Linux运维基础提高之RAID卡和磁盘分区
磁盘大小计算: 柱面的数量*每个柱面的大小(容量)
[root@luffy001 ~]# fdisk -l
Disk /dev/sda: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders (柱面的数量)
Units = cylinders of 16065 * 512 = 8225280 bytes(柱面的字节数)
echo “”|bc echo “1305*8225280”|bc
使用awk 计算磁盘的容量 awk ‘begin{print 8225280 *1305/1024^3 }’ 磁盘大小计算方法。
RAID卡(磁盘冗余阵列)
软RAID 系统架构及恢复.(节省成本,访问量几百)
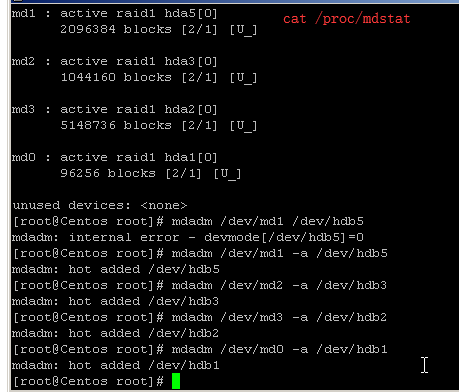
安装系统前可以选择software进行设置.查看软raid配置信息 cat /proc/mdstat
热添加硬盘: mdadm /dev/md1 -a /dev/hdb5
mdadm /dev/md2 -a /dev/hdb3 (根据分区情况来定)
A盘正常,B盘不工作, 系统仍正常运行
A盘停掉,B盘工作,系统不能正常运行, 原因是B盘上没有引导导致.
防止单盘故障, 给两块盘都装grub引导.
grub cat /boot/grub/grub.conf
root (hd0,0)
setup (hd0)
root (hd1,0)
vim /boot/grub/grub.conf
新加盘恢复RAID1
A盘正常,B盘为新加盘,两盘的分区要一样,所以COPYA盘的分区表.(模拟Raid1出故障如何解决)
重组RAID1,使系统在RAID1上更安全.
为防止A盘故障,在新加B盘加Grub引导.
1.导出A盘的分区
sfidisk -d /dev/hda > partition.hda
2.在新盘B上建立和A同样的分区.
sfdisk /dev/hdb < partition.hda
3.查看当前RAID1工作情况(可以发现只有一块盘在工作),
cat /proc/mdstat
4.把新加的B盘加入到RAID1中,恢复RAID1架构.(RAID1做了热备,会自动恢复新加的磁盘的数据)
mdadm /dev/mdx -a /dev/hdbx
恢复完之后,将hda1 的grub信息导入到hdb1中就可以让两块磁盘任意一块故障时系统仍旧可以使用.

RAID系统架构及扩容.
RAID5架构
系统安全( raid)
超大容量 (RAID,LVM)
将来扩容 -(LVM)
组建RAID-5
mdadm --create /dev/md0 --level=5 --raid-devices=3 -c 128 /dev/sda1 /dev/sdb1 /dev/sdc1
cat /proc/mdstat

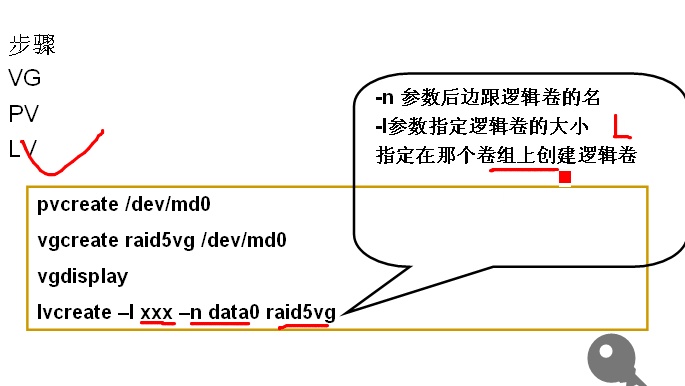
建LVM
先pvcreate /dev/md0
再vgcreate /dev/md0
vgdisplay

恢复Raid5的数据.命令:
新插入一块硬盘sdc 需要先分区,然后再进行添加到raid5中
mdadm /dev/md0 -a /dev/sdc1 然后再查看raid5 的情况. cat /proc/mdstat
mdadm --detail /dev/md0
换磁盘注意事项,不要打乱原来盘的槽位.
raid5 扩容的命令:
mdadm --grow /dev/md0 --raid-devices=4 再查看状态就好了
LV的扩容工作:
pvresize /dev/md0 改变pv大小
删除RAID分区

作用: 获得更高的容量,更强的性能,更强的安全性。
RAID卡/阵列卡。
基础RAID卡 支持的raid级别不同,
高级raid卡 raid卡的缓冲容量不同
常用的raid级别。
最低几块 安全性 可用容量 性能 使用场景 举例
raid 0 1块 安全性最低 所有硬盘容量之和 读写最快 不要求安全,只要速度 数据库从库
raid 1 2块 100% 所有容量的一半 写入速度慢 只追求安全性 系统盘
读取OK
raid 5 3 最多损坏1块 损坏一块盘的容量 写入性能不好 对速度安全要求不高 普通数据库,存储 n(n-1)/n
raid 10 4 可以损坏一半 损失所有硬盘容量一半 读写很快 对于安全和性能都要 数据库主库,存储
raid10 先做raid1 再做单盘raid 0 磁盘有数据镜像,然后raid 0 存储空间.
