requests---requests上传图片
我们在做接口测试的时候肯定会遇到一些上传图片,然后进行校验,今天我们一起学习通过requests上传图片,查看是否上传成功
抓取上传接口
这里我以百度为例子进行操作,为啥要用百度呢,主要上传文件比较简单不用登录啥的~~~通过fiddler抓取上传图片的接口地址以及请求携带的参数内容
通过下面操作进行选择图片进行上传,然后通过fiddler进行分析接口内容

通过分析抓取的内容,我们可以看到接口地址为:“https://graph.baidu.com/upload”
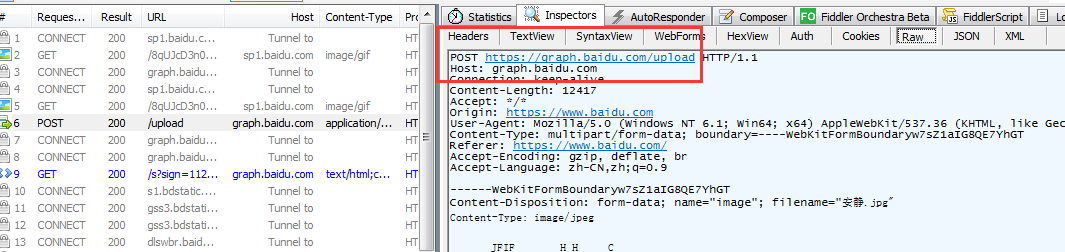
请求的参数类型为from-data,这个类型后面会具体的介绍,这里先不具体说了,这里不影响我们操作

参数格式
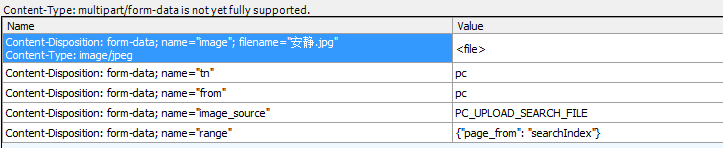
这里在插个知识点,就是requests文档中有对上传文件单独书写,我们可以按照他们的标准进行书写详细的可以进行查看requests官方文档

参数书写情况为:
# 123.jpg为图片,与代码在当前目录下,image/jpeg 为图片格式
files = {
"tn":"pc",
"image":("123.jpg",open('123.jpg','rb'),"image/jpeg"),
"from":"pc",
"image_source":"PC_UPLOAD_SEARCH_FILE",
"range":'{"page_from": "searchIndex"}'
}
请求上传图片
选择图片
# coding:utf-8
import requests
url = "https://graph.baidu.com/upload"
files = {
"tn":"pc",
"image":("123.jpg",open('123.jpg','rb'),"image/jpeg"),
"from":"pc",
