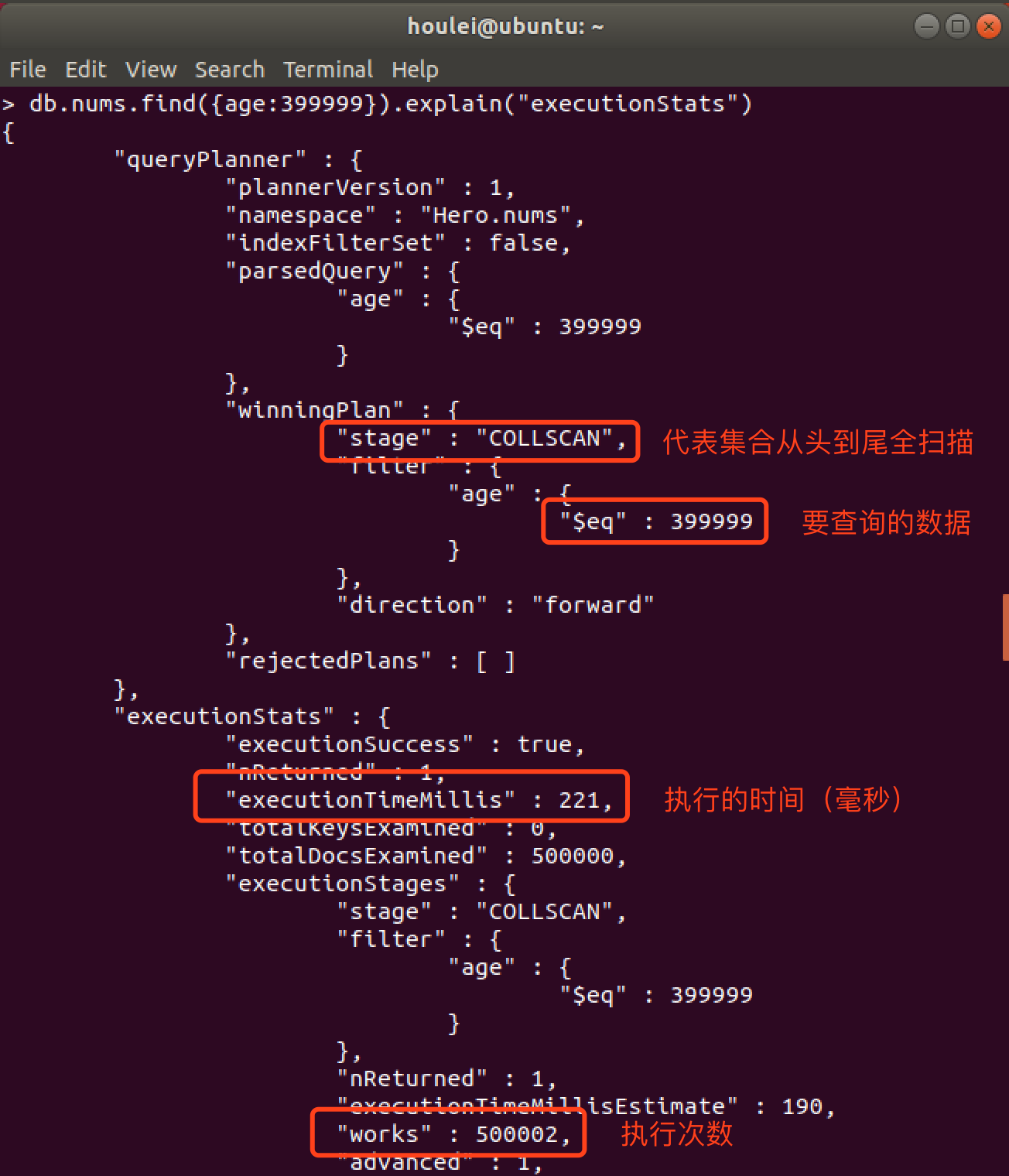
2、在创建索引之后查询age为399999的
创建索引
> db.nums.createIndex({age:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}

通过两次执行时间的对比明显可以看到创建索引后查询更快,数据越多,体现的越明显。
createIndex() 接收可选参数,可选参数列表如下:

二、MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
aggregate() 方法:MongoDB中聚合的方法使用aggregate()。
语法:aggregate() 方法的基本语法格式如下所示:
db.集合名称.aggregate([{管道:{表达式}}])
管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
ps ajx | grep mongo
- 在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
- 常用管道
- $group:将集合中的文档分组,可用于统计结果
- $match:过滤数据,只输出符合条件的文档
- $project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort:将输入文档排序后输出
- $limit:限制聚合管道返回的文档数
- $skip:跳过指定数量的文档,并返回余下的文档
- $unwind:将数组类型的字段进行拆分
- $geoNear:输出接近某一地理位置的有序文档。
表达式:处理输入文档并输出
表达式:'$列名'
常用表达式
- $sum:计算总和,$sum:1同count表示计数
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
三、$group
- 将集合中的文档分组,可用于统计结果
- _id表示分组的依据,使用某个字段的格式为'$字段'
例如:heros表中数据如下
> db.heros.find().pretty()
{
"_id" : ObjectId("5d2e0647614bec7ca4687792"),
"h_name" : "后裔",
"h_skill" : "惩戒之剑",
"h_attack" : 1000,
"h_blood" : 800,
"h_type" : "射手"
}
{
"_id" : ObjectId("5d2e0685614bec7ca4687793"),
"h_name" : "李白",
"h_skill" : "青莲剑仙",
"h_attack" : 1400,
"h_blood" : 900,
"h_type" : "刺客"
}
{
"_id" : ObjectId("5d2e06d6614bec7ca4687794"),
"h_name" : "韩信",
"h_skill" : "国士无双",
"h_attack" : 1300,
"h_blood" : 850,
"h_type" : "刺客"
}
{
"_id" : ObjectId("5d2e0720614bec7ca4687795"),
"h_name" : "妲己",
"h_skill" : "女王崇拜",
"h_attack" : 1200,
"h_blood" : 750,
"h_type" : "法师"
}
例如:按照英雄类型分组,进行统计个数
> db.heros.aggregate([{$group:{_id:"$h_type",counter:{$sum:1}}}])
{ "_id" : "刺客", "counter" : 2 }
{ "_id" : "法师", "counter" : 1 }
{ "_id" : "射手", "counter" : 1 }
>
Group by null:将集合中所有文档分为一组
例如:求英雄的从攻击力和平均血量
> db.heros.aggregate([{$group:{_id:null,h_attacks:{$sum:"$h_attack"},avgh_blood:{$avg:"$h_blood"}}}])