磁盘分区原理:
主分区1-4 个 最多4个主分区(primary)
扩展分区(extended))5- 逻辑分区(logical)
分区命令规则:
HD硬盘主分区依次为 hda 开始命名
SAS SATA,SCSI 接口硬盘, sda,b,c,d,e,f 等
主分区/扩展分区1-4
逻辑分区 从5开始.
例子:写出下面分区的名字及其含义.
第1块SAS硬盘的第1个主分区 /dev/sda1
第3块硬盘的第2个扩展分区 /dev/sdc6
第4块SATA硬盘的第一个扩展分区 /dev/sdd5
fdisk 命令进行磁盘分区 2T磁盘以下的 --基于MBR分区--主分区表4个
part 进行磁盘分区, 大于2T的磁盘进行磁盘分区和挂载
fdisk -cu /dev/sdb1
fdisk 的参数.
Command action
a toggle a bootable flag 切换可引导标志
b edit bsd disklabel 编辑 bsd disklabel
c toggle the dos compatibility flag 切换dos可兼容性标志
d delete a partition 删除分区
l list known partition types 列出知道得分区类型
m print this menu 打印这个帮助菜单
n add a new partition 添加一个新的分区
o create a new empty DOS partition table 创建一个新的dos分区表
p print the partition table 打印分区表
q quit without saving changes 退出不保存
s create a new empty Sun disklabel 创建一个新的空的磁盘标签
t change a partition's system id 更改分区系统ID
u change display/entry units 更改 展示 entry utils
v verify the partition table 验证分区表
w write table to disk and exit 保存并退出分区表
x extra functionality (experts only) 额外功能(仅限专家)
主分区 (w)保存分区表 ls -l /dev/sdb
扩展分区 extended
逻辑分区 logical
命令:
n 创建新分区,
p 查看当前分区的信息
格式化,创建文件系统
[root@luffy001 ~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
25896 inodes, 103424 blocks
5171 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
13 block groups
8192 blocks per group, 8192 fragments per group
1992 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 29 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
tune2fs -c 0 -i 0 /dev/sdb1
-c count 关闭每挂载多少次进行磁盘检查的功能
-i 0 interval 关闭每180天进行磁盘检查功能
进行永久挂载....
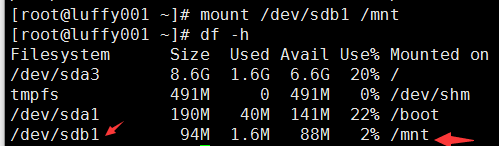
mount /dev/sdb1 /mnt (挂载之前 df -h 检查挂载点是否可用) 这种挂载,在重启后会消失挂载的分区.
永久挂载的方法:
方法1: /etc/rc.local
/bin/mount /dev/sdb1 /mnt
方法2: 写入挂载的分区和挂载点到文件/etc/fstab .系统开机时会自动挂载.
UUID=1d3ad35b-516b-4582-b5e8-6fedb39df41c / ext4 defaults 1 1
UUID=717a49d6-b9f2-4792-a6d6-b7794fb2f276 /boot ext4 defaults 1 2
UUID=e7367797-9805-42c4-843c-b4ec46658d1c swap swap defaults 0 0
uuid 设备名称 挂载点 磁盘分区类型 默认参数 是否备份 是否进行磁盘检查.(0)
man fstab 信息查看
小结:
1.创建分区,并通知系统磁盘分区表变化 (fdisk partprobe /dev/sdb)
2.格式化创建文件系统,并关闭磁盘检查(inode, block) mkfs.ext4 /dev/sdb1 tune2fs -c 0 -i 0 /dev/sdb1
3.挂载开机自动挂载创建的分区 (开机自动挂载vim /etc/fstab) umount /mnt 直接卸载挂载点 df -h
parted 命令. 和fdisk 区别(小于2T)---基于GPT分区表()1ZB = 1024EB=1024*1024PB=1024^3 TB
52-mbr与gpt区别-parted进行磁盘分区流程:
mklabel mktable 创建磁盘分区表,
mkdos (mbr)
mkpart 创建分区
rm 删除分区
q 退出不保存
parted命令是实时的不用保存的
Linux运维基础提高之RAID卡和磁盘分区的更多相关文章
- 第一阶段·Linux运维基础-第1章·Linux基础及入门介绍
01-课程介绍-学习流程 02-服务器硬件-详解 03-服务器核心硬件-服务器型号-电源-CPU 01-课程介绍-学习流程 1.1. 光看不练,等于白干: 1.2 不看光练,思想怠慢: 1.3 即看又 ...