"image_source":"PC_UPLOAD_SEARCH_FILE",
"range":'{"page_from": "searchIndex"}'
}
r = requests.post(url,files=files)
print(r.json())
通过查看返回,点击链接进入到百度识图中

但是当我们点击进去后会发现浏览器好像放大了我们的页面一样,这是什么鬼?哪里出错误了吗?
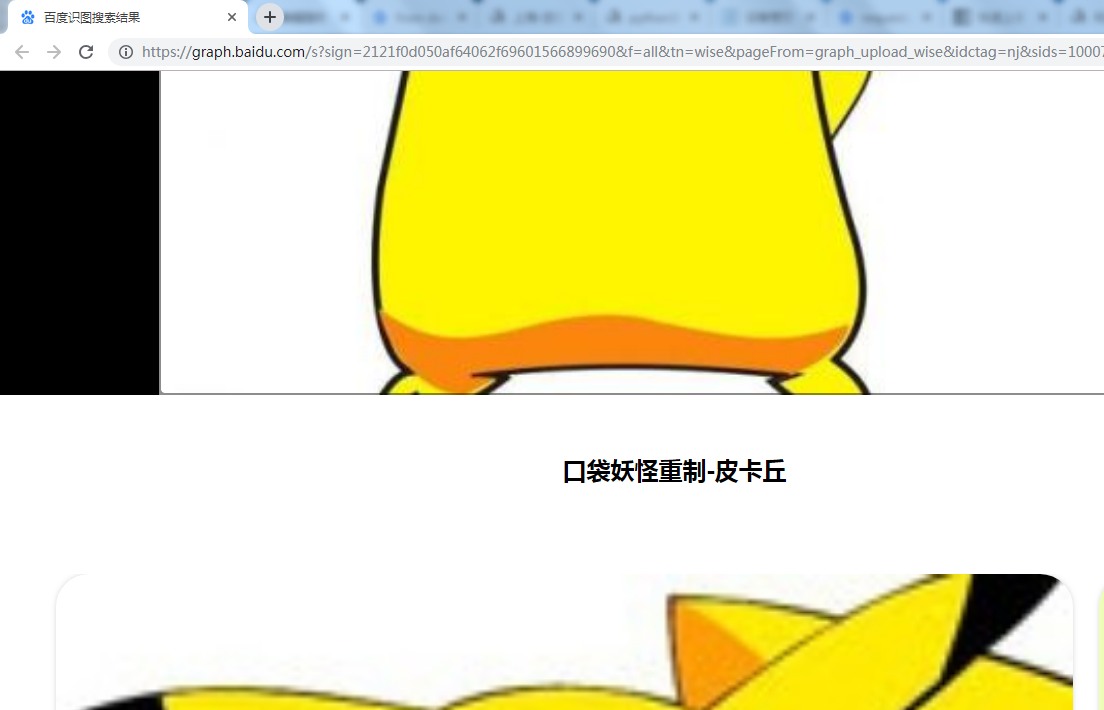
原来是我们在填写数据的时候数据的格式写错了,有一些参数没有添加,我们要表示为None
# 每个value其实都是有2个参数,只是其中一个没有,那么如果我们不穿的话就会出现刚才的问题,这个是需要传None
files = {
"tn":(None,"pc"),
"image":("123.jpg",open('123.jpg','rb'),"image/jpeg"),
"from":(None,"pc"),
"image_source":(None,"PC_UPLOAD_SEARCH_FILE"),
"range":(None,'{"page_from": "searchIndex"}')
}
通过修改后的链接,我们再一次取请求,查看这次的情况,发现是好的,突然感叹到python太强大了~~
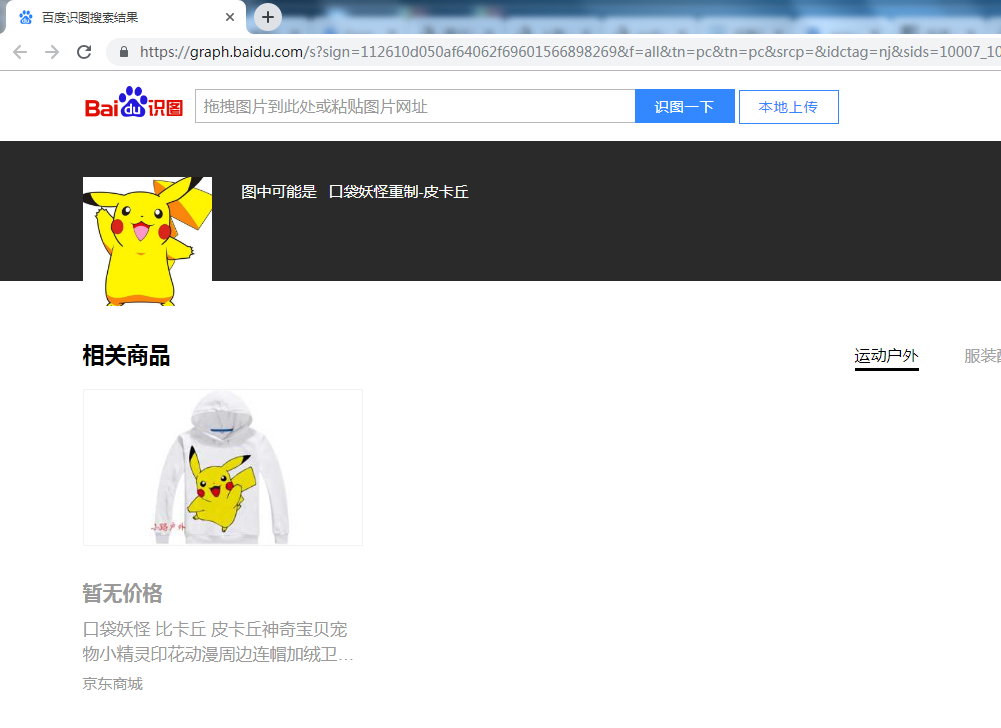
通过一个小的例子,我们学习了如何通过requests发送from-data的数据类型,但是如果想要上传大文件,需要安装第3方库,这个我们下次在一起学习~~~持续更新中~~~
如果感觉写的对您有帮助,可以右下角点击个关注哦~~点关注,不迷路。
requests---requests上传图片的更多相关文章
- Python-第三方库requests详解
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTT ...
