Python之爬虫有感(一)
urllib.request.Request('URL',headers = headers)
User-Agent 是爬虫和反爬虫斗争的第一步,发送请求必须带User—Agent
使用流程:
1、创建请求对象
request = urlllib.request.Request('url'......)
2、发送请求获取响应对象
response = urllib.request.urlopen(request)
3、获取响应内容
html = response.read().deconde('utf-8')
为什么要使用User—Agent呢?如果没有这个就对网页进行爬取,当爬取大量数据短时间大量访问网页那边就会知道你这边是一个程序,就可以进行屏蔽,使用User-Agent能够让那边认为你这边的爬虫是一个浏览器对其进行访问,不会拦截,当然如果就一个User-Agent短时间访问多次也是会被拦截,此时解决问题的方法是使用多个User-Agent,每次访问网页都随机选取一个User-Agent,这样就可以解决该问题。
简单的示例,使用上面的方法爬取百度首页内容:
import urllib.request
url = "https://www.baidu.com/"
headers = {'User-Agent': '自己找一个Uer-Agent'}
#1、创建请求对象
req = urllib.request.Request(url, headers=headers)
#2、获取响应对象
res = urllib.request.urlopen(req)
#3|响应对象read().decode('utf-8')
html = res.read().decode('utf-8')
print(html)
如果要爬取一些复杂的网页,就需要对网页进行分析。
比如说对腾讯招聘进行爬取,首先腾讯招聘网页是一个动态网页,简单方式爬取不了,那我们找到这个网页的json网页如下:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563246818490&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex=0
&pageSize=10&language=zh-cn&area=cn
网页获得的结果是这样的:

这样看起来很难受,所以用一个插件JSON View(chrome浏览器),重新加载后格式为:
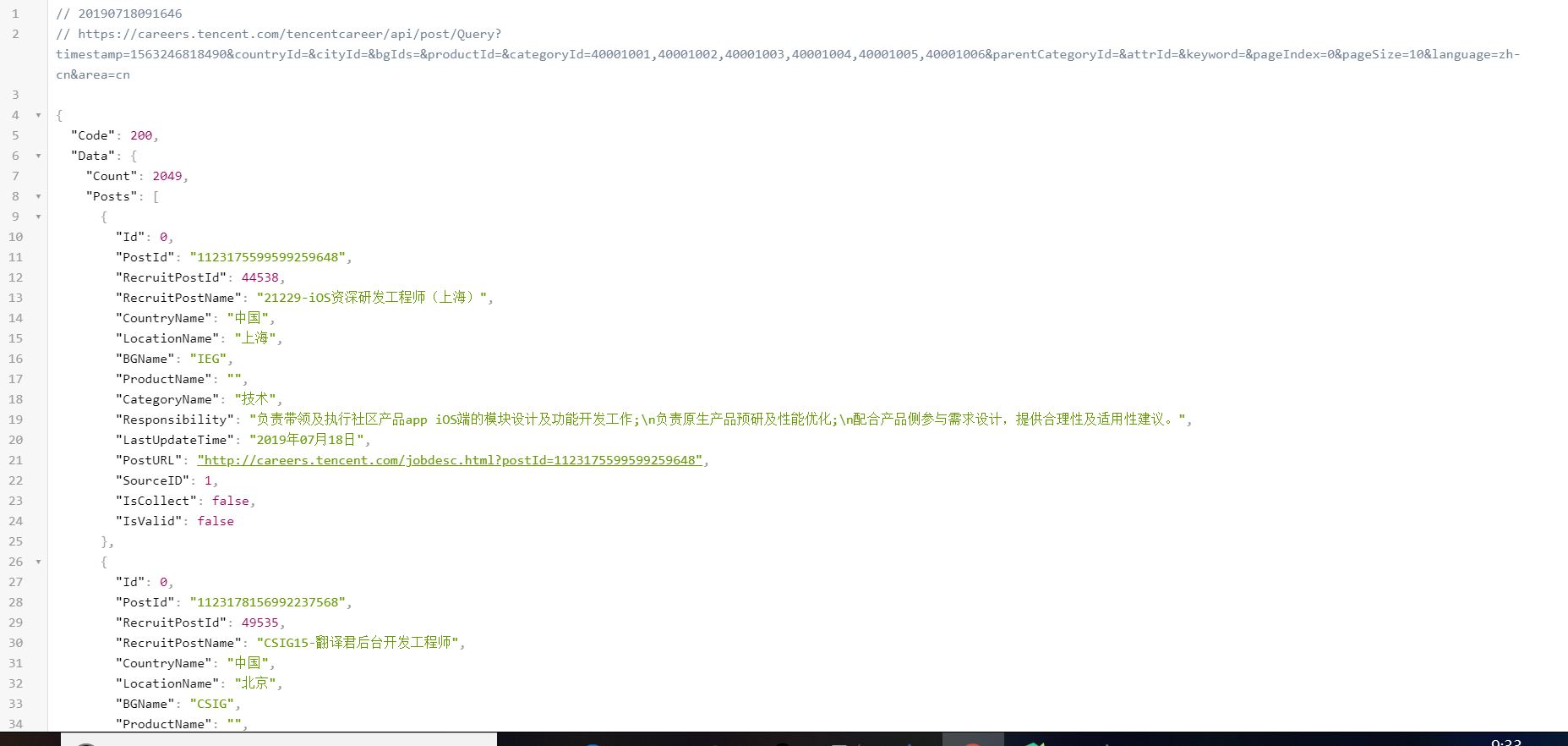
这样看起来就舒服多了,而且都是字典格式以及列表,找到我们想要的数据就更加简单了。
我们可以修改pageIndex这个锚点的值跳转到不同页面,对多个页面进行爬取。
话不多说,直接先上代码:
import urllib.request
import json beginURL = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563246818490&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex='
offset = 0
endURL = '&pageSize=10&language=zh-cn&area=cn'
start_urls = beginURL + str(offset) + endURL
headers = {'User-Agent': '自己找一个User-Agent'} while True:
if offset < 2:
offset += 1
else:
break html = urllib.request.urlopen(start_urls, headers=headers)
result = json.loads(html.read()) position = {}
L = []
for i in range(len(result['Data']['Posts'])):
position['职位名称'] = result['Data']['Posts'][i]['RecruitPostName']
position['最近公布时间'] = result['Data']['Posts'][i]['LastUpdateTime']
position['工作地点'] = result['Data']['Posts'][i]['CountryName'] + result['Data']['Posts'][0]['LocationName']
position['职位内容'] = result['Data']['Posts'][i]['Responsibility']
position['工作链接'] = result['Data']['Posts'][i]['PostURL']