- linux运维基础知识
linux运维基础知识大全 一,序言 每一个微不足道的知识,也是未来的铺垫.每一份工作的薪资职位,也是曾经努力的结果. 二,服务器 1,运维人员工作职责: 1)保证数据不丢失:2)保证服务器24小时运 ...
- Linux运维基础采集项
1. Linux运维基础采集项 做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑.所以,依靠强大的监控系统,收集尽可能多的指标,意义重大.但哪些指标才是有意义的呢,本着从实践中来的思想,各位工 ...
- linux运维基础__争取十月前研究的差不多
转来的一编,考虑在十月前研究的差不多 linux运维人员基础 1.很多地方经常会用到的rsync工具 实施几台服务器的同步效果 我们公司就是使用这个工具完成服务器的游戏的服务端和客户端同步,有几个文章 ...
- 网络配置——Linux运维基础
今天把Linux的网络配置总结了一下,尽管并不难可是是个比較重要的基础.然后我也不知到自己以后是否会做运维,可是我知道自己比較喜欢刨根问底.还有就是我很珍惜我以前掌握过的这些运维的技能.今天突然间问自 ...
- [转帖] Linux运维基础知识学习内容
原作者地址:https://www.cnblogs.com/chenshoubiao/p/4793487.html 最近在学习 linux 对简单的命令有所掌握 但是 复杂的脚本 shell pyt ...
- Linux运维基础
一.服务器硬件 二.Linux的发展史 三.Linux的系统安装和配置 四.Xshell的安装和优化 五.远程连接排错 六.Linux命令初识 七.Linux系统初识与优化 八.Linux目录结构 九 ...
- Linux运维基础命令笔试题--看看你会多少?
老男孩教育linux运维就业班第一周课后学习效果能力上机大考察 (每题10分共130分,过100即可,请给出详细步骤) 1.创建目录/data/oldboy ,并且在该目录下创建文件oldboy.tx ...
- linux运维基础之跟我一起学正则表达式(一)
正则表达式 ### 二, 1) 什么是正则表达式 正则表达式又称为规则表达式 正则表达式是一个计算机的一个概念 正则表达式为了处理大量的文本|字符串而定义的一套规则和方法,通常被用来检索,替换那些符合 ...
随机推荐
- 后端小白的VUE入门笔记, 进阶篇
使用 vue-cli( 脚手架) 搭建项目 基于vue-cli 创建一个模板项目 通过 npm root -g 可以查看vue全局安装目录,进而知道自己有没有安装vue-cli 如果没有安装的话,使用 ...
- 【游记】NOIP2018复赛
声明 我的游记是一个完整的体系,如果没有阅读过往届文章,阅读可能会受到障碍. ~~~上一篇游记的传送门~~~ 前言 参加完NOIP2018的初赛过后,我有点自信心爆棚,并比之前更重视了一点(也仅仅是一 ...
- java并发编程(二十一)----(JUC集合)CopyOnWriteArraySet和ConcurrentSkipListSet介绍
这一节我们来接着介绍JUC集合:CopyOnWriteArraySet和ConcurrentSkipListSet.从名字上来看我们知道CopyOnWriteArraySet与上一节讲到的CopyOn ...
- charles(version4.2.1)抓包手机数据
点击菜单栏的Proxy项,选择Proxy Settings. 设置HTTP Proxy的Port. 勾选透明代理Enable transparent HTTP proxying,也可不勾选. 设置代理 ...
- 分析android studio的项目结构
以最简单的工程为例子,工程名为随意乱打的Exp5,新建好工程后将项目结构模式换成android: 1.manifests AndroidManifest.xml:APP的配置信息 <?xml v ...
- windows如何访问wsl系统下的文件
windows如何访问wsl系统下的文件 可以在wsl终端输入以下命令 explorer.exe . 会出现如下界面 这样就可以很方便的查看wsl的文件了
- vscode 支持 threejs 的智能提示
VSCode Typings and Intellisense: Dummy Learning VS-Code 1 Jun 20, 2016 Updated on Jun 20 2016 for 1. ...
- php Basic HTTP与Digest HTTP 应用
Basic HTTP 认证范例 <?php //Basic HTTP 认证 if (!isset($_SERVER['PHP_AUTH_USER'])) { header('WWW-Authen ...
- Sqlserver 锁表查询代码记录
--方法1WITH CTE_SID ( BSID, SID, sql_handle ) AS ( SELECT blocking_session_id , session_id , sql_handl ...
- Ubuntu Server : 自动更新
Ubuntu(16.04/18.04) 默认会每天自动安装系统的安全更新,但是不会自动安装包的更新.本文梳理 Ubuntu 16.04/18.04 系统的自动更新机制,并介绍如何配置系统自动更新所有的 ...