{ "_id" : null, "h_attacks" : 4900, "avgh_blood" : 825 }
>
透视数据
只查询英雄类型和名字
> db.heros.aggregate([{$group:{_id:"$h_type",name:{$push:"$h_name"}}}])
{ "_id" : "刺客", "name" : [ "李白", "韩信" ] }
{ "_id" : "法师", "name" : [ "妲己" ] }
{ "_id" : "射手", "name" : [ "后裔" ] }
>
- 使用$$ROOT可以将文档内容加入到结果集的数组中,代码如下
> db.heros.aggregate([{$group:{_id:"h_type",name:{$push:"$$ROOT"}}}]).pretty()
{
"_id" : "h_type",
"name" : [
{
"_id" : ObjectId("5d2e0647614bec7ca4687792"),
"h_name" : "后裔",
"h_skill" : "惩戒之剑",
"h_attack" : 1000,
"h_blood" : 800,
"h_type" : "射手"
},
{
"_id" : ObjectId("5d2e0685614bec7ca4687793"),
"h_name" : "李白",
"h_skill" : "青莲剑仙",
"h_attack" : 1400,
"h_blood" : 900,
"h_type" : "刺客"
},
{
"_id" : ObjectId("5d2e06d6614bec7ca4687794"),
"h_name" : "韩信",
"h_skill" : "国士无双",
"h_attack" : 1300,
"h_blood" : 850,
"h_type" : "刺客"
},
{
"_id" : ObjectId("5d2e0720614bec7ca4687795"),
"h_name" : "妲己",
"h_skill" : "女王崇拜",
"h_attack" : 1200,
"h_blood" : 750,
"h_type" : "法师"
}
]
}
>
四、$match
- 用于过滤数据,只输出符合条件的文档
- 使用MongoDB的标准查询操作
例如:查询攻击力大于1200
> db.heros.aggregate([{$match:{"h_attack":{$gt:1200}}}])
{ "_id" : ObjectId("5d2e0685614bec7ca4687793"), "h_name" : "李白", "h_skill" : "青莲剑仙", "h_attack" : 1400, "h_blood" : 900, "h_type" : "刺客" }
{ "_id" : ObjectId("5d2e06d6614bec7ca4687794"), "h_name" : "韩信", "h_skill" : "国士无双", "h_attack" : 1300, "h_blood" : 850, "h_type" : "刺客" }
>
五、$project
- 修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- 输出结果和投影效果差不多
> db.heros.aggregate([{$project:{_id:0,h_name:1,h_skill:1}}])
{ "h_name" : "后裔", "h_skill" : "惩戒之剑" }
{ "h_name" : "李白", "h_skill" : "青莲剑仙" }
{ "h_name" : "韩信", "h_skill" : "国士无双" }
{ "h_name" : "妲己", "h_skill" : "女王崇拜" }
>
六、$unwind
- 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法1
对某字段值进行拆分
db.集合名称.aggregate([{$unwind:'$字段名称'}])
例如:
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L']})
查询:
> db.t2.aggregate([{$unwind:'$size'}])
{ "_id" : 1, "item" : "t-shirt", "size" : "S" }
{ "_id" : 1, "item" : "t-shirt", "size" : "M" }
{ "_id" : 1, "item" : "t-shirt", "size" : "L" }
>
语法2
- 对某字段值进行拆分
- 处理空数组、非数组、无字段、null情况
db.inventory.aggregate([{
$unwind:{
path:'$字段名称',
preserveNullAndEmptyArrays:<boolean>#防止数据丢失
}
}])
- 构造数据
db.t3.insert([
{ "_id" : 1, "item" : "a", "size": [ "S", "M", "L"] },
{ "_id" : 2, "item" : "b", "size" : [ ] },
{ "_id" : 3, "item" : "c", "size": "M" },
{ "_id" : 4, "item" : "d" },
{ "_id" : 5, "item" : "e", "size" : null }
])
- 使用语法1查询
> db.t3.find().pretty()
{ "_id" : 1, "item" : "a", "size" : [ "S", "M", "L" ] }
{ "_id" : 2, "item" : "b", "size" : [ ] }
{ "_id" : 3, "item" : "c", "size" : "M" }
{ "_id" : 4, "item" : "d" }
{ "_id" : 5, "item" : "e", "size" : null }
> db.t3.aggregate([{$unwind:'$size'}])
{ "_id" : 1, "item" : "a", "size" : "S" }
{ "_id" : 1, "item" : "a", "size" : "M" }
{ "_id" : 1, "item" : "a", "size" : "L" }
{ "_id" : 3, "item" : "c", "size" : "M" }
>
- 查看查询结果,发现对于空数组、无字段、null的文档,都被丢弃了
使用语法2查询不会丢弃空数组,无字段,null的文档
> db.t3.aggregate([{$unwind:{path:'$sizes',preserveNullAndEmptyArrays:true}}])
{ "_id" : 1, "item" : "a", "size" : [ "S", "M", "L" ] }
{ "_id" : 2, "item" : "b", "size" : [ ] }
{ "_id" : 3, "item" : "c", "size" : "M" }
{ "_id" : 4, "item" : "d" }
{ "_id" : 5, "item" : "e", "size" : null }
>
python数据库-mongoDB的高级查询操作(55)的更多相关文章
- MySQL 高级查询操作
目录 MySQL 高级查询操作 一.预告 二.简单查询 三.显示筛选 四.存储过程 五.查询语句 1.作为变量 2.函数调用 3.写入数据表 备注 附表一 附表二 相关文献 博客提示 MySQL 高级 ...
- python进阶09 MySQL高级查询
python进阶09 MySQL高级查询 一.筛选条件 # 比较运算符 # 等于:= 不等于:!= 或<> 大于:> 小于:< 大于等于>= 小于等于:<= #空: ...
- MySQL/MariaDB数据库的多表查询操作
MySQL/MariaDB数据库的多表查询操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.单表查询小试牛刀 [root@node105.yinzhengjie.org.cn ...