L.append(position) print(L)
with open('TencentJobs.json', 'a', encoding='utf-8') as fp:
json.dump(L, fp, ensure_ascii=False)
我的思路大致是这样的:
首先从一个网页里面爬取到自己想要的数据,将第一个网页加载出来,html = urllib.request.urlopen(start_urls, headers=headers) result = json.loads(html.read()),将start-urls换成第一个网页的url就可以了,通过程序将网页得到的结果放在result里,然后从第一个网页进行分析,发现它里面的内容都是字典还有一个列表,那么通过字典和列表的索引方式找到我们想要的数据。例如,获得职位名称可以使用result['Data']['Posts'][i]['RecruitPostName'],再用一个一个position字典进行保存,后面依次类推。
将所有的字典都保存到一个列表L里面,然后再将L内数据写入到本地json文件中。对于多页面找到了锚点pageIndex,就通过一些手段每次某一页面爬取完就更改pageIndex爬取下一页。本程序通过更改offset的值,原网页应该有203个页面左右,我程序里面只爬取了两个页面,可以自行更改。
好了,如果使用了scrapy框架就会体会到python爬虫是多么的方便了。
Python之爬虫有感(一)的更多相关文章
- Python开发爬虫之理论篇
爬虫简介 爬虫:一段自动抓取互联网信息的程序. 什么意思呢? 互联网是由各种各样的网页组成.每一个网页对应一个URL,而URL的页面上又有很多指向其他页面的URL.这种URL之间相互的指向关系就形成了 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
随机推荐
- Win8 Metro(C#)数字图像处理--4图像颜色空间描述
原文:Win8 Metro(C#)数字图像处理--4图像颜色空间描述 图像颜色空间是图像颜色集合的数学表示,本小节将针对几种常见颜色空间做个简单介绍. /// <summary> / ...
- C语言实现的CRC16/CCITT-FALSE校验码函数
要求:输入字符串“00 AA FF CC AA 01 00” 得到校验码“79B1” 方法1: // ConsoleApplication1.cpp: 定义控制台应用程序的入口点. // #inclu ...
- SQL语法详解
ALTER DATABASE修改数据库全局特性 ALTER DATABASE实际上是修改数据库目录中的dp.opt文件 ALTER TABLE修改表的结构 ALTER TABLE对表进行增删列,创建取 ...
- C# ACCESS 查询提示“至少一个参数没有被指定”问题
错误的SQL指令如下: sqlStr = “select * from tb_userInfo where userName=” + userName; //错误的 sql 指令 正确的SQL ...
- 基于QT的在线打字练习软件助手(C/S模型)good
简介 通过基于QT中QTcpServer和QTcpSocket以及UI编程,实现了基于TCP协议的C/S模型在线打字练习软件助手,服务端处理各客户端打字数据,以及显示在线打字客户列表即实时更新打字 ...
- [每天记录一个Bug]Cell中由于block加载网络请求产生的复用
Bug 出现场景: cell中使用加载图片的网络请求出现复用,截图如下: 复用原因: Cell Model中只有一个用户的uid,所有用户相关信息:例如头像\名称\信息等是通过 ...
- bootstrap组件和插件
一.用node.js读取文件 //引入fs模块 var fs= require ('fs'); // console.log(fs); //调用fs模块的readFile方法 fs.readFile( ...
- 3023Java_控制语句
控制语句 0.前定义 语句块(有时叫做复合语句),是用花括号扩起的任意数量的简单Java语句. 块确定了局部变量的作用域.块中的程序代码,作为一个整体,是要被一起执行的. 块可以被嵌套在另一个块中,但 ...
- 【转+存】JVM指令集
jvm指令集: 转载地址:https://www.cnblogs.com/yaoyinglong/p/4300447.html 一.未归类系列A 此系列暂未归类. 指令码 助记符 ...
- Shell学习笔记2》转载自runnoob
学习且转载地址:http://www.runoob.com/linux/linux-shell-passing-arguments.html 这个网站整理的的确不错,看着很清晰,而且内容也很全面,个人 ...