NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;
为了了解,上来先看几篇中文博客进行简单了解:
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章)
- 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式测试)
- nvidia-nccl 学习笔记 (主要是一些接口介绍)
- https://developer.nvidia.com/nccl (官方网站)
- https://github.com/NVIDIA/nccl (官方仓库)
- https://www.cnblogs.com/xuyaowen/p/heterogeneous-system-architecture.html GPU 相关架构
- https://www.nvidia.cn/data-center/nvlink/ (NVLink)
- https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/overview.html (nccl doc)
内容摘录:
- 通信性能(应该主要侧重延迟)是pcie switch > 同 root complex (一个cpu接几个卡) > 不同root complex(跨cpu 走qpi)。ib的gpu direct rdma比跨cpu要快,所以甚至单机八卡要按cpu分成两组,每组一个switch,下面四个卡,一个ib,不通过cpu的qpi通信,而是通过ib通信。- 摘自评论
- 对于多个GPU卡之间相互通信,硬件层面上的实现有Nvlink、PCIe switch(不经过CPU)、Infiniband、以及PCIe Host Bridge(通常就是借助CPU进行交换)这4种方式。而NCCL是Nvidia在软件层面对这些通信方式的封装。
保持更新,更多内容,请参考cnblogs.com/xuyaowen;
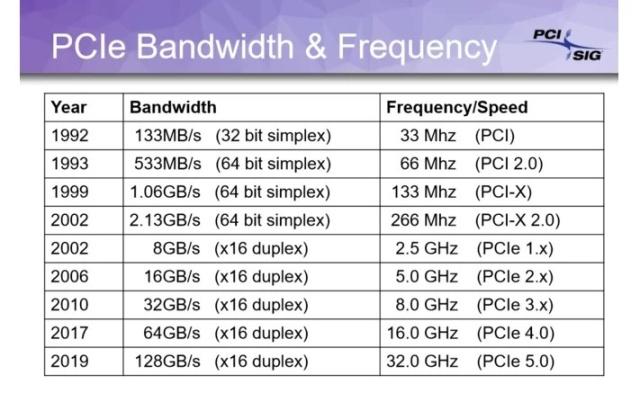
z390 芯片组资料:
https://ark.intel.com/content/www/cn/zh/ark/products/133293/intel-z390-chipset.html
P2P 显卡通信性能测试:
cuda/samples/1_Utilities/p2pBandwidthLatencyTest
nvidia 驱动安装:
https://www.cnblogs.com/xuyaowen/p/nvidia-driver-cuda-installation.html
nccl 编译安装过程:
git clone git@github.com:NVIDIA/nccl.git
cd nccl
make -j src.build (进行编译)
cd build
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/yourname/nccl/build/lib # 添加环境变量;也可以配置环境变量.bashrc;
export C_INCLUDE_PATH=/home/yourname/nccl/build/include (设置 C 头文件路径)
export CPLUS_INCLUDE_PATH=/home/yourname/nccl/build/include (设置C++头文件路径)
测试是否安装成功:
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl (具体编译,可以参考官方文档)
./build/all_reduce_perf -b 8 -e 256M -f 2 -g <ngpus>
才是
NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;的更多相关文章
- 基于英伟达Jetson TX1的GPU处理平台
基于英伟达Jetson TX1 GPU的HDMI图像输入的深度学习套件 [309] 本平台基于英伟达的Jetson TX1视觉计算的全功能开发板,配合本公司研发的HDMI输入图像采集板:Jetson ...
- 英伟达GPU 嵌入式开发平台
英伟达GPU 嵌入式开发平台 1. JETSON TX1 开发者组件 JETSON TX1 开发者组件是视觉计算的全功能 开发平台,旨在让您能够快速地安装和运行. 该组件带有 Lin ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 英伟达GPU虚拟化---申请英伟达测试License
此文基于全新的License 2.0系统,针对vGPU License的试用申请以及软件下载和License管理进行了详细的说明,方便今后我们申请测试License,快速验证GPU的功能. 试用步骤: ...
- Linux查看英伟达GPU信息
命令: nvidia-smi 结果:
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- MLHPC 2018 | Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
这篇文章主要介绍了一个名为Aluminum通信库,在这个库中主要针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 通信何时发生 一 ...
- Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
本文发表在MLHPC 2018上,主要介绍了一个名为Aluminum通信库,这个库针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 ...
- GPU 编程入门到精通(五)之 GPU 程序优化进阶
博主因为工作其中的须要,開始学习 GPU 上面的编程,主要涉及到的是基于 GPU 的深度学习方面的知识.鉴于之前没有接触过 GPU 编程.因此在这里特地学习一下 GPU 上面的编程. 有志同道合的小伙 ...
随机推荐
- 集合系列 Map(十四):WeakedHashMap
WeakedHashMap 也是 Map 集合的哈希实现,但其余 HashMap 的不同之处在于.其每个节点的 value 引用是弱引用,可以方便 GC 回收. public class WeakHa ...
- 数据库性能提升利器—Mycat数据切分
一.前言 数据库是每个系统都不可缺少的东西,里面记录了系统各种数据资料.但是如今的数据膨胀的时代,数据库性能不能满足我们的需要了.所以我们要对数据库进行强化,就用到了Mycat. 二.何为数 ...
- How to: Recompile the Business Class Library 如何:重新编译业务类库
The eXpressApp Framework supplies the Business Class Library that consists of three assemblies. eXpr ...
- apache commons lang架包介绍
commons lang组件介绍和学习 介绍 Java语言开发时有一个隐患,那就是java支持null值,这就导致很多时候操作可能会出异常. 因此很多第三方组件都会提供安全null safe 操作(即 ...
- Go Modules使用教程
Go Modules 不完全教程 文章转载自公众号 Golang 成神之路 , 作者 L Go Modules 是 Golang 官方最近几个版本推出的原生的包管理方式,在此之前,社区也不乏多种包管理 ...
- Data Guard:Oracle 12c –新增和更新的功能 (Doc ID 1558256.1)
Data Guard: Oracle 12c – New and updated Features (Doc ID 1558256.1) APPLIES TO: Oracle Database - E ...
- leetcode-10
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配. '.' 匹配任意单个字符'*' 匹配零个或多个前面的那一个元素所谓匹配,是要涵盖 整个 字符串 s的 ...
- 《Web Development with Go》Mangodb插入struct数据
学习数据持久化. package main import ( "fmt" "log" "time" "gopkg.in/mgo.v ...
- com.mysql.cj.exceptions.DataReadException: Zero date value prohibited
com.mysql.cj.exceptions.DataReadException: Zero date value prohibited at com.mysql.cj.result.SqlTime ...
- MongoDB学习笔记(五、MongoDB存储引擎与索引)
目录: mongoDB存储引擎 mongoDB索引 索引的属性 MongoDB查询优化 mongoDB存储引擎: 目前mongoDB的存储引擎分为三种: 1.WiredTiger存储引擎: a.Con ...