- 爬虫requests模块 2
会话对象¶ 会话对象让你能够跨请求保持某些参数.它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能.所 ...
- python Requests模块的简要介绍
Requests的安装: pip install Requests Requests的使用: import requests url = "http://www.mzitu.com" ...
- requests高级用法
会话对象 当你向同一主机发送多个请求时,session会重用底层的tcp连接,从而提升性能,同时session也会为所有请求保持 cookie. # _*_ coding: utf-8 _*_ imp ...
- [转载]Python-第三方库requests详解
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTT ...
- python3使用requests登录人人影视网站
python3使用requests登录人人影视网站 继续练习使用requests登录网站,人人影视有一项功能是签到功能,需要每天登录签到才能升级. 下面的代码python代码实现了使用requests ...
- 转:Python requests 快速入门
迫不及待了吗?本页内容为如何入门Requests提供了很好的指引.其假设你已经安装了Requests.如果还没有, 去 安装 一节看看吧. 首先,确认一下: ·Requests 已安装 ·Reques ...
- Requests:Python HTTP Module学习笔记(二)(转)
在上一篇日志中对Requests做了一个整体的介绍,接来下再介绍一些高级的用法,主要资料还是翻译自官网的文档,如有错漏,欢迎指正. 参考资料:http://docs.python-requests.o ...
- Python Requests模块讲解4
高级用法 会话对象 请求与响应对象 Prepared Requests SSL证书验证 响应体内容工作流 保持活动状态(持久连接) 流式上传 块编码请求 POST Multiple Multipart ...
- Python Requests库:HTTP for Humans
Python标准库中用来处理HTTP的模块是urllib2,不过其中的API太零碎了,requests是更简单更人性化的第三方库. 用pip下载: pip install requests 或者git ...
随机推荐
- HTML DOM属性
innerHTML属性 获取元素内容的最简单方法是使用innerHTML属性 innerHTML属性对于获取或替换HTML元素的内容很有用 innerHTML属性可用于获取或改变任意HTML元素,包括 ...
- VM虚拟机与本地网络互通配置
一.设置虚拟机网络 1. 查看虚拟机网络NAT设置(VMnet8) 2. 设置虚拟机网络适配器为NAT模式 三.设置本机VMnet8网络属性 三.设置Linux网络属性 1. 查看 ip addr 2 ...
- LeetCode 二叉树的锯齿形层次遍历
第103题 给定一个二叉树,返回其节点值的锯齿形层次遍历.(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行). 例如: 给定二叉树 [3,9,20,null,null,15,7] ...
- MySQL 两张表关联更新(用一个表的数据更新另一个表的数据)
有两张表,info1, info2 . info1: info2: 现在,要用info2中的数据更新info1中对应的学生信息,sql语句如下: UPDATE info1 t1 JOIN info2 ...
- 更改Android studio中SDK,AVD的默认路径
对于大部分首次下载android studio开发android的人来说, 由于Android Studio将会默认把SDK,AVD下载到我们的C盘,造成大量内存的占用,那么如何更改SDK,AVD的路 ...
- Centos7 基于SVN+Apache+IF.svnadmin实现web管理
1.简单介绍: iF.SVNAdmin应用程序是您的Subversion授权文件的基于Web的GUI.它基于PHP 5.3,需要安装一个Web服务器(Apache).该应用程序不需要数据库后端或任何类 ...
- Spring学习的第二天
第二天总共学习了以下内容: spring中的ioc常用注解: 案例使用xml方式和注解方式实现单表的CRUD操作(但还是需要xml配置文件,并不是纯注解的配置): 改造基于注解的Ioc案例,使用纯注解 ...
- HttpClient发起Http/Https请求工具类
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpcl ...
- ceph安装笔记
配置源 ceph版本为luminous [root@ceph-node1 ~]# yum install -y https://dl.fedoraproject.org/pub/epel/epel-r ...
- java之this关键字和super关键字的区别
编号 区别点 this super 1 访问属性 访问本类中的属性,如果本类没有此 属性则从父类中继续查找 访问父类中的属性 2 调用方法 访问本类中的方法 直接访问父类中的方法 3 调用构造器 调用 ...