- PHP操作Mongodb之高级查询篇
本文主要讲解PHP中Mongodb的除了增删改查的一些其他操作. 在PHP操作Mongodb之增删改查篇中我们介绍了PHP中Mongodb的增加.删除.修改及查询数据的操作.本文主要是将查询时用到的高 ...
- mongodb的高级查询
db的帮助文档 输入:db.help(); db.AddUser(username,password[, readOnly=false]) 添加用户 db.auth(usrename,passwor ...
- python数据库-MongoDB的安装(53)
一.NoSQL介绍 1.什么是NoSQL NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL". NoSQL,指的是非关系型的数据库.NoSQL有时也称 ...
- java数据库编程之高级查询
第三章:高级查询(-) 3.1:修改表 3.1.1:修改表 语法: Alter table <旧表名> rename [ TO] <新表名>; 例子:Alter table ` ...
- 10-30SQLserver基础--(备份和还原、分离和附加数据库)、语句查询操作
一.数据库是一个大容量的存储数据的仓库,为了保证数据完整性,防止一些数据的意外丢失等情况,需要对数据进行备份和还原. 备份数据不影响数据库的正常运行. 1.备份.还原数据库 首先对数据库进行备份,操作 ...
- MongoDB的使用学习之(六)MongoDB的高级查询之条件操作符
此文分为两点,主要是在第二点--java 语法,但是按顺序必须先把原生态的语法写出来 (还有一篇文章也是不错的:MongoDB高级查询用法大全(包含MongoDB命令语法和Java语法,其实就是我整理 ...
随机推荐
- liunx 查看php 安装的扩展
/usr/local/php5/bin/php -i |less 查看配置文件在哪里,编译参数 /usr/local/php5/bin/php -m |less 查看php加载的模块
- Qt4可以使用trUtf8函数,其内容可以是中文,也可以是\F硬编码
显示在textBrowser->setText 中文乱码 转成QObject::trUtf8即可. ui->textBrowser->setText((QObject::trUtf8 ...
- C#字符类型
C#字符串类型采用Unicode字符集,一个Unicode标准字符长度位16位,它允许用单个编码方案表示世界上使用的所有字符. 字符类型表示位char. 关于字符的转义:C#也可以使用字符转义,用 ...
- NFS服务设置
1.安装NFS服务sudo apt-get install nfs-common nfs-kernel-server 2.配置NFS服务首先需要手动编辑/etc/exports配置文件 权限参数说明如 ...
- ZooKeeper+Dubbo+SpringBoot 微服务Demo搭建
1. 首先创建springBoot项目,springBoot是一堆组件的集合,在pom文件中对需要的组件进行配置.生成如下目录结构 创建test项目,同步在test创建dubbo-api,dubbo- ...
- 直播的本质(创业者应该要从商业模式的右边开始思考,你为用户创造了什么价值?找客户并不难,但要想办法让客户不离不弃;PC端功能的丰富很重要,因为手机版通常只是一个迷你版)
我想稍微给直播这件事浇点冷水. 的确,直播现在越来越火,YouTube凭着良好的基础建设平台前段时间也做起了直播,Facebook Live最近也加入了变脸.预定直播时间和双人录制的功能,更不用说国内 ...
- 【DRP】-完成物料修改页面Servlet和JSP开发
本系列博客内容为:做DRP系统中的常用功能. 该项目采用MVC架构 C(Controller)控制器,主要职责;1.取得表单参数:2.调用业务逻辑:3.转向页面 M(Model)模型,主要职责:1.业 ...
- javaweb各种框架组合案例(二):maven+spring+springMVC+mybatis
1.mybatis是比较新的半自动orm框架,效率也比较高,优点是sql语句的定制,管理与维护,包括优化,缺点是对开发人员的sql功底要求较高,如果比较复杂的查询,表与表之间的关系映射到对象与对象之间 ...
- python算法与数据结构-单链表(38)
一.链表 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括 ...
- 玩转Java多线程(乒乓球比赛)
转载请标明博客的地址 本人博客和github账号,如果对你有帮助请在本人github项目AioSocket上点个star,激励作者对社区贡献 个人博客:https://www.cnblogs.com/ ...